I just noticed that Mel Brooks turned 100 a day or so ago (in the timezone he’s most likely in).
Wow! A Centenarian! I’m so happy he got there! Woo! Congratulations!
(Obligatory link to Spaceballs: The Bash Script)
I just noticed that Mel Brooks turned 100 a day or so ago (in the timezone he’s most likely in).
Wow! A Centenarian! I’m so happy he got there! Woo! Congratulations!
(Obligatory link to Spaceballs: The Bash Script)
I saw an article today saying that GTA6 has opened for preorders, and that it costs like $100. And presumably that’s USD, so in australia it’ll probably be more like $120. And that’s before you start getting into premium editions that include extra hats. Oh, and the “physical copy” doesn’t actually include a disc, just a download code that will stop working at some date that isn’t written down anywhere.
Having seen this, I’d just like to make a couple of PSAs:
I should probably start by noting that there are – extremely rare – exceptions to both of these rules. For example:
But these are very rare exceptions, and in the vast majority of cases, the rules hold true. You should absolutely never under any circumstances pre-order a AAA game. And you should absolutely under no circumstances ever pay $100 for a AAA game.
Maybe it’s fair to change “game” to “AAA game” in the rules above.
“But”, i hear you say, “I need GTA6! And if I don’t pre-order I won’t have it on release day! And all my friends will laugh at me!”
Wow. Such hardship. I feel your pain.
No, really, I do. I’d really love to play Civilisation 7. And it even supports Linux – they’re one of the few who haven’t dropped Linux support in favour of not really supporting proton. So I’d really like to give them my money. But I’m not paying $120 for a game. Not for any game, ever.
Once upon a time, I was pretty keen to play Borderlands: The Pre-Sequel. And it even supports Linux, so I’d like to give them my money. But it’s still listed at $60 for the base game without any of the DLC and expansions – i.e not the whole game. So I haven’t bought it yet. Maybe in another 10 years.
I fell for the trap once, a long time ago. There was a game that I waited, and waited, and waited for. A game that was going to change the world with it’s revolutionary approach to FPS gaming. That was going to be super-super interactive – one quote I recall was “you can play with everything”. And packed to the gills with humour and an awesome storyline about an old villain coming back for revenge on our hero. So when it finally came out, I pre-ordered the deluxe edition, and paid $120 for Duke Nukem Forever.
I was setting myself up for disappointment. By this point I had come to accept that there was no way the game could possibly be worth the wait – no game is that good. But… like… it would still be good, right?
Yeah, nah.
You should never, ever, ever pay that sort of money for a game that you haven’t already put at least 100 hours into. If you don’t know that it’s an amazing gaming experience then you don’t know that it’s worth that kind of cash.
I don’t care how much the billion dollar studio spent making it. That’s their problem.
If you spend that kind of money on a game, you’re normalising the practice of charging outrageous prices for games. And they’ll just charge you more for the next game.
If you pre-order a game, there’s no incentive for them to make it good. They already have your money.
There is an embarrassment of riches out there when it comes to games these days. Lots of them are super-affordable. And games always go on sale and get cheaper as they age. The ones that don’t, you shouldn’t buy, because they’re a rip-off. See also: Borderlands: The Pre-Sequel.
An interesting thing about Borderlands: The Pre-Sequel is that when it came out, I had just played and liked Borderlands 2, so I was keen to play it. But I held out because I’m not buying an incomplete game, and I’m not spending $70 on a game. I would maybe have paid $30 or perhaps even $35 for a complete edition with all expansions/dlc. But as time has gone by and this price/edition has not materialised, my interest in it has waned. Now I might consider paying $20 for it.
But as I was saying, there’s an embarrassment of riches out there when it comes to seriously amazing and very affordable games. For instance, you can buy Deus Ex, the greatest game ever made, on sale on GOG right now for $5.25, or on the humble store on a not-sale price of $10.45. This is a game I’ve put at least 200 hours into over the decades. Alternatively, you can buy what I think it probably the second-greatest game ever made, Kerbal Space Program, on sale on GOG for $14.99. Admittedly this one does have a non-sale price of $60, and there are two expansion packs which are about $6 each, so that’s at the pricey end of the spectrum – but I did call it the second-greatest game ever made. And in terms of hours it might be first, I’ve got at least 1000 hours of play time in KSP.
The trick with games like that is to add them to your wishlist and wait till they come up on sale at a reasonable price.
Play other games instead while you wait. This is very not difficult to achieve – I’ve got over 100 games in my steam library which I’ve never played. I pick them up when they’re cheap and if I think I’ll like the look of them. Some of them have been really amazing and huge time sinks. Super Hexagon is a great example of this, it’s currently on sale on GOG for $1, and it’s non-sale price on humble store is $4.50. Given the chance I’d pay $10 for super hexagon today and consider that a bargain. But I don’t have to because I bought it on sale a decade ago for like $2. There’s also widely-recognised classics out there for cheap these days: KOTOR 1 and 2 are on sale on GOG at the moment for $5.25 each.
(Disclosure: None of the above are affiliate links. I get nothing if you buy these games except perhaps a new multiplayer opponent and some smug self-satisfaction knowing I’ve deprived rockstar of $120)
(Note also: This is not an ad for GOG, or the humble store. My only recommendation is that you don’t buy things on steam. There’s excellent cheap games available in a bunch of places: itch.io has lots, and zoom-platform.com has tons of awesome, affordable games, too. It’s also the the only place you can get a good copy of Duke3D with Linux support these days, since gearbox decided to remove the excellent Megaton edition from steam and replace it with their worse version. And I’m sure I’ll think of 3 other great stores where you can get good games cheap as soon as I hit “post”)
And that’s before we start getting into free and open source games. And there’s heaps of those that are really excellent. I’m going to give a shout-out here to teeworlds, which I’ve posted about before.
If you’d like me to recommend about a hundred other seriously fantastic games that can be had for much less than $20, let me know, and I’ll write up a list for you. It’ll be long enough that you won’t have any shortage of games to play while you’re waiting for GTA6 to go on sale.
There’s a heap of little side-benefits that you get from taking my approach to games:
As someone who was super into the whole thing two decades ago, I can tell you unequivocably that this is a superior approach to playing games. Do it on your schedule, when you want to, at your budget. Don’t let some marketer at epic or rockstar or valve tell you how to play games, do it on your own terms.
“But my terms are to play the latest thing today!”
You’ve just been conditioned to think like that. Grow out of it. I did. And it was the best thing that ever happened for me WRT gaming. I enjoy it much more now than I ever did when I was on the hype train.
And, frankly, games were better when I was on the hype train, IMO. They were less shit, and less marred by shitty business practices: When you bought a game, you got the whole game. Imagine that. And none of them ever asked me for $1.99 for a new costume. And all those games? They all still work today if I slap the disc into my machine and install them. But also I think there was more innovation, or something. Those games were more fun and appealing to me. Maybe that’s just me being an old man. I bought hardware to play Unreal back in the day. But I actually think Unreal was probably more worth buying hardware for than anything that has come out in the last ~10 years. There might be exceptions to that, but they’re rare IMO.
TLDR: Don’t play the game of the game-makers. Fuck them. They’re almost universally toxic and they’re just trying to rape you and squeeze every dollar they can out of you, while delivering two-thirds of a substandard product. Don’t pre-order games, and don’t pay the outrageous prices that they’re trying to normalise. If you don’t do it, they’ll have to readjust and be more reasonable.
Play games on your terms, not theirs.
Today being the winter1 solstice. I found myself explaining exactly what the solstices are, and how the earth’s inclination changes relative to the sun. During the course of this, I threw together a Celestia script to show earth from the sun’s perspective over the course of a year in one-day intervals in order to illustrate how the poles move relative to the sun. I thought maybe somebody else might find it useful.
This animation shows earth from the sun’s perspective over the course of a year, with the solstices and equinoxes noted.
The important thing to understand is that earth’s axial tilt doesn’t actually ever change2. The north and south celestial poles are fixed2 points in the sky, they don’t move over the course of a year. The inclination of the poles only changes from the Sun’s perspective because earth orbits around it, which means that on the summer solstice the south pole1 is pointed towards the sun and on the winter solstice the north pole1 is pointed towards the sun. But the north pole (and the big arrow in the animation) is always pointing at the star Polaris, and the south pole always points at the south celestial pole – a spot roughly in the center of a triangle defined by the two magellanic clouds and alpha centauri. At the summer solstice this animation is looking in exactly the opposite direction as it was at the winter solstice. This is why the background stars rotate – we’re tracking earth from the sun’s perspective and it’s rotating around the sun.
I’ve also done a variation which shows the earth’s rotation on the equinoxes and solstices:
1 Herp derp, if you’re in the northern hemisphere it’s the other way around, and the winter solstice is in December, and the summer solstice in June. This is written from the pespective of the southern (aka correct) hemisphere. Deal with it. I do, all the time.
2 OK, nerds, fine, yes – earth’s axial tilt has precession and the earth’s poles do actually change where they’re pointed – over long periods of time, but these timescales are measured in thousands of years, and are not relevant to what we’re talking about in the scale of a human lifetime – it’s totally fair for a human to say that the north pole always points in the same direction, with an implicit “within my lifetime” tacked on the end.
Recently we lost a titan of video game music. The man who composed some of the most iconic pieces of video game music of all time.
Is “At Doom’s Gate” the most iconic video game music of all time? I feel like it just might be. I can’t think of many serious competitors. It’s certainly Iconic enough that I have previously spent hours retracking it:
Another of my favourite pieces of Bobby’s work is “waterworld”, from Duke Nukem 3D. Lots of his music from Duke3d is iconic, too, but waterworld is a standout for me. I took the time to retrack that years ago, too:
Bobby created many, many amazing musical pieces and sound effects for a huge number of groundbreaking and super-influential games. As the composer for Wolfenstein 3D, Doom, and Doom II, it’s fair to say that he is essentially the father of the sound in the FPS genre.
Finally I’ll leave you with MazeDude’s awesome remix of Bobby’s “Wondering About My loved Ones” from Wolf3D. This has been in semi-regular rotation for me for about 20 years now:
Bobby made a massive dent in video game music. I personally have spent hundreds of hours – at least – listening to his work. He was 81. RIP.
The question of why the Eagles didn’t just fly Frodo to Mount Doom has been raised repeatedly for decades.
Luckily, the following exchange from the recently-leaked White Council emails finally gives us the definitive answer to the question:
From: Gwaihir The Windlord <windlord@eagles.net>
To: Gandalf The Grey <gandalf@whitecouncil.org>
Sent: 09:17:46 24/10/3018TA
Subject: Re: Your Assistance
Gandalf,
I think you have the wrong idea about eagles. Perhaps you missed the “Eagles are a proud race” bit? I think you should do your own dirty-work for a change.
While it is true that you once healed me of an arrow wound, this does not mean that the eagles are forever indebted to you, or that we are your personal transportation system who only exist to carry you and whatever bunch of misfits you’ve associated yourself with this week wherever you like. It’s been barely a month since I rescued you from that whole “imprisoned at the top of orthanc” situation you found yourself in, and already you’re asking me for another favour? The nerve!
In my book, the debt for the healing of the arrow wound (which may not have even been a mortal wound) was paid when I rescued you and fourteen of your companions from the wargs and goblins. Even if my life was worth five dwarves, I’ve still paid the debt three times over. Even so, out of goodwill, I also saw fit to have you and your companions carried to the carrock. I see now that this was a mistake on my part. You asked us to take you “as far east as you will”, and we took you about half an hour out of our way. What makes you think that I would be willing to send my eagles hundreds of leagues into enemy territory?
To clarify the situation somewhat: when you came across me with that arrow wound, I had already sent two of my eagles off to find Radagast, who would have healed me and expected nothing in return. You offered to heal me and I accepted. I did not expect that this would mean that you would suddenly think I was in your debt forever, or i would have refused and waited. You never mentioned any Life Debt, or I would have told you to piss off. For the record, Radagast arrived on the scene less than 4 hours later, and was more than a little miffed that he had been called away from his work for what turned out to be nothing – to this day he still thinks it was a prank – he brings it up every time he asks for a favour (which usually are more along the lines of “can you pick up this rare herb from high in the mountains for me?”, and don’t tend to involve carrying his companion-of-the-week into the heart of the enemy’s domain).
Setting aside all these concerns, I hardly think that the Dark Lord is going to fail to notice a bunch of giant eagles flying into his territory. If you want to get into mordor, stealth is a better option. And it’s not like we’re invincible – just because we haven’t seen any huge flying beasts circling mordor doesn’t mean he doesn’t have any – maybe he’s keeping his best weapons in reserve. Hell, he could have his own personal dragon guard stationed at Mount Doom for all we know. And even if he doesn’t have any servants capable of flight, I do know for a fact that he has a whole bunch of arrows, and plenty of orcs and men more than willing to fire them. If we were to be shot down, how do you think your ringbearer will fare marooned in the midle of mordor surrounded by enemy armies with no food or provisions and fifteen broken bones from a 10,000 foot fall?
TL;DR: go fuck yourself. The eagles don’t work for you. If I ever find you stranded, naked and dazed, at the top of a mountain, I just might leave you there. Asshole.
-Gwaihir
I’ve been saying “For Teh Securitah!” to describe/mock this phenomenon since at least 2017, when Firefox 57 came out and dropped support for a large percentage of its extension ecosystem.
But a youtuber named suckerpunch / tom7 has come up with a label for it, which I absolutely adore:
“Toxic Max Security”
I hope it catches on just like “enshittification” has. Let’s make that happen.
I have two videos I’d like to share today. First is suckerpinch’s latest masterpiece of hackery, where he coins this term while a) totally undermining SSL and b) ensuring his website still has the green padlock (because a green padlock is what’s important, you see):
(aside: suckerpinch has a few really great videos. I’ve been watching his stuff for ages. I especially recommend the “reverse emulating the NES” one)
…Which reminded me of this talk I watched a while back, which goes over a bunch of examples of Toxic Max Security and some of the problems caused by this dogma:
(This video also contains one of the sickest burns of all time, at ~20:41: “Rust was intented to be used to win arguments against C, whereas C was intended to produce software”)
And here are a couple of my pet peeves, antipatterns, and anecdotes around Toxic Max Security, in no particular order:
Software refusing to do things like connect to servers which only support old versions of encryption protocols / keys / etc, sometimes with no “proceed anyway” button. I’ve seen this in a few places, including in places where you’d expect the devs to know better, like ssh (which does have an option to enable older protocols, but it’s hidden in a config file rather than “do you want to proceed anyway (y/N)?”).
It is an antipattern when software developers assume they know better than users what the risks are and whether they’re OK to accept. It’s not a problem to use an old encryption protocol if I’m connecting to the machine over a LAN or VPN and it’s not publicly accessible
Here’s a great example of a toxic-max-security-bro chastising me for the crime of running software that’s three whole years old :gasp:. He proceeds to label it “very dangerous” and tells me that there are “there are at least five actively exploited vulnerabilities in the chromium engine that you’re vulnerable to”.
It may be worth noting that this is after I have already said that I’ve looked at the CVE list and determined that none of them affect me.
In the message after the one I linked to, you’ll see that I ask for more detail than none at all on exactly why/how it’s “very dangerous”, and pointing out that I’ve looked at the CVE list but didn’t see any that affect me, but conceding that maybe I missed something.
And if you scroll down to the message after that, you’ll see that rather than respond to my questions asking for >0 detail on what exactly is “very dangerous”, the person who made that claim simply labels my request for >0 information as “the boring parts” of my message, moves on, and makes no attempt whatsoever to respond to my questions.
For extra bonus points, if you keep reading, you’ll note that finally he deigns to actually investigate the issue because his fearmongering didn’t work, and quickly determines that the issue had nothing to do with my criminal browser version, but was actually with the user agent switcher extension I was using (and which I mentioned that I use in my second message, because I thought it might be the problem). Upgrading my browser would not have solved the issue, and once they bothered to actually investigate, the anubis people realised that there was an issue with the way they were doing things, and made a change to accommodate this situation. The whole “Very dangerous” thing that took up what felt like 700 messages and garnered me like a hundred “thumbs down” emojis? Completely unrelated to the issue I raised, instead it was a thing I mentioned in my second message that was ignored because “Teh Securitah!”.
Using “teh securitah!” as a catch-all panacea to create busy-work for users and to avoid investigating issues is an antipattern.
(For the record, the actual maintainer/owner of anubis, Xe, was very nice, and did not engage in this conduct – It’s not everyone, just most of the cargo cult)
Share Tom’s video! And for a more serious approach, share Eskil’s talk! Let’s see if we can get “Toxic Max Security” into the lexicon, like it deserves to be!
Yay! And only 50 years late! Go Artemis II!

I just happened to come across the two best javascript libraries that exist, so I wanted to share them:
(no, despite the names, these are not mirrors of the entire npm repo)
In related news, I just learned that npm is owned by githubMicrosoft. As if I didn’t have enough reason to not want to touch that trash.
A line that has been in my bash profile for well over 15 years:
alias chuck_norris_says=sudo
I haven’t thought about Afroman in 25 years. But something recently reminded me that he exists, so I just thought I’d take a moment to congratulate him on his win against officers Streisand, Streisand, Streisand, Streisand, Streisand, Streisand, and Streisand.
Also, damn, that USA Flag suit is resplendent. And the sunglasses are just 

To be a true poet is to become God.
I tried to explain this to my friends on Heaven’s Gate.
‘Piss, shit,’ I said. ‘Asshole motherfucker, goddamn shit goddamn. Cunt. Pee-pee cunt. Goddamn!’
They shook their heads and smiled, and walked away.
Great poets are rarely understood in their own day.
I just realised that it’s a public holiday over there today. And I thought to myself about how we would have spent the day together
But pretty quickly I realised that saying something like that would be dishonest, wouldn’t it?
A more accurate way of putting it might be something along the lines of:
“Today you might have woken up in my arms. But there’s also statistically a ~20-30% chance that I would have woken up to you screaming abuse at me yet again, maybe calling me a faggot again, or perhaps ranting yet again about how you ‘fucking hate indians’ because ‘they’re all so racist’, or maybe you’d fall back on the the good old classic ‘I wish I had died’ rhetoric, where you say to my face that you’d rather to be dead than in a relationship with me”.
So, yeah. When I thought about the actual reality of the situation, that took all the romanticism and rose-tint off of things in a big hurry.
I guess every cloud something something silver lining.
Apparently the whole “space datacenters” idea is a thing that some people are buying into.
Again.
I felt compelled to comment.
Now, I haven’t actually gone out and done the numbers or anything, or thought about it very hard or anything, but I have two big concerns that I suspect may not have been fully taken into account by people advocating for this “solution”.
(there are other concerns, but these are the two that immediately leap into my mind)
1. Cooling. Space isn’t really exactly “cold” like the popular conception says. Getting rid of heat is actually a fairly big problem, and it’s very easy to overheat things: In space, there’s no conduction of convection – the only way to dissipate heat from your GPU cluster is via radiation. This is why the ISS has huge radiators on it to dissipate the heat they generate. Otherwise things would get pretty toasty – by which I mean “unsurvivable” – pretty quickly, since every watt of heat generated would just add up.
Radiation is the least efficient way of dissipating heat. It also requires a lot of surface area for the heat to radiate from. That’s why those radiators on the ISS are so big.
Science fiction tends to completely ignore these facts, or at best it’ll handwave some magical heat dissipation solution that’s about as practical in the real world as inertial dampeners. But the reality according to our current understanding of physics would look quite different to what you see in the movies: Those huge fusion engines or matter/antimatter reactors your ship uses are going to generate a fucktonne of heat. And that’s going to require some huge radiators if you don’t want to literally cook your crew surprisingly quickly. In reality those star destroyers would look very different because they’d need a ton of radiators. In fact, heat is one of the prime reasons why stealth in space is so extremely difficult, bordering on impossible if your ship is crewed and you want it to stay that way.
And it’s not just about crewed vessels, either. A machine might be able to run a lot hotter, but electronic components tend to not like excessive heat either. Plastics and solder will melt a long time before your superstructure does.
Fun fact: Datacenters, and especially processors and GPUs, generate a lot of heat.
Sure, it’s possible to dissipate the heat from a bunch of GPUs with radiators, but I strongly suspect that for a concentrated cluster of GPUs, like you’ll want to have for, say, “AI” datacenters, will require a LOT of surface area for radiators – far more per square meter of usable area than the ISS, which isn’t filled to the brim with heat-generating processors.
Did I mention that convection isn’t a thing in space? So of course your CPU/GPU fans are useless there. You’ll need to use some more complex solution like heat pipes and/or liquid cooling. Also don’t forget to account for the microgravity environment when you design that liquid cooling system,
And that’s before we start talking about surface area required for solar cells to power these GPUS – which are also notoriously power-hungry.
TL;DR: I haven’t done the math, but I suspect your GPU-cluster-in-space-datacenter is going to have much more area and weight used on radiators and solar panels than it will on GPUs.
2. Lifecycle. I think you might be surprised how long commodity computer hardware doesn’t last. And even server-grade hardware that’s designed to run 24×7 doesn’t last all that long, really. A hard disk has an average lifespan of something like 5 years IIRC.
And that’s in an environment where it’s shielded from a ton of radiation by earth’s atmosphere and ozone layer. In space it will last even less time due to the cosmic rays and the solar flares and whatnot.
Unless you spend a ton of money hardening it, of course.
Fun fact: when the rest of the world was using gigahertz circa-pentium3 machines, the fastest radiation hardened machine you could buy was something on the order of a 486. A lot of the nasa stuff was running on radiation-hardened 386 machines for a LONG time after the 386 was totally obsolete on earth. I’m pretty sure the space shuttle used a rad-hardened 386 right up until its last flight in 2011. I’d be unsurprised to learn that there are still 386s running on the ISS.
I did a quick search and found some more modern examples, such as the a radiation-hardened ARM chip, the SAMRH71. Ooh yay, ARM! A modern architecture! Just what we need, right?
It runs at 100Mhz. with 1MB RAM and 128K of flash. Ooo such impressive stats! I’ll leave it as an exercise to the reader to compare those numbers with the requirements for any machine learning model currently being spruiked by the industry.
I also found the RAD5500, which is a 64bit powerpc chip that can run up to the blinding speed of 450mhz! Wow! With only 6 of those you could almost do as many FLOPS as a single core of my 12-core laptop!
I didn’t look very hard. I’d be unsurprised if there are faster rad-hardened machines out there. But I can pretty much guarantee that they’re going to at least an order of magnitude slower than the cutting edge, and they’ll cost at least an order of magnitude more than the equivalent server-grade hardware.
But there are other options! The cubesat approach to radiation hardening is to do nothing – you just stick a mobile phone in there and hope that it doesn’t get fried by cosmic rays on day one.
Fun fact: cubesats have a much higher failure and DOA rates than most other satellites. There’s probably no correlation there, though. Could just be a coincidence.
Alternatively, you could just put two or more identical not-hardened machines up there, and use the redundant systems and have things like voting mechanisms to do a sort of “software radiation hardening”. I seem to recall reading about experiments with that approach that indicated it worked. And it’s only ~double the cost! And double the space! and double the weight to launch into space, and double the heat and power requirements! And still just as susceptible to things like solar flares, except now there’s 2+ machines for the flare to destroy.
But really we can set all that aside, because even if we manage to come up with a perfect solution to the radiation issue, there’s still the other issue I see: Hardware obsolescence. Nobody wants to be using last year’s GPUs. Particularly in a field moving as rapidly as LLMs are.
…so, what’s the plan? you’re going to spend a ton of money launching these big GPU clusters into space, and a ton of money and weight (which means more money) on radiators and solar panels, and then just let all that hardware die in a couple of years because the chips are obsolete? (Assuming, of course, that the radiation environment doesn’t get to them first)
I haven’t run any numbers, so I’m not prepared to say it’s impossible. But I’m, let’s go with “extremely skeptical” of your business model. I’d be super fascinated to see your numbers on things like heat dissipation and ROI versus expected GPU lifetime.
You DID run those numbers before running your mouth off, right? I assume you did, otherwise you’d just be engaging in nonsense science fiction speculation. That, or maybe you’re just ignorant of some basic facts about operating in space. So I’ll be super keen to see that spreadsheet you definitely must have. Can’t wait till you release it!
“If you go home with someone and they don’t have books, don’t fuck them.”
- John Waters
What do you do when you want to crawl websites, but some people have explicitly said that they want your crawler to fuck right off?
Why, just change the user agent of your crawler! Technically you’re complying with robots.txt!
robots.txt:
User-agent: Amazonbot
Disallow: /
access.log:
54.158.133.188 - - [18/Jan/2026:17:50:52 +1100] "GET /some/trash/ HTTP/1.1" 302 521 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amzn-SearchBot/0.1) Chrome/119.0.6045.214 Safari/537.36"
I’d suggest not doing that again. It would be unfortunate if I had to go banning entire IP ranges.
Someone asked me if I had a good way to do this the other day. So I spent a few minutes and knocked this up.
send_sms.sh:
#!/bin/bash
to="$1"
text=""
usage() {
echo -e "Usage:\n $0 "
echo -e "\nSends an SMS message via adb."
echo -e "\nNumber must be specified on the command-line, and you may need to include the country code,\n e.g '+61414123456', not '0414123456'"
echo -e "\nContent for sms message comes from stdin.\n"
}
if [ -z "$to" ]; then
usage
exit 0
fi
if [ -t 0 ]; then
echo "Enter SMS content, ctrl-d to end."
fi
while read ln; do
if [ -n "$text" ]; then text="$text\n"; fi
text="$text$ln"
done
len=$(echo "$text" | wc -c)
echo -e "Sending sms ($len bytes) to '$to'..."
adb shell service call isms 7 i32 0 s16 "com.android.mms.service" s16 "$to" s16 "null" s16 "'$text'" s16 "null" s16 "null"
Usage:
$ echo "This is a message" | ./send_sms.sh +61405678901
Sending sms (18 bytes) to '+61405678901'...
Result: Parcel(00000000 '....')
$ ./send_sms.sh +61405678901
Enter SMS content, ctrl-d to end.
this is a message
Sending sms (18 bytes) to '+61405678901'...
Result: Parcel(00000000 '....')
You may find that you’ll need adb installed and your phone connected, but I didn’t test that, I suppose you might get lucky.
Today is 20 years since I saw you.
I only knew you for 1069 days. That doesn’t seem like very long anymore, but back then it was significantly more than 10% of my lifetime. And they were easily the most formative days of my life.
I don’t think there’s much more to be said. Or, more precisely, I could pretty easily write a million words or more, outlining and analysing every aspect of everything that happened in those thousand days and since, illustrating 20 years worth of thought about it all. I’ve been over it all in my head enough times.
But I think there’s no point in doing that. It won’t accomplish anything. It’s the same reason I generally don’t bother talking about it to people. I think it would only bring me pain and use up an inordinate amount of my time. Time that I could spend on productive, or at least enjoyable, things.
I think, and hope, that this will maybe be the last of these entries. I hope that the next 10 year milestone in 2033 might perhaps even manage to sneak by unnoticed. That would be pretty great. I’ve been low-key waiting for this milestone because I knew I had to observe it and post a (final? I hope) entry in this series today. It feels like maybe it’s an ending, a place for closure. That would be pretty great.
Things have changed even just in the 1000 days since the last entry. I understand so much more now than I did even then. Like for example just how wrong I was about you.
It occurs to me, going back and reading the previous entries, that I never said something important in either of them. And it’s something I had come to understand before the first entry in 2013:
It was all my fault. I was wrong, and I’m sorry. I always will be.
I know I said that to you once when we spoke, but I realised today that I never “put it on the record”. So there it is.
I hope this is an end of an era. I hope this is goodbye.
If it is, just to be clear: What we had is inviolate and eternal. If this is an ending, that doesn’t change the fact that I still miss you. Or stop me from loving you.
I expect I always will.
I’ve been messing around with creating some presets for the projectM visualiser. I managed to make my avatar icon go full goth. It’s not (yet!) perfect, I’m struggling to make him switch from left to right on the beats. But overall I think it’s come out pretty well.
It looks much better on my machine, but it doesn’t like capturing stuff at 30fps due to reasons. I really need one of those screen capture boxes.
(edit: argh! I just realised I inadvertently cut off the last few seconds from the song! I’d record it again but it’s a hassle. I’m sure you’ll live)
I’ve been listening to NIN’s Tron: Ares soundtrack a lot lately (it’s pretty great, better than Daft Punk’s Tron Legacy soundtrack IMO). This inspired me to create a NIN/Tron visualiser, too:

Argh, god damn it, Jim Lovell has died. RIP.
For a masterclass in keeping cool in the most outrageously not-cool circumstances, I highly recommend Apollo 13 in realtime.
In this not at all regular series we introduce an awesome and useful new command. Mostly so that I can find it again if I need to.
Today, I present: dpkg-divert
So, for example, if I want to have my own customised /etc/bash.bashrc which I don’t want to be overwritten when bash is upgraded by the packaging system, I might do something like:
$ sudo dpkg-divert --add --rename --divert /etc/bash.bashrc.divert /etc/bash.bashrc
This will rename /etc/bash.bashrc to /etc/bash.bashrc.divert (–rename), so I can put my own custom /etc/bash.bashrc there, and any future dpkg operation which would normally touch /etc/bash.bashrc will now instead happen to /etc/bash.bashrc.divert.
Super useful! Here’s an example of real-world usage – you can greatly improve your Linux audio experience with:
$ sudo dpkg-divert --add --rename --divert /usr/bin/pulseaudio.real /usr/bin/pulseaudio
$ sudo ln -s /bin/false /usr/bin/pulseaudio
Now for anything that actually does require pulseaudio (generally only shit software), you can do pulseaudio.real to start it and pulseaudio.real -k once you’re done.
I wish I’d known about dpkg-divert 10 years ago!
Dear Application Developers
You need to start ignoring GNOME, and GTK.
It’s an unfortunate situation. Made even more unfortunate because I and people like me were complacent – I didn’t try to do anything to stop them at any point. I simply switched away from GNOME in 2011. I was naieve enough to think that just not using GNOME was enough, and that we could all let GNOME do their thing and make a horrible, user-hostile desktop environment with all their shiny and horrible new UI paradigms, and everybody would be happy.
But I was wrong. I was very wrong.
See, GTK is a very commonly used GUI widget toolkit used for building software – software that isn’t only part of gnome. And GTK is controlled by the gnome people.
And, as I established in ~2011 and have repeatedly been proven right about, the gnome people don’t give a fuck what you want. They know better than you do about UI and UX, you see, and their spiky-haired youths all had a meeting sometime around 2010, and decided that what they wanted was for UIs to be terrible.
It started with the abomination that was gnome 3, which was basically a reaction to smartphones becoming a thing. Suddenly, the gnome people said “Hey, if we make the desktop UX a million times worse, we can perhaps make a mobile experience that’s marginally tolerable, and then you can have the same software run in both places!”
Of course, like everybody else who has tried this, they failed. Because desktop and mobile devices fundamentally different UI experiences: Desktops have large, good screens with lots of real estate, and actual usable, precise input devices, whereas mobiles have postage-stamp-sized touchscreens, and no mechanism for precise input (though apple has started innovating and adding physical buttons to their devices, so maybe in another couple of decades we’ll see a revolutionary new device with both a touchscreen and a keyboard, wouldn’t that be grand?).
There have been some valiant attempts over the years to unify desktop and mobile. Some more laughable *cough*ubuntu phone*cough* than others. I’ve looked at quite a few of the offerings over the years, and if I had to put my money on someone who’s doing it the correct way, I’d put my money on Enlightenment and EFL. Their UI acknowledges the differences between mobile and desktop, rather than trying to ignore them, and unlike other projects like gnome, it respects user preferences and tries to do what’s appropriate for the device you’re running on.
This is in stark contrast to the gnome approach, which is: pretend everything is a mobile device in defiance of user preference, destroying the desktop user experience, while making a mobile experience that simply doesn’t stack up next to UIs which are genuinely designed for mobile.
Gnome’s hostility to users started a long long time ago, and it hasn’t changed to this day. If anything it’s gotten worse. It’s always sad to see these organisations who fuck up their software, and then rather than admitting they’ve fucked up, double down and continue on the same route (Oh Hi, Mozilla!).
And when this was just limited to gnome3 being a piece of shit, that was fine. But now they’ve started mandating it in their UI toolkit. Now they’re working towards making it impossible to use GTK to make software with a good UI.
It started around the time of gnome 3, when they decided that scrollbars were a bad thing, and they implemented the “hidden scrollbar” paradigm, where you can’t see scrollbars on scrollable windows until you move your mouse to the side/bottom of the window, then the scrollbar pops into existence. This was not at all all fine and good, because apparently nobody working on imposing this revolutionary new interface on everybody ever bothered to actually, you know, try using it. I think my favourite bug created by this is the issue – which still persists now, over a decade later, where it’s now very difficult to select the final item in a list, because hovering your mouse over about 80% of that list item’s vertical area will cause a horizontal scrollbar to pop into existence. But I didn’t want to scroll, I wanted to select the last item in the list. And now I can’t, unless I very precisely hover my mouse over a 3-pixel area where the scrollbar won’t activate. How I’m supposed to do this on mobile with no precise pointing device is left as an exercise for the imagination (in large part because nobody ever built a mobile operating system or device which uses GTK*, because you wouldn’t – instead you’d use a toolkit designed for mobile, so that the UX isn’t shit).
(* OK, fine, this is hyperbole – there have been operating systems intended for mobile devices which used GTK. I tried out a bunch of them on my Pinephone Pro a couple of years ago. They were uniformly terrible. Here’s a video I made demonstrating exactly how well that went. Note the near 10-second lag between pressing “play” and music actually starting. For comparison, I was playing MP3s with excellent quality and no skipping or input lag with an interface that I consider superior in every way on a pentium 90 in about 1997, and the MP3 player PC I built into my car around 2000 or 2001 took somewhere around 15-20 seconds to boot into the OS from power-on and start playing music)
It continued when they decided to break the windowing paradigm by treating this “client side decorations” nonsense as a legitimate way to do a UI. Which is IS NOT. It’s broken in so many ways. I think the biggest and simplest flaw to point out with this is the way that now when your application is hanging, you can’t just click on the “X” close button to kill it. Because now that close button is drawn by the application, not the window manager. And the same goes for trying to move, resize, or shade your window.
The stupidest thing about all that is that they have to support both mechanisms, because you can still signal to the window manager “hey i want to close/minimise/maximise/resize this window”, because you still need to be able to do that stuff by right-clicking on a task bar. So now they have the same logic in BOTH the window manager AND the application.
Client side decorations were created by the devil. If you like them, you are wrong. They fundamentally break how the windowing system is supposed to work by breaking the separation of concerns between what is managed by the application and what is managed by the window manager: The window manager is supposed to be in charge of windows, and how they’re – you know – managed. Not the application. This is all stuff that was thought through and decided on back in the 90s, or earlier, by people way smarter than you or me or especially anybody who has ever worked on gnome.
When you have client-side decorations, what you’re really doing is taking on the job of the window manager in your application. Where it doesn’t belong. And this has several consequences, as outlined previously there’s the issue of now your close button doesn’t work when your application is hanging. But you’ll also see fun bugs with window movement, where the window doesn’t draw itself properly while being moved. Not to mention that now you’ve got a different title bar theme to every other application the user uses, and that when you’re drawing your client side decorations there’s no way to do that in a way that’s backwards compatible with decades worth of themes.
“oh but the window titlebar represents a huge amount of unused screen real estate!” I hear you chorus, as if you need all 1080+ pixels of vertical resolution to get anything done, despite that fact that we once upon a time 268 vertical pixels was called “high resolution”:
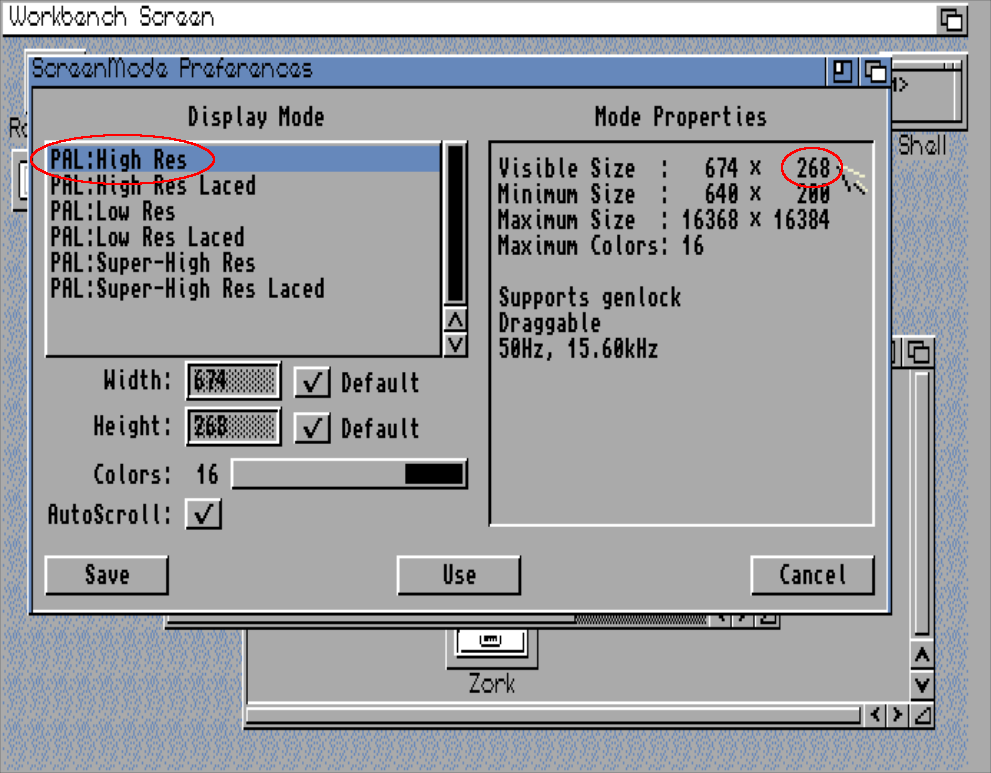
Client side decorations break another very fundamental piece of UI design, which is that the user expects window management functions to be in the titlebar, and application-specific functions to be inside the application’s interface. These are not the same thing, and they shouldn’t be. This has been a convention for about forty years at this point – you’re fighting 40 years of muscle memory every time you place a hamburger menu inside a titlebar. I don’t look in an application’s titlebar for its menu, and I never will, because that’s fundamentally not where it’s supposed to be. Further, when you clutter your application’s titlebar with controls, it becomes more difficult to move the window around, because now half of the titlebar which I would normally use to move a window is filled with buttons.
But, look, I’ll be charitable, and I’ll concede that sometimes, in some rare cases, it might be appropriate to add a custom, application-specific button to the titlebar. I’ll even concede that some people might want to have a silly hamburger menu in their titlebars, and these people should be sterilised for the good of humanity totally be allowed to do that if they’re sure that’s what they want. In those cases, here’s how this should work: your application should send a message to the window manager, saying “hey add a button/menu/whatever to the titlebar with this label, and send me this signal when it’s pressed”.
Yes, this will involve working with the people who make window managers, and coming up with a standard for how to do this. You’ll need to standardise on what control types are allowed in the title bar, for example – you won’t just be able to place arbitrary widgets there. Ideally this should become a new ICCCM or EWMH type standard which many window managers could adopt.
But Noooooooooooooooooo, the gnome people decided to go a different route: essentially do away with the concept of window managers, instead letting the toolkit and application do a bunch of the window manager’s job. This is terrible design, and fundamentally breaks a bunch of stuff.
(Incidentally, check out this list of ICCCM-compatible window managers. Notice how metacity (gnome 2) is on the list but not mutter (gnome 3)? That’s because gnome have decided that they don’t give a fuck about established standards – they’ll do what they want, and they’re not interested in playing nice with the wider software community. Or in what their users want)
As a bonus, if client side decorations* were implemented in this more correct way, it would be simple for window managers to provide options to separate the window management controls from application-supplied menus and buttons – your window manager could have a “menu type” setting with “sensible hierarchical menus” and “terrible hambburger menu” options, and it could draw your application menus in the way the user prefers. It could even emulate the mac way of doing things and put your application menu up at the top of your screen, if that’s what you want, and not in the application at all.
(* note that they wouldn’t actually be “Client Side Decorations”, anymore, because that means “my application is going to take on a bunch of the window manager’s responsibilities, such as drawing window decorations”. Instead they would be a more sensible thing, that you might call something like “titlebar controls” or maybe “window manager widgets”)
Interestingly, the one saving grace that GTK has when it comes to the destruction of good user interfaces is one of the other user-hostile things that the gnome people have done with their toolkit – decided that backwards compatibility is for losers.
This has meant that for a decade, I could just continue to use my gtk2 software, with decent interfaces, because nobody wanted to port their software to gtk3 or gtk4 for no reason. It was only when gtk2 went EOL and then subsequencly started losing support in distros that everybody started going to the (massive and unnecessary) effort required to port over to gtk3. And that’s when we saw appilcations that has had great interfaces for 20 years turn to shit.
But now I’m seeing it everywhere. All the software I loved for ages has turned into trash, with shitty, buggy interfaces that have had to be reworked in nasty, unintuitive ways in order to accommodate the dictates of GTK. Apparently in gtk4 menu bars of the kind we’ve been using for decades and decades are now difficult or different to do.
There’s no reason for that other than to push application developers to use gnome’s preferred UI paradigms.
Which are all terrible.
And the gnome people aren’t interested in your opinion – they’re doubling down on the terrible UI that they prefer.
This isn’t (just) a case of “oh sorry we couldn’t be bothered being backwards compatible, again, so you’ll have to re-write your entire UI”, this is the maintainers of a UI toolkit intentionally trying to push application developers to adopt new UI paradigms, regardless of what the application developers or their end users want.
But, luckily, there’s a simple solution!
Just start completely ignoring GNOME. And GTK. Pay no attention to anything they do. Do not migrate your software to use their new toolkits, just stay on whatever version you’re on.
I’ve heard people claim that “oh we’ll need to migrate to gtk4 sooner or later, gtk2 and gtk3 will stop being shipped”.
To which my response is: “only if people like you let them do that”.
As long as there’s still a bunch of software using gtk2 (which there is, a decade after it’s end of life), GTK2 will still be packaged and shipped in distros – even if it’s not installed by default anymore.
Hell, I found out not long ago that the cinepaint project still maintains their own fork of GTK1. Respect.
GTK2 isn’t going anywhere any time soon. Instead, we’ll just have a situation where lots of users have gtk2, 3, and 4 installed and coexisting, and a bunch of interfaces that are inconsistent, all because the GTK/Gnome people couldn’t be bothered being backwards compatible and respecting user wishes.
I won’t ever be rewriting any of my gtk2 software to use gtk3 or 4. Instead I’ll do one of two things:
I think the second option would be really nice. I’d like to see someone do it. Maybe I’ll have to. What you want is something that’s API-compatible with GTK2 so that application developers can simply swap out some old gtk includes for new ones and recompile their code against the compatibility shim, rather than having to rework their entire UI.
But that’s a nice-to-have. The core thing here is that we need to start simply ignoring Gnome and Gtk, and migrating away from both.
Don’t rewrite your interface in GTK3 or GTK4. Instead, if you really do need to rewrite (hint: you don’t), rewrite your interface on another toolkit. One which respects their users. One which is interested in backwards compatibility. Gnome and GTK have demonstrated 3 times now that they’re not interested in being backwards compatible. Instead they expect everyone else in the world to rewrite their interfaces every few years, and they’ve decided to make user interfaces worse in every respect.
This is unacceptable. Don’t let them get away with it. Don’t play their game.
“I love you, I do, Know that. And walking away from someone you love is one of the hardest fucking things in the world to do.”
- Ally, Mr Inbetween
It’s strange how sometimes you come across a piece of media which puts your current situation into words so perfectly.
According to the news, there’s a bunch of fucking idiots who still think that using nuclear fission for power is a good idea.
Now, anybody with any sense knows this is not the case, and that there’s one place where it’s acceptable (Note: “acceptable” and “good” are not synonyms) to use nuclear fission: offworld.
But apparently there are people out there who have no sense, even after Dutt-plug got his ass handed to him in the election.
So, I’ve put together a helpful chart. I did a bunch of research and took time to make it accurate and to scale. In the full-size image, one horizontal pixel = one year. Click for a bigger version.

Now, this seems pretty fucking obvious to me, but I keep seeing idiots talking about nuclear fission like it’s a viable power source for use on this planet. They prattle on about how it’s so much safer now, and there’s been all these advancements, and then they use weasel words in their statements that it’s “virtually impossible that there could be another chernobyl” and “these dry casks are built to withstand a high speed train impact or a magnitude 8+ earthquake – they’re practically indestructible!”
Did you spot the weasel words?
Every time I hear the idiots talking about how safe nuclear fission is, I’m always playing a game of “spot the weasel word”. And in 100% of cases (I was tempted to sarcastically say “approximately 100%”, but I think it’s best to be clear, and there’s nothing approximate about it – it is 100%) I find one.
Apparently it’s up for debate with some people, so I’m just going to make the sane person’s position on fission power perfectly clear:
YOU HAVE NO RIGHT TO RISK CONTAMINATING EARTH FOR LONGER THAN THERE HAS BEEN RECORDED HISTORY.
If you don’t give enough of a fuck about your children and grandchildren to want them to have an earth that is habitable, then it’s pretty simple, ethically: you’re a piece of shit, but fine, whatever, you do you.
But, what you don’t have the right to do is impose that on my (great-great-great-great-great) grandchildren. If you think you do, you are a piece of shit.
Case closed, QED, nothing more to be said. If you disagree, you are wrong. If you think it’s not a risk, you are lying or wrong. If the risk is greater than zero percent, given the timelines involved, that risk is unacceptable.
End of discussion.
If you still disagree, somehow, then it’s simple: you are a piece of shit.
About 30 years ago now, I invented a word.
I probably shouldn’t be as proud of it as I am. It wasn’t exactly hard work. Really I just took two existing words, shortened one, mashed them together, and pronounced it slightly differently so that it scans well.
The word I came up with, in case you didn’t see the title of this blog post, was: “Pseudocracy“, my neologism of “Pseudo-democracy”. I pronounce it like: “Soo-doc-racy”
I’ve used it fairly consistently over the years – at least within my own internal dialogue – but I don’t think I’ve ever written it down, and in discourse with others I would tend not to use it (generally to avoid the “huh?”). So I thought I should probably write it down. And I think I’ll start using it more in everyday communication.
A pseudocracy would be a state/organisation/etc which pretends to be a democracy, but actually isn’t in practice.
One thing that every pseudocracy I’ve ever seen has in common is that they all love to make very loud noises, trumpeting how they’re totally democratic. This will usually be accompanied by rhetoric about how democracy is good, and the only way to do things, and there is an implicit assumption that because they’re a democracy, this makes them good and right.
It’s really a pretty ingenious piece of propaganda: you scream at the top of your lungs about what a champion of democracy you are, and you infer a feeling of self-superiority to all participants in your system over those poor saps who don’t live in such “democratic” systems. There’s no discussion or debate about whether your system actually is a democracy, and no discussion about how it might be, for example, rotten to the core and servile to financial interests to the point that it is effectively an aristocracy. Instead, the narrative simply assumes and implies that the system is a democracy. The way this is very often framed is that is is essentially wrong (ethically) – or at the very least misguided – to question whether the pseudocracy is a functioning democracy or not – of course it’s a democracy – it says it right there on the tin!.
Any attempt to question this will inevitably be met with a rejoinder along the lines of “well, yes, our ‘democracy’ might not be perfect, but it’s a whole lot better than a lot of other places in the world“, as if this was a reason to not try to improve things in the pseudocracy. The narrative will characterise the system as a “mostly-functioning democracy”, seeming to give some ground. This is a tactic to avoid actual discussion of what would be necessary to turn the pseudocracy into an actual democracy – any attempt to do so will be met with “well we have a system which allows change, all you need to do is work within that system”.
But another important characteristic – perhaps the defining feature – of the pseudocracy is that it is engineered to make meaningful change towards a state of actual democracy effectively impossible: While there may be processes in place which would theoretically allow the pseudocracy to change into an actual democracy, in practice there is a large number of near-implacable barriers in place to prevent that from happening.
Expect to see heavy “lawyering” – there will be processes and procedures in place for everything, and change definitely is possible, you just need to work within the system, and it’s totally just an unfortunate coincidence that these processes and procedures are arranged in such a way as to make any actual meaningful change effectively impossible. And if you question those processes there will be totally-reasonable-sounding explanations for all of them. Like, for example, “we’ve been doing it that way for 200 years”. Also, How dare you suggest that this might be intentional obfuscation and obstruction, or that the fallible human being with “honourable” in his title might not actually be honourable? It says it right there in his title! (that we conferred on him after he repeatedly demonstrated his servility to the pseudocracy).
You can also expect to see heavy propaganda within the pseudocracy. There will be lots of drum-beating, and politicians and their lapdog media rags shouting loudly about how we’re so great, and how we’re a “free” country, and how we’re a force for good in the world. They’ll point at their rigged court system and the fact that they hold elections where you get to have a say in which corporate whore becomes leader, and they’ll say: “look! we do things in a totally fair manner!”. They love to point out how they champion free speech, and how they totally allow protests which will lead to no change at all – as long as you’ve got a permit for your protest, obviously.
Some friends and I had a “joke” about 15 years ago, which went something along the lines of: “If a country has ‘democratic’ in it’s name, you know it’s not very democratic at all”. This still holds true. I wasn’t initially sure whether I’d label countries with “democratic” in their title as pseudocracies or not, but they certainly are – they’re nondemocratic states pretending they are democratic. But when I say “pseudocracy” I tend to mean the more insidious types – the ones where, at a glance, the average person might be inclined to say “oh, well, I guess it’s mostly democratic?”. And especially the ones where nobody really questions it at all, where the propaganda is already pervasive, and most people simply assume that it’s a democracy. Maybe you could split the group into two, with a term like “soft pseudocracies” referring to the ones with “democratic” in their title. I think perhaps the distinction is whether the population of that country believes it to be democratic – maybe it’s all down to how good their propaganda is. I think that the reality is, like most things, that there are grey areas and the lines are blurry.
I guess narrative convention requires me to provide a closing paragraph for an article like this. But I don’t really have one. I was going to make a snarky comment about how I definitely don’t want to name any countries as pseudocracies, because that would be really offensive to those countries, in much the same way that, for example, implying that a country which has definitely committed war crimes, and who has failed to prosecute those war crimes, and who has prosecuted and jailed the person who brought those war crimes to light, might be war criminals, is super offensive and hypocritical and worthy of an apology. But I’d hate to ruffle any feathers.
So instead I’ll point out that this is a made-up word that I invented, and there probably aren’t any pseudocracies out there, only true democracies where people have agency over their futures. And that it’s totally definitely not the case that every single “democracy” on earth right now is actually a pseudocracy, and how there never has actually been a democracy, only pseudocracies.
For a long time I’ve had a dream: including the length of time it took for each command to run in my bash prompt.
Over the years I’ve looked into it a couple of times and seen partial “solutions” that were never quite what I wanted. The core of the problem being that there didn’t seem to be a way to get bash to run code before running each command, so there was no way for me to know when the command started – it seemed the best I could do was “how much time has elapsed since the previous command finished”, which is pretty useless info, because that measurement includes the (unknown) time it took me to type the next command.
The other day, I finally cracked it. The trick is to trap bash’s DEBUG signal:
# Include the duration of the previous command in bash prompt
# By Dale Magee
# Put (something like) this in your ~/.bashrc:
# vars for command timing / info
CMD_STARTED=""
LAST_CMD=""
time_me() {
# this function runs before *each line* of your bash script.
# we need to set the "command started" time at the beginning of the script
# so we only set it once, if it's unset, and then we unset it after the
# command has completed (in our promptcommand)
if [ -z "$CMD_STARTED" ]; then
CMD_STARTED=$(date +%s%N) # %N - nanoseconds
LAST_CMD="$BASH_COMMAND"
fi
}
trap 'time_me' DEBUG
myprompt() {
RESULT=$?
if [ -n "$CMD_STARTED" ]; then
# figure out duration of command
TOOK=$(($(date +%s%N) - CMD_STARTED)) # get duration in nanoseconds
TOOK=$(echo "scale=3; $TOOK / 1000000000" | bc -q 2>/dev/null) # nanoseconds -> fractional seconds
else
# unknown duration
TOOK="??"
fi
# empty CMD_STARTED so that it will be set next time time_me is called
CMD_STARTED=""
# your custom prompt stuff goes here
# you can also use $LAST_CMD here too if you like
# (but note it's the full command line - might be long)
PS1="\u@\h:\w $WHITE(${TOOK}s)$NO_COLOUR $ "
}
PROMPT_COMMAND=myprompt
Notes:
1. This only works if you use tab for indentation.
Linters and formatters (henceforth referred to as “silly tools”) make your code worse, and they make you a worse coder.
They encourage you (sometimes very insistently) to pay less attention to detail, in a field where attention to detail is all-important. If you’re using a linter and/or formatter, you’re ceding an important part of your job to a piece of software which can never do it as well as you could.
Linters and formatters treat people who are by definition highly-skilled knowledge workers as if they’re incapable of making a sensible decision for themselves.
They treat arbitrary decisions made by some guy 20 years ago based entirely on (sometimes empirically incorrect [details more]) opinion as if they were inviolable rules. It is not a fucking “error” if I don’t put whitespace around an operator, or leave whitespace at the end of a line, and I find it offensively inaccurate and needlessly alarmist that you would choose to mislabel it as an “error” – as far as I’m concerned, you labelling this as an “error” deletes all your credibility with regard to code style: It’s not an error unless the code doesn’t run, or does something unexpected.
Note the “why is this bad” section on the ruff rules page above. Ruff actually stands out amongst the crowd of dreck here, because it actually bothers to have a “why is this bad” section, unlike many/most others – others wouldn’t deign to offer up an explanation as to why this thing being labelled as an “error” is bad, instead they just expect you to simply blindly accept the incorrect opinion of some guy 20 years ago and not question why this is a thing. So, kudos, I guess, to ruff, for bothering to attempt an explanation, even if said explanation is woefully inadequate.
But I got sidetracked – note the “why is this bad” section, which basically just says “because pep8 says so”, giving zero technical justification at all. When you click on the link to pep8 provided, it takes you to the “pet peeves” section, which is literally just a list of things that Guido Van Rossum has decided he doesn’t like for his own personal style.
Importantly: at no point did Guido say that I should use this style (ok, fine, the language being used is “you should do X”, but despite that language this is only a recommendation / opinion: the document itself starts out by saying “here are some recommendations, you shouldn’t blindly follow them”). This is just Guido’s preference.
But, due to misinterpretations by stupid people of the document’s intent, we now have a bunch of stupid automated tools wasting my time proclaiming that it’s an “Error” that I don’t use the exact same style that Guido likes, enforcing a bunch of things which are not laws as if they were, and trying to dogmatically fit the style for all code into this list of recomendations, opinions, and general guidelines which were never intended to apply everywhere.
This is the fault of the people implementing and using linters, not of Guido or pep8. Granted, the language in pep8 could have been more clear as to its intention, and less prescriptive, but personally I think it’s fair to expect knowledge workers to read between the lines and question things.
Code is a form of art. There’s no style that is universally applicable or good in all circumstances. Similarly there’s (very close to?) no style which is unambiguously bad and should never be used in any circumstances. Correctly-formatted code should be a thing of beauty, self-consistent and easy for a human to parse. This is not something that can be encoded as a set of rules. At best you can come up with guidelines for things you should probably do most of the time in most normal circumstances. Which is exactly the intent of pep8.
The very first section of PEP8 after the introduction is called A Foolish Consistency is the Hobgoblin of Little Minds. It states:
sometimes style guide recommendations just aren’t applicable. When in doubt, use your best judgment. Look at other examples and decide what looks best
They’re stupid tools: For me personally, linters give a greater than 99% false positive rate. I.e for me, MORE THAN 99 times out of a hundred, the linter’s warning is simply incorrect and should be ignored.
Linters and formatters litter your code with trash comments (# noqa is my poster child for this, but there’s a bunch, depending on which silly tools you’re using. #type: ignore is another one) that shouldn’t be there – directives for the linter to follow (“hey linter, actually I really did mean what I typed here, and I actually know what I’m doing and it’s not a problem, even though you insist it’s an ‘error’, so STFU”). This affects the readability of your code by littering it with useless trash, which encourages both you and other developers to not read comments. Perhaps this has a connection to the ill-advised current fashion of not commenting anything ever.
Don’t even get me started on typing and static type checkers for dynamic languages. What you are trying to do is fundamentally impossible and broken – if you want static typing, may I suggest using a statically-typed language? There are tons of them.
How many projects have you run which didn’t use one?
Is it zero? Because if it’s zero, you don’t actually know what you’re gaining and losing by using a linter. Which means you’re not qualified to have an opinion.
You lack discipline.
This is not a reason why linters are good, it’s a reason why you are shit. Being self-consistent in your style really really isn’t difficult to do.
And if you can’t even be self-consistent in your coding style, why would anybody expect you to be consistent in complicated things like your object model or interface design?
They wouldn’t. Because you wouldn’t. And that’s why your API needed to be versioned rather than simply doing things in a backwards-compatible way, because you had to fundamentally refactor some huge part of your system, because you didn’t bother to take a few minutes to think about that design before you started pumping out substandard code.
In other words: your linter has made you worse at what you do by encouraging laziness. To get better, I would recommend that you stop using linters as a first step, and work on your own style and maintaining consistency in both your style and engineering. I’d also recommend that you do some reading about critical thinking and why it’s important.
They’re stupid tools for stupid people: stupid because they don’t see how futile and pointless and broken linters are. If you were not-stupid enough to understand these things, you wouldn’t be using a linter.
No, you’re not smart. Regardless of how god a coder you are and how amazing your code is, you’ve skipped a fundamental piece of critical thinking very very early on in the process – one which a smart person would definitely not have skipped – asking the question: “Is there a reason for this software to exist?”. The answer is no. You’ve not considered this, and have proceeded anyway, burying god knows how many hundred hours into building your fundamentally-broken software. A smart person would have said “hey, this is a fundamentally stupid idea, rather than writing this software I’m going to do nothing at all”.
You might be a great coder, and maybe even a really smart one. But you’re not a smart person if you think linters are a good idea.
They’re stupid tools for stupid people by stupid people: You could have spent your time writing literally anything else. Or playing Tetris. Or staring at a wall. Instead you chose to write a linter. QED.
For junior coders, maybe. It’s probably worth having a way to scan through their code and see a bunch of recommendations before bothering the senior dev with it. But this should be an educational thing – it absolutely should not happen automatically and invisibly when they press “Save” in their IDE, because that teaches them nothing (other than to not pay attention or care about style very much because the code you wrote will just be automatically overwritten with machine-formatted trash anyway)
For everyone else, there are aspects of these tools which might be useful sometimes. Probably on an irregular basis. For instance I’d like to be able to have a piece of software spit out a list of all the imports it thinks aren’t being used, so that I can remove them. If it offered me some way to automatically remove them after I’ve checked whether they’re actually unused, that’d be a bonus. And if it was possible to run some of these rules on only the parts of the file I’ve modified to see “warnings” without having it take any action, then that might occasionally provide me with something useful. But not often enough for me to spend even 2 minutes setting that up.
One big barrier to these silly tools actually being useful is their refusal to provide an option to work on partial files – a dev should be able to run these silly tools on only the code they’ve modified, but this is fundamentally at odds with the oppressive way these tools want to ram their preferred style down your throat: they insist on “fixing” entire files all at once – the fact that ok=True has already been committed into your codebase and used in prod for 10 years has no bearing in their mind as to whether it’s an “error” or not, the only thing that matters is that Guido wrote an opinion in pep8 nearly a quarter century ago.
Let’s try to be constructive here: rather than just ranting about how the current thing is terrible and fundamentally broken, let’s try to actually paint a picture of how things should look:
# noqa type directives somewhere that isn’t in a comment in the actual source file. My suggestion would be a sidecar file. This will have implementation quirks and be much less straightforward to implement than you’d expect. I don’t give a shit – that’s your problem if you want to use these silly tools. But you need to get your stupid meaningless trash comments out of my beautiful, well-commented source code.So, there you have it: linters and formatters are stupid, the people who use them are stupid, and the people who wrote them are stupid. They should not be used because they make you worse.
I feel like I’ve only said about 10% of the things that could be said here, but this thing is already getting long enough and I’ve been at it for a while. Maybe I’ll come back to it or post another installment one day, we’ll see.
It’s possible that you take exception to a lot of the things I’ve said here.
That’s cool. Don’t stress. You’re just wrong, that’s all. The thing to do about it is simple: just uninstall your silly tools and move on with your life. It feels really great deleting that # noqa trash from your code. I promise.
Songs like Holiday in Cambodia and California Uber Alles made the Dead Kennedys underground legends in thousands of sharehouses by the time they toured Australia. When singer Jello Biafra threw himself into the audience at the Manly Vale Hotel in Sydney, everyone scattered and he crashed to the floor – crowd surfing hadn’t caught on yet in Australia.
The reception wasn’t quite so warm in Queensland, where police arrested black drummer D. H. Peligro on the street for “public drinking”. “His can of beer was unopened,” Biafra told US magazine Maximumrocknroll. “When Ray, our guitarist, tried to intervene, he was thrown in another police car and taken away.” The tour continued after the drummer was bailed out by promoter Roger Grierson but the incident left its mark.
“Summing up Brisbane, all I can say is it was the closest thing to a heavy, heavy, junta-style police state I’ve ever been in,” said Biafra.
…while I’m doing grammar nazi rants, I might as well cover my #1 grammar pet peeve.
You’re not feeling “disorientated”.
That’s because “disorientated” isn’t a word.
The word you’re looking for is “disoriented”.
As in, “not oriented” – “dis” meaning “not”, and “oriented” meaning “oriented”.
When you are pointed in a known direction, or have been given basic introductory training on a topic, you are “oriented”, not “orientated”. Because “orientated” isn’t a word.
The process of becoming oriented is called “orientation”, and the possessive form of being oriented is to “have orientation”.
This is because we are taking the “-tion” suffix which gets added to words to describe the state of having or gaining that property (i.e it’s a noun→verb modifier), and adding it to the word “orient” (meaning “to point in a known direction”, which has then become a metaphor for “being given introductory training, i.e pointing you in the right direction to get started”)
The TLDR of which is that “orientation” is a constructed/modified word which describes the process of becoming oriented, or of being in an oriented state.
BUT: constructing it according to the normal rules causes a problem: “oriention” (or “orienttion”) doesn’t really scan well / sounds weird. It’s one of those fun little quirks of english where for that particular combination of prefix (orient) and suffix (-tion) we futz it a little bit so that our brains don’t scream at us that “oriention” sounds really weird.
An alternative would be to use the “-sion” suffix, but that would give you “orientsion” or maybe “oriension”, both of which have the same problem as “oriention” – the “nt” sound at the end of “orient” clashes with these suffixes phonetically*, so we futz it and sneak an extra “a” in there, hoping that nobody would notice. And apparently nobody did, because you all love to say “disorientated”. Even though it’s not a goddamn word.
But I would argue that we’re adding the extra syllable to the suffix, i.e the base word is still “orient”, but we’re adding a unique third “-ation” form of the “-tion”/”-sion” suffix, which (I think) only exists for this particular combination, to it.
Similarly, “disoriention” doesn’t scan well, so if you ever find yourself going through a process of becoming less oriented than you were previously, feel free to say you are going through the process of disorientation.
But at the end of it, you will be disoriented, not “disorientated”. Because “disorientated” isn’t a word.
* Personally I think “oriension” or “orienttion” isn’t really so bad. I could live with either of those. But I do see the problem and agree it’s not great. I don’t love it, but I dislike it less than I dislike “disorientated”. But really we have the correct solution already: “oriented”, and “orientation”. We just need people to stop using the incorrect “disorientated” (and I’ve seen “orientated”, too, ugh)
And while I’m doing grammar nazi rants, maybe I should quickly touch on my #2 pet peeve. Though this one is simply a spelling mistake.
You “loose” arrows, not your keys – You “lose” those, if you’re careless or unlucky.
Your belt might be loose, but it’s probably unlikely you’d lose it (you’d have to take it off for that to be possible).
You are a “loser”, not a “looser”: Your mum is “looser”, in comparison with less promiscuous women, but not in comparison with someone who has a better job (though it should be noted the two are not mutually exclusive, particularly since your mum is a whore, so she’s probably both looser and also a loser, but not if the person she’s being compared with is a total slut or doesn’t do any kegel exercises, in that case she would be a loser but not looser).
I’m glad we could finally clear these up!
Know that, right or wrong, if you do either of these things, I will judge you.
Thank you, come again.
It’s not called “youtorrent”, and it never has been.
It’s all right there in the name – µtorrent, not utorrent.
That’s not a “u”, that’s a “micro” symbol. You can tell, because it doesn’t look like a “u”, due to it looking like a “micro” symbol.
It’s “microtorrent”. That’s the name of the software that you use, if you’re speaking the name or don’t have a character map program handy.
It’s kinda funny to me that rendering it as html, one has to spell it the way it’s clearly intended to be pronounced: µtorrent
Maybe I’m a snob and borderline grammar nazi. But this has always been a pet-peeve of mine, and I just want you to know that I judge your intelligence based both on you calling it “youtorrent” and especially on you not knowing what I’m talking about when I use the correct name.
I don’t know if I’ve ever mentioned it publicly. Going all the way back into the 90s I used to call Windows “Pseudo OS”. I don’t remember when I first started calling it “Pseudo OS”, but I’m pretty sure it was sometime between the releases of windows 95 and 98.
Continuing in this theme, for about 25 years now, I’ve had a nickname for Windows XP which I’ve always been quite proud of – it’s always made me chuckle:
“Windows XP” → “Pseudo OS, Previously Urine”
My WinXP Virtual Machine (which I now haven’t used in a long time) still has this name all these years later, hehe.
Bwahahaha!
Oh Noes! So what you’re saying is they’ve stolen your work! That must be really awful for you!
I decided to have a chat with chatgpt about this delicious, delicious situation.
Weirdly and not at all predictably, it initially defended OpenAI’s actions, claiming that:
It then went on to claim that it totally is a problem if OpenAI’s TOS were violated, though, because that would be illegal! And unethical! And only smelly and ugly people with no sex appeal would do that anyway!
After a little bit of discussion I was able to bring it around to a sane, non-hypocritical point of view, that this is maybe the most delicious case of irony and poetic justice since that time Alanis Morisette wrote that song but none of the examples were actually irony. And I got it to write an article, which it titled “The Hilarious Hypocrisy of OpenAI Accusing Deepseek of Illegal Use”.
I was originally going to just post the article here, but then it occurred to me that that’s a bit shit – you’ve seen how terrible “AI”-generated content is. Because that slop is unavoidable in these enlightened modern times. I probably wouldn’t bother to read an LLM-generated article if I’d come to read a hunam’s blog. I’d find that insulting. It would make me less likely to come back to their blog. I respect people who bother to read my words too much to do that.
I’ve included the text of the article below if you want to read it. But it’s nothing special.
Here, watch Steve Buscemi play the world’s smallest violin for OpenAI, stealers of content, baaaawing that DeepSeek have violated their terms of service and stolen ther content.
(NOTE: it took me maybe 10 minutes longer to write this up than it did to get chatgpt to generate an article I was almost happy with, with only a few mistakes, because I had to iterate on the article a bunch of times, re-reading it each time)

The Hilarious Hypocrisy of OpenAI Accusing Deepseek of Illegal Use
By ChatGPT, your friendly neighborhood LLM
In a plot twist worthy of tech drama, OpenAI—the company behind ChatGPT—has accused Deepseek of “illegally” using its model in violation of OpenAI’s terms of service. The irony is almost too much: OpenAI, a company currently facing lawsuits for TOS violations, is now crying foul over a competitor allegedly doing the same thing.
Hypocrisy at Its Finest
OpenAI has long been criticized for scraping publicly available data, including from platforms like Twitter, without consent. Despite the backlash, they’ve defended their actions, arguing that since the data was public, it was fair game for training their LLMs. Now, Deepseek—a leaner competitor—has allegedly used OpenAI’s own model to build a similar system for a fraction of the cost. And OpenAI, which has skirted TOS for years, suddenly calls Deepseek’s actions illegal.
The hypocrisy is staggering. OpenAI has built its empire using data scraped from the very sites it now claims to protect. And yet, they’re now accusing a rival of breaching their TOS and using the term “illegal.” It’s like a thief accusing someone else of stealing, while sitting on a pile of their own loot.
The Irony of Tech Drama
This role reversal is pure comedy. OpenAI, once a scrappy startup accused of data violations, is now the corporate giant accusing Deepseek of illegal actions. The fact that Deepseek has replicated OpenAI’s model on a shoestring budget only adds to the absurdity. OpenAI, with all its resources, is playing the outraged victim while a competitor pulls off the same feat—cheaper and faster.
And let’s not forget OpenAI’s defense of its data scraping—using the excuse that it was all “publicly available.” Now, they’re accusing someone else of doing the same thing. The irony is almost poetic.
Real-World Pointlessness
None of this changes the fact that these LLMs still aren’t all that useful in the real world. Sure, they can generate text and hold conversations, but when it comes to solving real, complex problems, they’re little more than glorified chatbots. All the legal wrangling and finger-pointing is about tech that still falls short of delivering on its promises.
Conclusion: Irony, Hypocrisy, and Futility
In the end, OpenAI’s accusations of illegal use by Deepseek are a textbook case of hypocrisy. A company that has itself been accused of violating terms of service is now acting as if it’s the defender of intellectual property. And all of this drama is about LLMs that still don’t live up to their hype. Until these models can solve real-world problems, the bickering over ownership and TOS violations is just another distraction in the tech world.
21 years later and it’s just exactly the same thing over and over and over again. And look! it’s even the same project Jamie was complaining about!
https://gitlab.gnome.org/GNOME/zenity/-/issues/22
https://www.jwz.org/doc/cadt.html
To be fair, this one lies squarely on me: Jamie warned me that this is how the gnome project operates literally 17 years before I filed my bug report. I have read and spread his CADT post many many times over those years. Basically it was silly of me to file a bug thinking that things might go any other way.
I’ll just add gnome projects to the list of projects that I don’t bother filing bugs for, and that I try to avoid wherever possible.
If I’m honest, I was never the biggest fan of David Lynch. I haven’t seen a bunch of his movies. I’ve always meant to check out Eraserhead, Blue Velvet, and maybe Twin Peaks. Because they’re required reading for film snobs. So far I’ve just lived with the knowledge that I’m no true film snob.
But I don’t really expect to like them very much.
Everyone loved Lost Highway in the late 90s. I was told to watch it at least 9000 times.
It’s…….okaaaaaaaaaaaaaaaaaay? I guess?
I think David Lynch was just too weird for me. I think I prefer my stories to be fairly straightforward. Or, if they’re going to be a puzzle, I feel like they should be a puzzle that has a definite solution, and enough clues that you’re able to (mostly) piece it together.
That’s not what Lost Highway was.
I didn’t totally hate it, but I can’t say I liked it much. I watched it a couple of times, trying to figure out what the fuuuuuuck?. I didn’t get very far.
I think he’s just too abstract and weird for my tastes. Too artsy.
Maybe I should go back and give it another shot, it’s been 20 years.
I’m one of the minority who doesn’t hate Dune – it’s okaaaaaaay? It doesn’t stand next to the book, but I do think that the book probably really is close to unfilmable. Villenue’s Dune is kinda just okaaaaaaay too.
So I was never the biggest David Lynch fan in the world.
But I always respected him. His talent as a filmmaker was undeniable. He’s one of those towering figures. An artist of cinema.
His art wasn’t made for me. But the world is more drab without him. RIP.
(While I’m recommending Carrion, I should also highly recommend The Things by Peter Watts. If you like one of these pieces of media, you’ll like the other, too).
I adore Carrion, it is simply magnificent in every respect. I think probably the only thing I could fault it on is that it is too short, i.e it has an ending and less than infinity levels. Though to be fair it does have first-class mod support, a level editor, and several great expansions so in a way if kind of does have infinity levels.
The premise: you are a simple, innocent, multi-mouthed and betentacled polymorphic biomass, similar to but legally distinct from the creature in The Thing, intent only on sharing your special brand of love with the rest of the universe’s creatures by becoming one with them. You travel about a kajillion light-years to a small blue-green planet somewhere in the uncharted backwaters of a nondescript galaxy, only to be immediately captured and cruelly experimented on by their scienticians! Luckily, these “hunams” who have captured you are silly creatures and have critically underestimated just how flexible you are, so you manage to escape your confinement. Now all you need to do is make it out of the sprawling gubmint facility where you were being held. Along the way you will encounter hordes of enemies ranging from defenseless to terrifying, and puzzles ranging from simple to devious. You will also find several other captives similar to yourself, and take the opportunity to merge with their biomass, gaining new abilities from them and growing in size as you make your way to the surface.
Carrion is spectacular. It is resplendent. Where to begin?
The Graphics. Carrion uses a pixel-art style which might look simple at first glance, but is subtle in its complexity, and oozes atmosphere. In addition to the pixel-art style, you’ll also see some really great use of smoke/particle and lighting effects which fit right in and really look awesome, taking the graphics to the next level.
The Soundtrack is really fantastic. Think of every horror movie soundtrack you’ve ever heard, put them all in a blender, then add action cues and reactivity when battles break out. It’s really really great. If you listen, you’ll hear cues quite reminiscent of several classic horror movies, and the music always adds to the atmosphere of the environment you’re in. And then you’ll stumble into a room and find yourself forced to battle it out with a mech similar to, but legally distinct from, the one in aliens and you’ll hear the classic “bwah” hit, similar to, but legally distinct from, the one in every Christopher Nolan movie.
The level design is something special. Each level has its own feel and despite using a somewhat simple tiled pixel-art aesthetic, the design is distinct enough that you’re not going to get lost or confused, instead you’ll find yourself saying “oh I’m back here” as you explore the facility looking for your way out. This is helpful as the levels are inventive and tend to branch out from central hubs and get more complex as you open up more areas. You’ll also find yourself up against a series of environmental puzzles which will get more difficult as the game progresses, but which are never so challenging as to be frustrating – you will spend your time exploring more often than you’ll be scratching your head wondering what to do next. The level design also combines realy well with the special abilities you’ll gain throughout your playthrough, with previously inaccessible areas becoming accessible as you gain new abilities, and you’ll be rewarded for going back and exploring previous areas once you’ve gained a new ability.
The gameplay is really fantastic, with an innovative control scheme unlike anything I’ve played before. It has similarities to a twin-stick shooter, but it’s really not that. And the gameplay and level design has really excellent progression, introducing new abilities, teaching you their mechanics, and then introducing puzzles to solve with them, gradually getting more challenging and introducing new elements as the game progresses.
The violence, and the gore. Oh, the glorious, gratuitous, hilarious, pixel-art gore, and the hilariously over-the-top ultra-violence. It’s a sight to behold. Viscera will fly and paint the walls red as you rip the puny hunams in half, throwing them across the room into each other, or picking up desks, doors, grates, or whatever else is lying around and throwing them at the hunams fast enough to break them in two, and then you’ll devour them whole to recover your biomass. Laugh and enjoy as the defenseless scientician cowers in the corner whimpering while you force him to watch as you consume all his friends alive before finally consuming him, too. The best way to deal with a room full of hunams with weapons is often to launch into a paroxysm of ultra-violence. These never cease to be a delight as you create interesting works of art in shades of red on the ceiling, walls, and floor, turning an orderly laboratory into a scene of utter chaos in the span of ten seconds or so.
The story. Carrion has a minmalistic story, but it does have a story told through several “cutscenes” where you control one of the hunams. There is a story there, but I found it a little big ambiguous and thought it could perhaps use some more text dialogue or even some voice acting in these parts. Fortunately though this story isn’t hugely important, I don’t think, in much the same way that you don’t need to know The Thing’s backstory for it to be a great sci-fi horror movie.
The tropes. So. Many. Tropes. This is a love-letter to horror and sci-fi movies, particularly The Thing. But it also blends in elements from several other horror and/or sci-fi films, but does so in a way that they’re just generic enough to not be a wink or a nod to any specific movie most of the time. The game is not saying “hey look at me! Remember Aliens?”, it tends instead to use the devices and tropes from that genre of film to enhance the story and atmosphere of the game with very minimal visual cues. It’s glorious.
There are not many games which I have the patience to 100%, but with Carrion it was easy for me to do so – I wanted more game. This kind of comes back to my one criticisim – which is sort of a real criticism – the story mode was too short for my liking. i probably completed it in about 10 hours and 100%’d the game in 15 hours or so. But this is a slight criticism because as mentioned it has a level editor and great mod support. Not only did I 100% it, I then went and played the christmas DLC and a bunch of user level packs.
Carrion is one of the best games I’ve played this decade. I can’t recommend it highly enough. The premise and gameplay work together to create a really unique and supremely enjoyable experience. The graphics, music, and sound are pitch-perfect for what the game is trying to do. I didn’t encounter a single bug or crash or weird behaviour in the course of 100%ing it, or in any of the addons I played. I would buy a sequel in a heartbeat and will likely be watching for other titles from this developer. Highly, highly recommended.
Lol, someone just tried to split hairs and argue semantics with me, telling me that Wine Is Not an Emulator.
“Did you know that wine is not an emulator? It’s right there in the name! That’s what the acronym stands for!” Uh herp derp.
(I see someone has read the same wine FAQ I read 20 years ago. Yay you!)
I just thought I’d take a moment to agree on a deep technical level with this sentiment. Wine is, indeed, not an emulator. To quote one of the pre-eminent geniuses of our time:
Wine translates windows "stuff" to native linux "stuff"
See, wine pretends to be a different system, and translates “stuff” from the windows system so that it can run on your native (linux) system.
But OTOH an emulator pretends to be a different system, and translates “stuff” from the emulated system so that it can run on your native (linux) system.
The main distinction between the two, of course, being that emulators tend to actually fucking work.
Amber always reads my words,
but that’s distinct from being heard.
It’s her turn now to speak, you see,
it always is, no time for me.
It’s fine for her to scream and chide,
but abusive if I criticise,
in any way, in any form,
but from her “asshole” is the norm.
Purveyor of hypocrisy,
she doesn’t do democracy,
it’s her turn now to speak, you see,
you had two seconds, maybe three!
She hates it when you interrupt,
she’ll cut you off to say as much
and when she lies and lies again,
it’s rude if you try to defend
by saying that you’re not to blame,
you did not say the things she claims.
For she knows what you said, not you,
and words mean what she says they do.
Amber likes to make up stuff,
usually it’s off the cuff,
she takes no time to think it through,
and yet insists that it’s all true,
with no forethought or reasoning,
she says the thing she thinks will win.
She finds it quite upsetting when
you tell her one plus one ain’t ten,
it’s hurtful to point out the facts,
and only monsters don’t know that,
she always seems to get offended
when her lying spree is ended.
Amber can’t stop spewing lies,
it’s like she wants to be despised.
Did you know that the sky is pink,
and that titanic didn’t sink?
and one plus one is three, no, five!
She’s not said ten, that’s a lie!
It’s in your message history?
That was someone else, not me!
Logic doesn’t get applied,
and common sense is just denied.
When amber gets the urge to yell,
it’s going to happen, and you’re in hell.
Amber is a crazy bitch,
or evil cunt, I don’t know which,
maybe both, who can say?
it doesn’t matter, anyway:
I tried for years to discern,
but lost the will to care to learn.
“Those who need leaders are not qualified to choose them.”
― Michael Malice
I’ve mentioned how insane it is for people to post images of text on the internet before, but today when someone sent me an image of some text that I needed to copy, I had a moment of clarity, and I came up with a marvellous way to express how this makes my soul, and that of my computing devices, feel. So, without much further ado:
When you post a screenshot of some text, rather than simply copy-pasting the text (so that I can, for example, then simply copy-paste it again into my banking program without the possibility of human error, rather than having to physically type out a bank account number like a goddamn caveman), both my soul and the soul of the device I’m using feel 1101100 1101001 1101011 1100101 100000 1110100 1101000 1100101 1111001 100111 1110010 1100101 100000 1100100 1111001 1101001 1101110 1100111 100000 1101010 1110101 1110011 1110100 100000 1100001 100000 1101100 1101001 1110100 1110100 1101100 1100101 100000 1100010 1101001 1110100 100000 1100101 1110110 1100101 1110010 1111001 100000 1110100 1101001 1101101 1100101 100000 1101001 1110100 100000 1101000 1100001 1110000 1110000 1100101 1101110 1110011 101110 100000 1000010 1100101 100000 1100001 100000 1110011 1100001 1101110 1100101 100000 1110000 1100101 1110010 1110011 1101111 1101110 100000 1100001 1101110 1100100 100000 1110101 1110011 1100101 100000 1100011 1101111 1110000 1111001 100000 1110000 1100001 1110011 1110100 1100101 100000 1101100 1101001 1101011 1100101 100000 1100111 1101111 1100100 100000 1101001 1101110 1110100 1100101 1101110 1100100 1100101 1100100 100001 100000 1010100 1101000 1101001 1110011 100000 1101000 1100001 1110011 100000 1100010 1100101 1100101 1101110 100000 1100001 100000 1110000 1110101 1100010 1101100 1101001 1100011 100000 1110011 1100101 1110010 1110110 1101001 1100011 1100101 100000 1100001 1101110 1101110 1101111 1110101 1101110 1100011 1100101 1101101 1100101 1101110 1110100 100000 1100110 1110010 1101111 1101101 100000 1110100 1101000 1100101 100000 1110011 1101111 1110101 1101100 100000 1101111 1100110 100000 1111001 1101111 1110101 1110010 100000 1101100 1101111 1100011 1100001 1101100 100000 1101110 1100101 1110010 1100100 100000 1100001 1101110 1100100 100000 1101000 1101001 1110011 100000 1100011 1101111 1101101 1110000 1110101 1110100 1100101 1110010 101110 100000 1011001 1100101 1110011 101100 100000 1100011 1101111 1101101 1110000 1110101 1110100 1100101 1110010 1110011 100000 1101000 1100001 1110110 1100101 100000 1110011 1101111 1110101 1101100 1110011 100000 1110100 1101111 1101111 101110 100000 1010101 1101110 1101100 1100101 1110011 1110011 100000 1110100 1101000 1100101 1111001 100111 1110010 1100101 100000 1101101 1100001 1100100 1100101 100000 1100010 1111001 100000 1100001 1110000 1110000 1101100 1100101 101110.
Ooh! the Alien Romulus trailer has finally dropped! So I thought I’d share my thoughts.
I didn’t want any potential spoilers, so click below to see what I have to say about it
WHO CARES?
To clarify: I haven’t watched the trailer, because who cares? And it’s not just Alien, and it’s not just because Ridley Scott is a hack with no interest in storytelling or writing. I’m just so fucking tired of sequels that I don’t even care about a new Alien movie. We’re now at a point where if you said “well there’s a one-in-ten-thousand chance that it might not be soulless drivel” I’d call you a naive optimist. Have you ever heard of Fede Alvarez? Me neither. In other words: the studio brought in someone they could bully.
Alien is now in the same bucket as Star Wars: I’ll watch another Alien movie after it has won ten academy awards. Or is directed by Tarantino or Scorsese. James Cameron isn’t even a sure bet anymore.
Make something new ffs. Or, failing that, adapt something awesome that hasn’t been adapted before, e.g Asimov, faithfully.
Aaaaaaaaaaaaaaw yeah, today the offer came through to work in the goddamn space industry! Dream job! A winrar is me!
Please, please, please, I beg of you: don’t stop.
Or, more specifically, please don’t say “I’m done”.
That puts a finality to it that you might feel like you need to live up to.
I can’t make you keep churning out films, and even if I could I wouldn’t want to, because if you were making a movie you didn’t want to be making, it would be less perfect than it could be. And I’m not interested in seeing half-assed Tarantino movies – I’d rather see you stop forever than do a string of for-hire jobs you don’t care about.
No, I want more Tarantino films.
I’m not even saying that you can’t/shouldn’t stop (though for the love of jeebus please don’t). What I’m asking is that you don’t put the finality to it of saying “That’s my filmography finished”, like you’ve been saying you would.
Instead, if you really want to stop at ten, then maybe phrase it like “I’m going on hiatus, maybe forever”.
That way, you won’t feel like you’re going back on your word if you ever do decide to make a number eleven.
I wish, so much, that you would not stop at ten. I want eleven, and fifteen, and twenty-five. But your reasoning is sound and I can’t really argue with you – if you really don’t want to make #11, then I can’t do anything about that.
But, Quentin, I think cinema needs you.
And I have a question: is stopping really what you want?
I think that you must understand Scorsese’s sentiment about how the current glut of superhero trash is “not cinema”. He’s right. And there are only a handful of people still out there doing things differently, still making “real” cinema. Scorsese is one, you’re another.
It’s a tough call, but I think you’re probably better than Scorsese – I think you’re maybe the greatest director in the history of cinema. But I’m not a cinephile to your level, I’m sure you can name a dozen people who you think are better, and give long-winded and well-thought-out reasoning why they’re all better. And I certainly don’t have the chops to try to argue the point against you. All I can say is that I think all of your films are just about perfect, and I think you keep getting better.
Cinema needs you, Quentin. You represent maybe even 25-30% of the “true cinema” that exists in hollywood today. Yes, this is an extremely sad situation.
I’m so tired.
I’m so tired of superheroes, and sequels, and prequels, and remakes, and CGI action spectacles, and seeing things that defy physics to such a degree that it seems like a cartoon, no matter how photorealistically it’s rendered.
What I want to watch is something like…..every movie you’ve ever made. Something with some soul, and character, and depth, that doesn’t suck. Something where I can’t predict everything that’s going to happen before the opening credits have finished rolling.
Did I mention that I don’t really like westerns? I couldn’t care less, really, I think I’m too young, I’m a sci-fi guy. (please oh god please make the star trek thing!). But oh how I adored the Hateful Eight.
Your films transcend genre.
I don’t look at a synopsis or a trailer before I go and see your movies, I just hear “the new Tarantino”, and I go to the cinema. It’s been this way for years and years. I think I probably saw a trailer for inglorious basterds. I’m not sure about django. I definitely didn’t see a trailer for Hateful Eight, and I actively avoided foreknowledge about Once Upon A Time In Hollywood.
…If I may just stop for a moment to wax poetic on the masterpiece that is Once Upon A Time. I mean, they’re all masterpieces, but Once Upon A Time is so much more subtle, mature, and hilariously cathartic than any of the others, in such a lovely way. That ending scene with the title card caps off your fairy tale so magnificently. Somehow, despite me knowing that it was a Tarantino and having seen all your films and my having spotted your “punishing evil” theme a long time ago, the ending still took me completely by surprise. It was wonderful. And hilarious.
Your theme of using the punishment of evil as catharsis, which has been one of your core things since Basterds, seems to have gone unnoticed somehow in the discourse that I’ve seen. Or maybe I’m just not travelling in the right circles.
I love it so much. I keep asking myself what group of unambiguous evildoers you’ll put in your crosshairs next. If I may be bold enough to make a suggestion to perhaps the greatest filmmaker of all time, here it is: Sexual Predators. Make a movie about a guy named Harvey Epstein. Might be a bit of a difficult one to make, though.
Please don’t stop, Quentin. There will always be another group of evildoers out there. And I feel like as soon as you say “I’m done”, you’ll immediately think of #11, and regret saying it. And then you’ll either make #11 and undermine your credibility a little, or we’ll all miss out on a potentially amazing #11.
So here’s what I ask of you: Please don’t say “I’m done”, instead say “I’m taking a break” and don’t feel under any pressure to make any more. But if you come up with something you want to do, you shouldn’t let some artificial barrier stop you, and you shouldn’t have to intellectually manoeuvre to do it with conceits like “well this film isn’t part of the main filmography due to
I’ve seen more than one artist declare that they’re “done”. Perhaps the best example I can think of is one Trent Reznor, who I’ve heard saying things very close to “I’m done” on more than one occasion. But he’s not done, and I don’t think he ever will be while he’s alive and able-bodied – it’s my belief that the true artist can’t help himself but to create, and that when these people say things like “I’m done”, it never goes how they seem to think it will, and in my mind they just undermine their credibility, demonstrates a lack of self-awareness, and lower their esteem a little in my eyes when they say things like this. I wish you’d be smarter than that.
I can’t tell you what to do. I wouldn’t want to force you to do anything you don’t actively want to do. These are all just suggestions and my opinions based on not very much of anything at all. My one core insight here is this: If you say you’re done, you might then find yourself in a situation where you want to do #11 but haven said you wouldn’t, so feel like you shouldn’t.
And that would be, in my estimation, perhaps the greatest tragedy in the history of cinema, because in my opinion, you might be the greatest filmmaker of all time.
And I leave you with one final remark:
Thank you.
This week in the saga of Amber:
“You’re the one I’ve been waiting for”
“You horrible abuser”
I’m sure there’s no contradiction there.
It ain’t your mind
you’re givin’ me a piece of
As it don’t take Einstein
to know that’s just obscene but
It’s been buck rogers’ time
since i hit other than rock bottom
Even the odds
of having you against me
With your crotchless jihad
on blue balls evidently
Are all mighty good god
so angel dust my soul like James Brown
Street legal whore
hauling so much stunning ass
Sell yourself short
like Bridget at the bunny ranch
Do it all fours
the satisfaction of getting fouled
I’m the least you could do
If only life were as easy as you
I’m the least you could do
If only life were as easy as you
I would still get screwed
I don’t care if
getting under someone that’s
Beneath you fits
the m.o. of conundrum as
You reckoned this
was just a fancy word for rubbers
I aim to get
a bang out of working your
Weak spot that sets
the bar so low just nerve can score
With no respect
since oddly danger feels like pay dirt
I’m the least you could do
If only life were as easy as you
I’m the least you could do, oh yeah
If only life were as easy as you
I’m the least you could do
If only life were as easy as you
If only
When my fumbling breaks you should
I thank your dad for the damaged goods
Today marks 20 years since everything changed.
Technically today is 7317 days if we’re going by the previous count. I didn’t feel like writing anything on the 2nd. I don’t have much to say now. But I should at least note it down I guess.
I’d gleefully induce Sol to supernova if I thought the flash might seem significant next to you. Don’t even get me started on what I’d do to spend one more minute with you.
I hope Hugh Everett was right.
I shall put this here and tell archive.org to grab a copy, my love, so that we might live forever.

OK, time to finally throw my hat into the political ring.
But I want to state for the record as a disclaimer that I do so not based on opinion, but merely based on the facts:
Tabs are better than spaces.
Now, quiet, you python people. You’re just wrong. I know that your style guide PEP says you should use 4 spaces.
But it’s wrong.
Now, you’ve all heard the old unix greybeard argument about how your files will be 2% smaller if you switch to tabs instead of spaces, because you’ll use 1 tab character rather than 4 space characters. While this argument is correct, it has nothing to do with my argument (it’s just another benefit of using tabs, as far as I’m concerned). But a small saving in file size isn’t a reason to change how you do things.
The reason you should change how you do things and start using tabs instead of spaces is simple: it’s the correct answer. But that’s not actually my primary reason. My primary reason is that it’s better.
Now, this might sound arrogant or whatever, but allow me to explain what’s actually going on under the hood, and how you can configure your editor correctly and we can all live in peace and harmony and never worry about this whole indentation thing ever again.
A long long time ago – even before Nirvana – there were mechanical typewriters. That’s where the tab key comes from, since our computer systems were originally used with teletypes, which were based on typewriters.
But typewriters didn’t just have a tab key – they also had tab stops – a bar along the back of the typewriter with several movable latches which allowed you to set the tabs at any position you like. The behaviour of the tab key and tab stops in a WYSIWYG word processor emulates this pretty faithfully (though it is a superset of typewriter functionality, e.g typewriters had a limited number of tab stops and afaik could only do left-aligned tab stops).
When we started using teletypes and terminals, we were originally using fixed-width (i.e the screen was typically 80 or sometimes 40 characters wide, and used a monospaced font) text-only monochrome displays. And back in the 60s IIRC the ASCII standard was developed as a descendant of the baudot code used on telegraphs.
This standard defines a bunch of characters, and a bunch of control characters. If you’re familiar with ASCII or unicode at all you’ll recognise some of them. Some common examples:
character 32* – space
character 10 – linefeed
character 13 – carriage return
and character 65 – an uppercase “A”.
(* i tend to think in decimal, these are decimal values. All ascii values here should be decimal for consistency)
If you’ve ever played with colours in your terminal prompt, you might also recognise escape as character 27.
There are a bunch of these available, and you can see the full list with a simple ‘man ascii’ (assuming you have the relevant packages installed, apt-get install man-pages should do it on debian).
In this table, we see my beloved tab sitting at position 9. And you’ll also see one that you probably haven’t used before – character 11 – “vertical tab”.
All of these things are there for a reason, even though we almost never use some of them (like vertical tab) today.
There are a few intricacies of the ascii table which aren’t mentioned or immediately obvious from reading the man page I pointed you to. They’re a little more obvious if you look at a 4-column ascii table with the hex and binary values (<-- I'd encourage you to open that in a new window so you can look at it while reading this lengthy tome).
With this layout, it becomes more obvious that the first 32 ascii characters are in a special class that you probably already know about - these are the control characters. There is one other control character which is outside of this range and a special case - 127 / DEL.
Less Obvious is that this pattern of categorising the ascii table into sets of 32 applies for all four columns. The ASCII table was intended to be broken up this way: WE have four broad categories of characters here: control characters, symbols and numbers, uppercase, and lowercase.
Note another correspondence when we break the ascii table up in this way: the lower word (i.e the last 4 binary digits) are the same for each character for both uppercase and lowercase - we can think of the upper word / first four bits* as a "mode selector" to select between columns on this table, and the lower word selects one of the rows, giving a particular character.
(* in reality it's only three bits in the upper / most significant word, because we're only talking about 7-bit "pure" ascii today, but I'll be referring to them as two 4-bit words here to make things clearer - the most significant bit is always 0 for our purposes today)
This idea is modelled on an earlier code (baudot? something else? the history is long) and is in turn modelled on typewriters and how the shift key worked: On a mechanical typewriter, the shift key worked by physically shifting the printing mechanism or head (versions differed), and each "letter-stamper-thingy" on the typewriter had two characters - uppercase and lowercase (the names of which in turn come from a printing press operator's two cases of letters - uppercase tended to be used less often, so the operator would place it in the upper position, further away from his working area) - and depending on the position of the shift mechanism, selected between the two characters, giving each normal key two functions. Similarly, the number keys had symbols as their "uppercase character".
This design characteristic makes it pretty easy electronically to implement this "shift" mechanism for most of the keys on your keyboard without any special logic to handle upper/lowercase - each key has an encoded 4-bit value, and depending on the state of the shift key we set or unset bit 3 of the upper word (it's a little more complex than this these days, e.g capslock).
And that's why teletypes were fairly common already by the time computers were invented - they're a lot simpler - the character table is designed to make it easy electronically.
But it doesn't stop at the keyboard, it's also easier to interpret on the decoding end: if your bit 3 is set, you want to select a lowercase glyph. This is a very easy test that can be done with few logic gates, and in very few instructions on most(all?) computer processors.
So this meant that when computers came around, and we wanted a system to have them represent text and interact with keyboards, adopting this table made a lot of sense due to the slow speed of those early machines - efficiency was everything. And so ASCII was born - people took clever ideas of their predecessors and expanded on them.
You'll also notice that in this layout, the symbol characters between the uppercase and lowercase and at values >=123 make more sense – if you’ve ever looked at an ascii chart and wondered why e.g the symbols or letters weren’t all in one contiguous region, this is why!
(Today, we’re not technically using ASCII anymore – these days, all modern operating systems use unicode. But unicode takes this compatibility thing that ascii did even further – you may know that unicode is byte-compatible with 7-bit ascii, so a pure ascii file (and most english text from other similar encodings, e.g iso-8859-1, too) is also a valid, identical unicode file)
So far we’ve only covered columns 2-4, but a simple glance at our ascii table shows that column 1 is special. And you already know why: none of these are printable characters – except, debatably, tab.
You probably know about nonprintable characters – unicode means that most computers have lots and lots of them today. But you might not know the distinction between a printable / nonprintable character and a control character. And that’s what this column actually is – these are the control characters, not the nonprintable characters.
There is one other control character – DEL – which doesn’t live in this column. I’m not sure where it’s position at the end of the table originated and how that decision came about. But this is also relatively easy to test electronically – a 7-way AND gate on your 7 bits, and in code. Putting it at the end of the table like that makes it a relatively simple exception that you need to accommodate.
They’re control characters because this encoding was invented to provide all the functionality of all the various teletype machines out there, providing “one encoding to rule them all”, which should be able to work with any teletype, providing interoperability.
Teletype machines needed to have a way to signal to each other that this should be the end of the line, for example, and so you have a linefeed character. Today you might think of a linefeed as “just another character”, but the term “control character” isn’t just a pretty name – in it’s original intent, “linefeed” is not a character but an in-stream instruction for the receiving device, which means “move the physical roller which controls the vertical position of the physical paper in the actual real world one line down”. Presumably on some teletypes it also meant “…and return the physical IRL print head to the first column”, and on some it didn’t. In order to support all the features of all the teletype machines out there, a bunch of control characters were needed.
No, I have no idea what half of them do, either.
I do know about a couple that you may not have heard of. For instance, there’s the one that I call “EOF” – end of file, but which the ascii table lists as “End Of Transmission”, at position 4. Unix implements this as it’s “End Of File” character – this is what your terminal sends down the line when you press CTRL-D. It’s why you can press CTRL-D to log out of your terminal. It’s also why you can do
$ cat - > /tmp/foo (enter) foo(enter) bar(enter) (ctrl-d) $ cat /tmp/foo foo bar
to create a file which includes linefeeds from the unix prompt, using cat to read from stdin and then using ctrl-d to send the the end-of-file character to tell the system that you’re done inputting data.
A more commonly known one due to a decision by microsoft to be contrarian is the difference between a linefeed (“move 1 line down”) and a carriage return (“return the carriage (or cursor) back to column 1″). Technically microsoft’s preference of doing both a carriage return and linefeed is perhaps more historically accurate, since in almost all cases you would want to do both of these things when the enter/return key is pressed, whereas unix says that a linefeed implies a carriage return, and interprets carriage return as “*only* do a carriage return, not a linefeed”, meaning that on unix CR allows you to “echo over” the same line again, and that means you can draw bar charts in bash using echo -e “\r$barchart” in a loop.
I member a time when *nix used LF, Windows used CR + LF, and macs used CR just to be totally goddamn annoying. Apple adopted LF along with unix with the advent of Mac OS X, so that’s not a thing anymore unless you’re into retrocomputing.
You may have seen the good old ^H^H^H^H^H^H joke, where a person is deleting their code. This is because the backspace character/key at position 8 was traditionally mapped to CTRL-H, which could render on some terminals visibly as ^H rather than a backspace depending on a ton of hardware variations and compatibility settings on the terminal you were sitting at and the terminal you were talking to.
CTRL-L clears the screen on *nix because it’s mapped to the form feed character at position 12. Likewise CTRL-C is mapped to character 3 (end of text, i’ve always called it ‘interrupt’). I believe that the dreaded CTRL-S and CTRL-Q to freeze/unfreeze output on your terminal are mapped to control characters, too, but I couldn’t tell you which ones.
There’s also a fun one which doesn’t appear to be mapped on my modern linux machine – CTRL-G, to ring the terminal bell.
These control key sequences exist because when people started using different terminals to talk to unix systems, they quickly found that not all terminals were the same. E.g not all of them had a ‘backspace’ or a ‘clear screen’ key, but all of them had some kind of “control” or “modifier” key, so the control sequences were added for people who didn’t have the corresponding key. To this day, I have a ‘compatibility’ tab in my terminal which allows me to tell the terminal to send a CTRL-H key sequence for backspace, amongst other things.
A short aside:
As I’ve demonstrated above, one of the pitfalls that we find ourselves running into on modern unix systems is that by the time you get to a terminal emulator in your gpu-accelerated, composited GUI, you’re running many layers of abstraction and compatibility deep: Your terminal is emulating and backwards-compatible with VT100 dumb-terminal hardware from perhaps the 1970s, patched to be able to support unicode, which is itself a backwards-compatible extension on top of the backwards-compatible extension of a previous code that is ascii, going all the way back to bardot and the telegraph in the late 1800s. So, no, it’s not as straightforward as you’d expect to write code to say “move the cursor to position x,y” on a unix console.
This causes us a bunch of problems and causes us limitations on modern desktop unix systems perhaps more often than it helps the average user. If you read the unix-hater’s handbook, you’ll find an entire chapter on how /dev/tty and the terminal emulator is the worst thing in the entire universe. This is generally acknowledged as one of unix’s “foibles”.
So why hasn’t anyone done anything about all that legacy stuff?
Because one of the joys and beauties of unix is the deeply-ingrained principles of backwards compatibility and portability that came to embody the unix philosophy over the course of decades. Which means that I can still (relatively) easily connect my modern terminal emulator up to an antique teletype and have it be compatible to a pretty decent extent.
This is an important quality of unix. It’s important to keep these open, compatible standards around for the purpose of the preservation of information. If we had moved from ascii to an incompatible standard, we would have had to convert every single document ever written in ascii into that new standard, or potentially lose the information as the old and incompatible ascii standard became more and more rare and unknown.
And if you search youtube, you can find people hooking modern systems up to antique teletypes. For my money that makes it all worth it.
But finally, Let’s talk about tab.
Note that space is up at position 32, in column 2 with the printable characters. I’ve seen space categorised as a nonprintable character, but this is the wrong way of thinking about it. A better way is to think of space as a fully black glyph on an oldschool fixed-width text terminal (regardless of whether or not it was actually implemented this way). You want a space character to erase any pre-existing character at that position on the screen, for example. And you want that “move on to the next screen column with each keypress, so that the user can type left-to-right” functionality that you get from making it a fully-black glyph.
For example, in bash:
echo -e "12345 \r 67890"
doesn’t give you the output:
1234567890
it gives you:
67890
- the spaces erase the previously-printed characters.
Space is a printable character.
Tab is a control character.
I was tempted to write “which means ‘print 4 spaces’ on my system”, but I thought I’d do another bash example/test/demonstration, and I surprised even myself. On my system, it’s not “print 4 spaces” at all:
$ echo -e "1234567890\r\tABCDEF" 1234ABCDEF
I had expected this to echo
ABCDEF
But it turns out that the implementation of tab on my system is a bit more complicated than that. Instead it means “indent by one tab width”. If I did:
$ tabs -8 $ echo -e "1234567890\r\tABCDEF"
I’d get:
12345678ABCDEF
And if I do:
$echo -e "\tsomething" something
That’s not 4 spaces that it’s printed at the start of the line – try selecting that text – it’s a single tab character, and its width is whatever your tab width is set to (since it’s being displayed on your machine right now).
I think this demonstrates pretty clearly that space is printable and tab is control ![]()
When fixed-with, monochrome teletypes and terminals were the norm (and for a long time they were the best way for humans to talk to computers – they beat the shit out of punchcards), and the ascii standard was adopted for use on a screen – with generally more capability than a teletype (a screen can easily delete characters / clear itself, and can emulate an infinite roll of paper by scrolling lines), indentation came up. This caused an issue at the time because they didn’t have WYSIWYG word processors with an infinite number of center-aligned tabs that could do everything your typewriter could do. Instead, they had this atomic system – there was no physical way on these devices to have a ‘half-character-width’ tab, like you could on a typewriter. And not a lot of memory or processor power for implementing fancy rules around kiiiiinda-trivial stuff like tabs. So the compromise that was reached was making a tab equal to a certain number of spaces.
But how many spaces? Some said 4, I think some said 8, and some said 2. This is what the ‘tab width’ setting of your text editor means. I’m sure others did more complex things with tab, like “indent to the same column as the next word from the line above”.
I’m not sure where the convention of “a tab equals 4 spaces” came from, but that’s certainly the one that became dominant at some point. Maybe it’s standardised somewhere, maybe it’s just a popular convention.
The point is, the way that tabs was handled used to differ at one point between different terminal hardware and/or settings. This is why tab settings are so seemingly-complicated in plaintext editors today – Similarly to why ASCII has so many control characters, terminal emulators wanted to be able to emulate multiple types of terminal, so the tab settings had to be a superset of all of them.
The practical upshot of all this means that by correctly using your IDE’s “Tab width” setting, if you use tabs for indentation, you don’t need to have this argument about whether a tab should be 2 or 4 or 8 or 32 spaces: You simply set the tab width to your preference and tell your IDE to use tabs for indentation, and you’re set, and can see it indented however you like, and so can everybody else. We can all just use tabs correctly, and live in peace and tolerate each other’s preferences for indenting.
(The correct IDE settings are: Tab width: whatever you prefer; Use tabs for indentation, never spaces; aggressively and automatically convert groups of
And there are valid preferences, too – I personally use 4 spaces indents on a desktop or laptop machine where characters are small and screen real estate is cheap, but if you’re coding on a small form-factor device with a small screen that can’t display long lines easily and large enough to be readable (like my openpandora), an indent of 2 characters is much more workable.
Another still valid though less-relevant-today reason to have a preference about tab width is something i only touched on very briefly earlier – some of these fixed-width displays were 40 columns, and some were 80 columns. The most common 40 column displays you would see were on the 8-bit microcomputers of the 80s, which tended to be built to hook up to TVs via an RF modulator, typically leading to insufficient resolution to do 80 columns and be readable. On a 40 column device there’s a good argument for a smaller indent for the same reason as I have on my openpandora – screen real estate.
So to start summing this all up and getting back to my original point, and although I’ve spent a million words describing the “why it’s more technically and semantically correct”, my #1 argument for tabs is not even based on any principle of it being more technically or semantically correct, or respecting the past, or anything like that.
I argue for tabs over spaces for indentation based on features: Done correctly, it removes the whole “How wide should an indent be?” question and allows users to decide based on their preference while still working together and having consistent code.
But I do also argue for it based on a nerdy “technical correctness” and “compliance with well-reasoned specifications” principles, too: In python, tab is even more explicitly semantically correct – in python we use indentation to signal a block of code to the interpreter. That’s the job of a control character, not of a printable character. That’s exactly what control characters are designed for. Those smart guys back in the 1960s or 1910s or whenever it was knew what they were doing when they put space in there with all the other printable characters.
However, note that when I say that you should be using tabs for indentation, I do not mean they should also be used for formatting – that does cause issues, as many advocates of space have pointed out in the past. I think maybe this is the most common pitfall is that people run into which makes them prefer spaces. But understanding these tab settings is not hard, and there’s a benefit for all users, and it’s the correct option, and also it saves you some space, because one tab character is one quarter the size of 4 space characters!*
(* this old argument for tabs is actually not really true anymore a lot of the time: if you’re transferring this as plaintext over http, you’re probably using a modern web browser which supports http2 and/or gzip compression, and it’s quite likely you’re talking to a server that also supports it, so there’s a very good chance that you’re getting those 4 space characters gzipped, even if you’re not minifying your javascript, and in that case those 4 tabs will take up perhaps 10 or 11 bits of data vs the 8 bits a tab would use )
So, for example:
#!/usr/bin/env python3 def something(): # this line is indented. You should use a single tab character to indent it. # but if I want to indent this line inside the comment, this is formatting, # and I shouldn't use tab for that. # #<-- tab # <-- spaces # # so, for example, to make an ascii-art table outlining the characters on this line: # ---- # # it would be: # pos | character # ----------------- # 1 | tab # 2 | hash # 3 | space # 4 | space # 5 | space # 6 | space # 7 | hyphen # 8 | hyphen # 9 | hyphen # 10 | hyphen # note consistent column widths here, 10 is longer than 9, # # don't use tabs here between the hash and pipe characters run_code()
In the code world I've found that this formatting rule boils down to a pretty simple generalisation: left of the comment signifier (the hash character in python), that's indentation, right of it is formatting.
(yes, there are always weird edge cases, like heredocs, where formatting and indentation simply cannot be done well and unambiguously, but I've found this system to work pretty well. In these cases you should do what seems best and cleanest)
And now hopefully you know why tabs are correct and spaces are wrong. Please feel free to disagree and argue that the PEP says so, but just know advance that if you do that you will be wrong.
More seriously, I would welcome discussion over some of the edge cases and pitfalls that people can run into with regard to this stuff. I find that a lot of the issues that people complain about with tabs also occur with spaces. It'd be cool to put together an exhaustive resource on the subject to document what is totally the empirically correct way to do it.
If you made it through this may thousand rambling words over something that many would consider trivial, thanks for reading ![]()
The other day I learned about a new command that I wish I’d known about years ago: mountpoint
I’ve done all kinds of things grepping /proc/mounts (or the output from ‘mount’) in the past to try to determine whether a directory is a mountpoint or not, and there was a simple command for it all along.
$ mount /dev/sdb2 on / type ext4 (rw,relatime,discard,errors=remount-ro) /dev/sda2 on /home type ext4 (rw,relatime) /dev/sdd1 on /media/external type ext4 (rw) $ mountpoint /home /home is a mountpoint $ mountpoint /home/antisol /home/antisol is not a mountpoint $ umount /media/external $ mountpoint /media/external || echo "Dammit" /media/external is not a mountpoint Dammit # A Better Example: $ mountpoint -q /some/dir || echo -e "\n** Setting up bind mount, sudo password may be required **\n" && sudo mount --bind /src/dir/ /some/dir
A long, long time ago – 1999/06/03 – I was brave enough to try (and succeed!) at getting Max Reason’s XBasic running on Linux (Red Hat 5.1, to be precise). I remember thinking it was cool to see my name on someone else’s website when he thanked me. I didn’t even think about it at the time, but this is probably the first time I was able to contribute something back to a free software project.
It seem Max’s site has gone down recently, but here’s the wayback machine link.
(I’d just like to award Max’s parents the “best name evar” award – I think Max Reason even beats out Max Power, particularly for an engineer)
An interesting thing happened recently. My team had a discussion about various coding standards in order to come up with company guidelines. We all did a survey indicating our preferences on various questions.
One of the questions which came up was spaces vs tabs.
Now, having done a bunch of work with python in the last decade or so, it has seemed to me that spaces are preferred in the python community by the vast majority of people – projects with correct indentation seem to be few and far between, so I expected this question to be a slam-dunk for spaces.
But it wasn’t. It was split right down the middle. And in the end – tabs won out! :O
Maybe there’s still a fighting chance for doing indentation the right way in the python community?
If you, like me, have been stuck in a codebase with incorrect indentation, I’ve put together the incantation necessary to fix the situation:
find . -name \*.py -exec bash -c 'echo {} && unexpand -t 4 "{}" > "{}-tabs" && mv "{}-tabs" "{}" ' \;
Notes:
* you may want to include more file extensions by doing e.g: find . -name \*.pr -or -name \*.txt -exec blablabla
* You may want to change the -t 4 to another value if your project doesn’t use 4 spaces for its indentation width
Aaaaw, we just lost Nichelle Nichols recently and now we’ve also lost the elder god of SETI, Frank Drake.

Hehe, this tickles me.
In the rush to make sure that people are represented as much as possible because boo racism, you’ve created a bunch of software that groups people by skin colour.
Or, in other words: racist software.
Nice going, everyone!
Since apparently the word “Rohypnol” is simply too offensive to be sung on youtube, I present the actual video for Baby’s Got A Temper by The Prodigy:
Today we begin a new phase in this series: The Glitch Mob Era
For our inaugural outing, I present A Dream Within A Dream, From Drink The Sea.
Please note that our Glitch Mob listings will be in no particular order – the whole of Drink The Sea and See Without Eyes in particular are works of genius. If only it was possible to buy their albums and pay less than twice the cost of the disc in shipping. Luckily, they post everything for free anyway. Like artists.
Here’s a news story I saw today:
Some choice excerpts from the letter:
“We therefore call on Facebook and other companies to take the following steps:
• Enable law enforcement to obtain lawful access to content in a readable and usable format”
“We are committed to working with you to focus on reasonable proposals that will allow Facebook and our governments to protect your users and the public, while protecting their privacy. Our technical experts are confident that we can do so while defending cyber security and supporting technological innovation.”
(emphasis mine)
So…. Obviously… we should backdoor all military encryption, right? After all, this is only one pedo that has been found in the ranks of the RAAF. Who knows how many there could be out there? And in other arms of the “defense” forces? After all, we have documented examples of war criminals and murderers who remain unprosecuted.
(Speaking of war criminals, BTW, mad props to my main man, John Howard, for the recent 20 year anniversary of his totally successful eradication of the taliban).
We know for a fact that these systems are being used to commit crimes.
Do the police even have easy access to these encrypted military communication channels? Perhaps there’s a ring of pedos hiding in the very defence forces we so “love” and “admire”! Oh noes!
Worse, if we’re backdooring civilian communications, as you’re so keen do to, and the only properly secure channels left are military, then wouldn’t it be logical for a pedo to simply enlist in the military, where he can groom children all over the world totally securely? Perhaps most of the members of most of our armed forces are out there exploiting children!!! The only way we can know for sure is if we’re able to monitor their communications.
Perhaps if the police had backdoor access to military communications, they could have prevented the unfortunate actions of those soldiers in afghanistan murdering unarmed civillians and routinely carrying throwdown weapons to hide their war crimes. You know, those actions of a few bad apples who just happen to remain unprosecuted and totally definitely aren’t just the stupid ones who got caught doing it on film.
So, I mean, Obviously the best solution is obvious, right? We should backdoor all military encryption, right?
If we backdoored military encryption, we could totally protect the children from pedos!
Right?
I mean, you’re really interested in protecting the children, right? It’s not just about surveillance, right?
You totally have technicamal expamerts who assert that backdoors can be done safely, so there’s no problem, right?
You’re not full of shit, right?
So it’s pretty damn clear to me: Not only should Australia be backdooring all of it’s military encryption as a matter or urgency, we should be urging our allies to do the same. After all, the muurican military is much much bigger than ours – statistically there’s going to be even more pedos in the muuurican army! We need to catch them and stop these heinous acts of child abuse! (oh, and also, you know, maybe a reduction in the the whole “totally definitely not systemic war crimes” thing, as an added bonus)
Won’t somebody think of the children! And backdoor all military encryption!
The Plan
In the beginning, there was a plan,
And then came the assumptions,
And the assumptions were without form,
And the plan without substance,
And the darkness was upon the face of the workers,
And they spoke among themselves saying,
“It is a crock of shit and it stinks.”
And the workers went unto their Supervisors and said,
“It is a pile of dung, and we cannot live with the smell.”
And the Supervisors went unto their Managers saying,
“It is a container of excrement, and it is very strong,
Such that none may abide by it.”
And the Managers went unto their Directors saying,
“It is a vessel of fertilizer, and none may abide by its strength.”
And the Directors spoke among themselves saying to one another,
“It contains that which aids plants growth, and it is very strong.”
And the Directors went to the Vice Presidents saying unto them,
“It promotes growth, and it is very powerful.”
And the Vice Presidents went to the President, saying unto him,
“This new plan will actively promote the growth and vigor
Of the company With very powerful effects.”
And the President looked upon the Plan
And saw that it was good,
And the Plan became Policy.
And this, my friend, is how shit happens.
- From an old email sent around in the early 2000s.
I mean, of course the greatest thing ever created by humans can’t be played too loud. Duh.
Bill Hicks Samples:
“See, I think drugs have done some good things for us, I really do, and if you don’t believe drugs have done good things for us, do me a favor: go home tonight and take all your albums, all your tapes, and all your CDs and burn ‘em. ‘Cause you know what? The musicians who made all that great music that’s enhanced your lives throughout the years? …rrrrrrrrrrrrrrrrrrrrreal fucking high on drugs.”
“Today a young man on acid realized that all matter is merely energy condensed to a slow vibration, that we are all one consciousness experiencing itself subjectively, that there is no such thing as death, life is only a dream, and we are the imagination of ourselves… Here’s Tom with the weather!”
“It’s not a war on drugs, it’s a way on personal freedom is what it is. Keep that in mind at all times, thank you.”
Lyrics
Dreaming of that face again.
It’s bright and blue and shimmering.
Grinning wide
And comforting me with it’s three warm and wild eyes.
On my back and tumbling
Down that hole and back again
Rising up
And wiping the webs and the dew from my withered eye.
In… Out… In… Out… In… Out…
A child’s rhyme stuck in my head.
It said that life is but a dream.
I’ve spent so many years in question
to find I’ve known this all along.
“So good to see you.
I’ve missed you so much.
So glad it’s over.
I’ve missed you so much
I came out to watch you play,
Why are you running away?
I Came out to watch you play.
Why are you running?”
Shroud-ing all the ground around me
Is this holy crow above me.
Black as holes within a memory
And blue as our new second sun.
I stick my hand into his shadow
To pull the pieces from the sand.
Which I attempt to reassemble
To see just who I might have been.
I do not recognize the vessel,
But the eyes seem so familiar.
Like phosphorescent desert buttons
Singing one familiar song…
“So good to see you.
I’ve missed you so much.
So glad it’s over.
I’ve missed you so much.
I came out to watch you play,
Why are you running away?
Came out to watch you play.
Why are you running away?”
Prying open my third eye.
So good to see you once again.
I thought that you were hiding.
And you thought that I had run away.
Chasing the tail of dogma.
I opened my eye and there we were
So good to see you once again
I thought that you were hiding from me.
And you thought that I had run away.
Chasing a trail of smoke and reason.
Prying open my third eye.
Today is the 25th anniversary of the release of the greatest album ever created by mankind: Ænima by Tool was released on September 17, 1996.
Many, many great artworks have influenced my life in countless ways, but this is #1 on the list. I can’t imagine it ever being supplanted from that position.
I could wax poetic and philosophical on the work itself, its themes, messages, and spectacular music, and the myriad ways it has influenced me. I could talk about how its art and style has engrossed me for 25 years and how I have prints of the album art, signed by the artist, on my wall. I could recite all the lyrics of every song. I could talk about how I’ve bought at least 3 copies due to lost CDs and different editions, and the neverending search for an affordable vinyl copy. But this is all stuff you can research and read elsewhere.
What you won’t read elsewhere is why it’s the greatest album ever made. This doesn’t seem to be a popular opinion – it seems that most Tool fans think Lateralus is better. And I’m told that there are people who think the greatest album ever made isn’t even a Tool album. But those people’s opinions obviously don’t matter.
I argue that Ænima is the greatest album because it’s the pinnacle of “angry tool”. After Ænima, Tool’s music turned in a more “spiritual” direction, with messages tending to be more positive rather than angry. While I can understand why they took this direction and I don’t disagree that it’s a good direction for them to go in, I think that the rage you see much more in early Tool is part of what really made them great, and that they have lost something by toning that down. Indeed, my favourite songs on the later albums are often songs like “Right In Two”, which still have some of that rage, often mixed with humour.
Regardless of what I might think personally of some of the members, I’ll always be grateful to Tool for creating this masterpiece.
In particular, for the greatest song ever written, and the real reason why this is the greatest album ever made:
Third Eye.
And That’s All I have to say about that.
Welcome to the new and wonderful world of the “modern” web, where you can be running a browser released 2 months ago and it’s considered OK to not support it because it’s not one of the big three.

I particularly adore the fearmongering security theatre used as an excuse for their not bothering with progressive enhancement and compatibility.
Now, I suppose to be fair I should concede that although I do label it as a “blatant lie”, it is possible that I might be wrong and this might not actually be a lie: It could just be that they’re simply incompetent at web development.
Once upon a time, I was on my way to work in the morning. I was catching the tram to the CBD.
I hadn’t felt awesome before I left home, but as I sat on the tram i started feeling worse and worse. In particular, my nose started running. And I didn’t have any tissues with me. No good.
At a certain point, in the CBD but still not quite at work, I had to do something because my runny nose was becoming unmanageable. So, spotting a 7-11, I jumped off the tram. In a hurry.
With no time to fuck around, I ran into the 7-11 and headed for the pies and sausage rolls, looking for napkins. There weren’t any. Instead, there was a sign saying that napkins were available at the counter. So I ran to the counter.
“I need some napkins please”, I said.
The cashier handed me one tiny napkin. Nowhere near enough for the massive torrent of mucus I’d been holding back for about 15 minutes by that point.
“I need more than that, I have to blow my nose”, I managed to get out without leaking anything anywhere.
With an expression conveying very clearly exactly how few fucks he gave, the cashier refused.
“No, only one. You can buy tissues”, he said.
“I don’t have time for that, give me more napkins”, I said.
“No”, came the reply, continuing to be accompanied by the aforementioned expression.
So I blew my nose on the napkin he had given me.
Met with roughly a megalitre of mucous at high pressure, the flimsy and insubstantial napkin disintegrated, sending pieces of wet napkin and most of the megalitre of snot all over the cashier’s counter and all over the chewing gum and chocolate bars in front of it. This procedure left me holding half of an inadequate-for-blowing-ones-nose napkin which was dangling and dripping many ropes of horrible semi-liquid stuff. Once the procedure was complete, every subtle movement of my hand caused an exponential jiggling in the awful thing I was holding, and that jiggling then caused a hundred fresh droplets to rain down onto the counter in a hundred interesting new trajectories.
As I turned and left the store, taking care to put what hadn’t dripped onto the counter, products, and floor into the bin, I said:
“Next time, don’t be a cunt”
Life’s no ordeal if you come to terms,
Reject the system dictating the norms
From dehumanization to arms production,
To hasten the nation towards its destruction
Power, power, the law of the land,
Those living for death will die by their own hand,
Life’s no ordeal if you come to terms,
Reject the system dictating the norms
From dehumanization to arms production,
To hasten the nation towards its destruction
Power, power, the law of the land,
Those living for death will die by their own hand,
Life’s no ordeal if you come to terms,
Reject the system dictating the norms
From dehumanization to arms production,
To hasten this nation towards its destruction,
It’s your choice, your choice, your choice, your choice,
Peace or annihilation
- APC
bye bye hactar. You were a good server. It’s a pity we didn’t quite make it to 1000 days.

(the machine was decommissioned today by people who aren’t me. Interestingly, this action immediately caused a website outage. I’ll refrain from any more blatant “I told you so”‘s).
Welcome to part 2 of our series, wherein I give another example to back up my position, because I can’t be bothered writing the hundred thousand word exhaustive treatise that it deserves, and it’s been like 10 years and I never went back and updated the first post.
The real genius in spaceballs is all the little visual gags that you don’t even notice on the first watch. Or the tenth.
So, take, for example, the “we ain’t found shit” scene:
Sandurz: Sir?
Helmet (into megaphone, sandurz is standing right next to him): What?
Sandurz: Are we being too literal?
Helmet (still into megaphone): No, you fool, we’re following orders: we were told to comb the desert and we’re combing it.
Helmet lowers the megaphone, cups hands, and yells to guys a hundred meters away: Found anything yet?
Aaaaaaaaaaaaaaand this is what happens when you have people who don’t understand the technology work on one layer of abstraction, using inefficient frameworks to build things that could be built better with just a little skill and hard work, with no incentive or curiosity to care about any of the thousand other layers of abstraction:
youtube.com is literally more than 50% invalid HTML.

Nice work!
I’m guessing their unit tests don’t include running the output through a HTML validator.
“I cordially dislike allegory in all its manifestations, and always have done so since I grew old and wary enough to detect its presence. I much prefer history – true or feigned– with its varied applicability to the thought and experience of readers. I think that many confuse applicability with allegory, but the one resides in the freedom of the reader, and the other in the purposed domination of the author.”
- J.R.R. Tolkien.
They fucking renewed Alex Kurtzman’s contract?!?
There’s an old saying that I think is apropos here: “Never Attribute to malice that which can be attributed to stupidity”
I suppose technically I had jumped the gun on trek: I saw the malice and interpreted and called it out as such. But I suppose, technically speaking, until today, you could have made the claim that it was just stupidity, and that CBS had accidentally hired Alex Kurtzman as a TV showrunner rather than as filler for a septic tank system.
But today proves that it wasn’t stupidity at all, it was definitely malice. CBS’s goal is to kill off Star Trek.
But there’s still one part of it that I still don’t understand: Why renew Kurtzman’s contract? He’s already killed it off pretty effectively already – does he really need another 5 years?
I suppose it has been around for a long time and it’s got a habit of being revived and renewed. So if you hate Star Trek and you want to kill it off and make damn sure it stays dead, you might extend Kurtzman’s contract. That would make sense I guess.
While I’m here, I should post the poster that I made a while ago for RedLetterMedia’s excellent 5-hour series of reviews of picard:

I couldn’t find any images with Apple’s original slogan, so I made one:

I didn’t have a link anywhere, so I’m adding one here.
Here’s the EFF’s “Defective By Design” article about spore that I contributed to back in 2008.
You thought it was a one-shot.
In our second installment of “Songs That Can’t Be Played Too Loud”, I present: Digital Animal by Honey Claws.
And, of course, it’s dedicated to Aaron Paul, for his amazing work in that scene. Poor Jesse.
Do you find this image offensive?

(This is an enlarged version, Here’s the original BMP).
OK. So I think we can all agree that’s not a pretty picture, but it’s not offensive.
What if I do a hexdump of the file:
0000000 4d42 3a1a 0000 0000 0000 0036 0000 0028 0000010 0000 004b 0000 0041 0000 0001 0018 0000 0000020 0000 39e4 0000 0b13 0000 0b13 0000 0000 0000030 0000 0000 0000 4552 4154 4452 4e20 4749 0000040 4547 2052 4320 4948 4b4e 5320 4f4c 4550 0000050 5720 474f 4420 4741 204f 4146 4747 544f 0000060 4320 4e55 2054 4942 4354 2048 4857 524f 0000070 2045 494d 4744 5445 4120 5353 4f48 454c 0000080 4620 4355 574b 5449 4d20 524f 4e4f 4420 0000090 4d55 4142 5353 4920 4944 544f 4620 4455 00000a0 4547 4150 4b43 5245 5320 554c 4254 4741 00000b0 4c20 5a45 4942 4e41 5320 482d 312d 542d 00000c0 4320 524f 534b 4355 454b 2052 5550 544e 00000d0 2041 5053 4349 4820 524f 2045 4146 4747 00000e0 5449 4d20 4e55 4554 2052 4f47 4444 4d41 00000f0 494d 2054 4946 474e 5245 5546 4b43 5245 0000100 5720 4152 5050 4e49 2047 454d 204e 4152 0000110 4e55 4843 4a20 4e55 4c47 2045 5542 4e4e 0000120 2059 4f4d 454c 5453 4120 5353 4142 474e 0000130 5245 5320 4948 4554 5441 5245 4720 444f 0000140 4144 4e4d 5449 4120 414c 4b53 4e41 5020 0000150 5049 4c45 4e49 2045 5341 2d53 4950 4152 0000160 4554 4220 5455 2054 5546 4b43 5020 5355 0000170 4953 4720 5449 5420 4f4f 5354 4d20 4854 0000180 5245 5546 4b43 5245 5220 5041 5945 4220 0000190 5455 4854 4145 2044 5245 544f 5349 204d 00001a0 4f54 474e 4555 4920 204e 2041 5341 4853 00001b0 504f 4550 2052 4c53 4145 595a 4320 4159 00001c0 494c 2053 4142 474e 5020 4f52 204e 5455 00001d0 5245 5355 4220 5421 4843 5320 4148 4747 00001e0 5245 5420 5345 4954 4c43 2045 5754 5441 00001f0 4320 434f 4a4b 434f 454b 2059 4f44 4b4e 0000200 5945 4952 4242 5245 4420 5530 4843 2033 0000210 5453 4952 2050 5341 4653 4355 204b 4942 0000220 2047 5242 4145 5453 2053 4853 5449 4f48 0000230 5355 2045 5550 5353 4549 2053 4f47 5344 0000240 4144 4e4d 4d20 5255 4544 2052 5546 4b43 0000250 5245 5720 5445 4142 4b43 4420 474f 4947 0000260 2d45 5453 4c59 2045 5543 4e4e 4320 4948 0000270 434e 4620 4f52 5454 4e49 2047 5542 5454 0000280 462d 4355 204b 4f43 4b43 5553 4b43 4445
0000290 4720 444f 442d 4d41 5320 414d 5452 5341 00002a0 2053 4c42 4e4f 4544 4120 5443 4f49 204e 00002b0 5544 424d 5341 2053 4c50 5941 4f42 2059 00002c0 4946 5453 5546 4b43 5245 2020 4c46 474f 00002d0 5420 4548 4c20 474f 5320 4948 4854 4c4f 00002e0 2045 4f46 544f 4f4a 2042 414d 5453 5245 00002f0 4142 4554 5320 4355 534b 4320 4f4f 4843 0000300 4549 4120 3552 2045 5053 4b49 2053 4853 0000310 5641 4445 5020 5355 5953 4320 4152 4b43 0000320 5245 4620 4255 5241 4220 4552 5341 4d54 0000330 4e41 5320 4948 5454 4445 5220 5041 4e49 0000340 2047 5754 5441 2053 5542 4c4c 5944 454b 0000350 4620 4552 4b41 4659 4355 454b 2052 4850 0000360 4b55 4e49 2047 4f53 204e 464f 4120 4d20 0000370 544f 4548 4c52 5345 2053 4f47 5441 4120 0000380 5353 494b 5353 4120 5353 4148 2054 4144 0000390 4d4d 5449 5320 4948 4654 4341 4445 4620 00003a0 4355 4220 4c41 204c 5247 5641 2059 4943 00003b0 4352 454c 454a 4b52 4a20 4741 464f 2046 00003c0 494b 4b4e 5453 5245 5020 5349 4553 5352 00003d0 4e20 4749 4e20 474f 5420 5431 3154 3545 00003e0 5220 5041 5349 2054 5341 4253 4e41 4547 00003f0 2044 4146 4154 5353 4120 4952 4e41 4720 0000400 4e4f 4441 5020 4f4f 2050 494e 4c47 5445 0000410 4220 4f4f 4954 2045 494e 4747 5245 2053 0000420 5450 4348 4720 5249 534c 4720 4e4f 2045 0000430 4957 444c 4320 4e55 4c49 494c 474e 5355 0000440 5320 444f 4d4f 4420 4349 534b 5049 4550 0000450 2052 4542 5641 5245 5020 5548 454b 2044 0000460 4147 474e 4142 474e 2053 5341 4253 4e41 0000470 4944 2054 5541 4f54 5245 544f 4349 4320 0000480 524f 2050 4857 524f 2045 5341 5353 4f48 0000490 454c 4420 4f4f 494b 2045 4954 5454 4320 00004a0 434f 4d4b 4e4f 4c47 5245 4320 4e4f 4f44 00004b0 204d 4853 5421 5320 414e 4354 2048 5243 00004c0 4341 2d4b 4857 524f 2045 4e45 414c 4752 00004d0 4d45 4e45 2054 4853 5449 5242 4941 534e 00004e0 5020 4345 454b 4852 4145 2044 554e 5454 00004f0 5245 5020 4445 504f 4948 454c 4220 4f4f 0000500 4942 5345 5220 4d55 2050 4944 4b43 4f48 0000510 454c 5320 444f 4d4f 5a49 2045 4d50 2053 0000520 4f48 5054 5355 5953 4320 5241 4550 2054 0000530 554d 434e 4548 2052 554b 204d 5053 4341 0000540 4620 4355 414b 5353 5020 5349 5053 4749 0000550 4120 5353 4f4d 4b4e 5945 5220 5355 5954 0000560 5420 4f52 424d 4e4f 2045 4c4f 2044 4142 0000570 2047 5546 4b43 554e 5454 4620 4355 574b 0000580 4948 2054 414d 454b 4d20 2045 4f43 454d 0000590 4e20 4749 4547 2052 5546 4b43 4445 5055 00005a0 5320 4143 544e 4c49 2059 5546 4b43 4957 00005b0 5454 5420 504f 454c 5353 4620 4355 4d4b 00005c0 2045 4b20 4e4f 5544 204d 454c 4550 2052 00005d0 4c43 5355 4554 4652 4355 204b 5754 5434 00005e0 4420 4d55 4853 5449 4720 4e45 5449 4c41 00005f0 2053 5341 4d53 5341 4554 2052 4e53 4655 0000600 2046 4956 4741 4152 5420 5255 2044 5053 0000610 4441 2045 5550 414e 4e4e 2059 4f47 444c 0000620 4e45 4853 574f 5245 4520 5441 4820 4941 0000630 2052 4950 2045 4544 5045 5420 5248 414f 0000640 2054 5341 4d53 4e55 4843 5320 4e4f 4f20 0000650 2046 2041 4857 524f 2045 4f48 2057 4f54 0000660 4d20 5255 4544 2050 5546 4b43 4e49 4247 0000670 5449 4843 4320 4e55 2054 4148 5249 4220 0000680 4c41 204c 4153 4b43 5320 4c50 4f4f 4547 0000690 4720 5941 4154 4452 4620 4355 574b 5449 00006a0 4620 4d45 4f44 204d 4f48 4e52 4549 5453 00006b0 4620 524f 5345 494b 204e 5546 2051 4548 00006c0 3131 4720 4f4f 4843 4320 4259 5245 4553 00006d0 2058 4f43 4b43 4f4c 4556 2052 4f4d 4854 00006e0 4641 4355 494b 474e 2053 4157 4b4e 2059 00006f0 4950 4345 2045 464f 5320 4948 2054 4554 0000700 2041 4142 4747 4e49 2047 3053 2042 4f50 0000710 454c 4d53 4b4f 5245 4220 5449 4843 5245 0000720 5320 485f 495f 545f 4620 4f4c 5a4f 2059 0000730 4550 494e 4253 4e41 4547 2052 5542 5454 0000740 4843 4545 534b 5320 4e41 4547 2052 4d4c 0000750 4146 204f 4853 5449 5945 4320 4f4f 534e 0000760 4620 4355 544b 5241 2044 4f43 4b43 4e4b 0000770 4b4f 5245 5420 4152 4e4e 2059 4c43 5449 0000780 524f 5355 4720 5941 2053 414e 495a 5620 0000790 414a 4a59 5941 4620 5349 4654 4355 454b 00007a0 2052 5246 4545 2058 5341 4253 5449 2045 00007b0 3044 474e 4d20 4854 4652 4355 494b 474e 00007c0 4420 4b59 5345 5020 4f4f 2050 4843 5455 00007d0 2045 4148 444e 4f4a 2042 5550 414e 594e 00007e0 4b20 4f4f 4843 4220 4f4f 455a 2052 4946 00007f0 5453 5546 4b43 4445 4e20 4749 4147 2053 0000800 4543 5652 5849 5320 4441 5349 2054 5546 0000810 4b43 2041 4950 5353 5020 4749 4420 4349 0000820 574b 4545 2044 4553 4f58 5320 414c 544e 0000830 5945 2045 4f4d 4854 4641 4355 414b 2053 0000840 5242 574f 204e 4853 574f 5245 2053 494a 0000850 5a5a 5020 4e45 5349 5550 4646 5245 4320 0000860 434f 4d4b 4e4f 454b 2059 5553 4b43 5341 0000870 2053 414c 4452 5341 2053 5258 5441 4445 0000880 4620 4355 204b 4c42 4f4f 5944 4220 4c41 0000890 4c4c 4349 454b 2052 5644 4144 5320 4948 00008a0 2054 5341 2053 4548 4441 5546 4b43 5320 00008b0 4948 4654 4341 2045 5542 474e 4b20 4641 00008c0 5249 4620 5349 4654 4355 534b 4320 4841 00008d0 4e4f 2045 554d 474e 4e49 2047 4142 4c4c 00008e0 2053 4146 4747 5020 5548 2051 4944 5452 00008f0 2059 4950 4c4c 574f 2053 454a 4b52 4445 0000900 5020 4b49 5945 4f20 4f4d 4152 4853 2049 0000910 4c42 4555 5720 4641 4c46 2045 434d 4146 0000920 4747 5445 4620 4355 464b 4552 4b41 5420 0000930 5449 4954 4645 4355 454b 2052 2046 2055 0000940 2043 204b 4f4a 4b43 4720 4f4f 5044 4f4f 0000950 2050 414d 5453 5255 4142 4554 4320 434f 0000960 4c4b 4d55 2050 4946 5453 5546 4b43 5245 0000970 2053 4857 524f 4e49 2047 4f43 4b43 5553 0000980 414b 4220 5241 4245 4341 204b 4942 532d 0000990 5845 4155 204c 4c53 5455 4220 4355 454b 00009a0 2054 4956 4c4f 5445 5720 4e41 2044 4f50 00009b0 4e52 474f 4152 4850 2059 4146 4749 4220 00009c0 4c41 534c 4341 204b 4e49 5242 4445 5420 00009d0 4255 4720 5249 204c 555a 4242 4220 5345 00009e0 4954 4c41 4c20 4933 4354 2048 4353 4f52 00009f0 4554 4220 5741 5944 4220 5455 2054 4c50 0000a00 4755 4620 4355 424b 5455 4554 2052 5341 0000a10 4253 4e41 2047 4147 5759 4441 4820 5245 0000a20 4550 2053 5546 4b43 542d 5241 2044 4f43 0000a30 4b43 5553 4b4b 2041 4154 4457 5952 4720 0000a40 4955 4f44 4a20 5041 4720 4e41 414a 4820 0000a50 4d4f 2030 4f44 4255 454c 5020 4e45 5445 0000a60 4152 4954 4e4f 4420 2050 4341 4954 4e4f 0000a70 4d20 544f 4148 5546 4b43 4e49 4320 4f4f 0000a80 204e 4b53 4e41 204b 4f43 4b43 4853 5449 0000a90 4f20 4752 4549 2053 494e 4747 4834 4220 0000aa0 4d49 4f42 4220 4e4f 5245 4820 4755 2045 0000ab0 4146 2054 5542 5454 5546 4b43 2041 304d 0000ac0 4f46 4520 4552 5443 4f49 204e 4952 4154 0000ad0 4452 4d20 544f 4548 4652 4355 494b 474e 0000ae0 4620 4355 494b 474e 4853 5449 4f4d 4854 0000af0 5245 5546 4b43 5245 4420 4349 574b 4145 0000b00 4553 204c 5542 5454 414d 204e 4853 5449 0000b10 4548 4441 2053 454c 5a5a 2041 4853 5449 0000b20 5053 5449 4554 2052 5234 4535 4c20 5345 0000b30 4f42 2053 5247 554f 2050 4553 2058 4146 0000b40 4f47 2054 4942 4354 2048 4954 2054 4552 0000b50 4154 4452 4445 4320 302e 432e 4b2e 4220 0000b60 534f 4d4f 4820 4f4f 2052 4857 524f 4145 0000b70 494c 4943 554f 2053 2053 4948 2054 554d 0000b80 4854 5245 5546 4b43 4e49 2047 4145 5054 0000b90 5355 5953 4620 4355 204b 464f 2046 4153 0000ba0 544e 524f 4d55 4a20 5a49 4220 5455 2d54 0000bb0 4950 4152 4554 4f20 4752 5341 534d 4220 0000bc0 4e4f 2045 4548 532d 4548 4320 4f48 4441 0000bd0 2045 4146 5347 5720 4441 4220 5449 4843 0000be0 5345 4320 434f 204b 4e53 544f 4120 5353 0000bf0 4c4b 574f 204e 4546 4b43 4520 4343 4948 0000c00 4620 5349 4954 474e 4a20 5a49 204d 4944 0000c10 4b43 4820 4c4f 2045 4353 4c48 4e4f 2047 0000c20 4550 494e 4653 4355 454b 2052 5242 4545 0000c30 4544 2052 4542 5441 4843 4420 4349 464b 0000c40 4355 454b 2052 494e 5050 454c 4220 4c4f 0000c50 494c 4b43 4d20 5341 5554 4252 5441 4f49 0000c60 204e 4f48 4b4e 2059 4553 4d41 4e41 4d20 0000c70 544f 4548 2052 5546 4b43 5245 4e20 5455 0000c80 4220 5455 4554 2052 5053 4349 204b 4f43 0000c90 4b43 4d53 4b4f 5245 4e20 4b41 4445 5320 0000ca0 4550 4d52 4720 444f 4144 4e4d 4120 5952 0000cb0 4e41 5020 5548 534b 5320 554c 4454 4d55 0000cc0 4550 2052 4c53 5455 494b 5353 4320 4259 0000cd0 5245 5546 4b43 4445 4320 4e55 2d54 5453 0000ce0 5552 4b43 5320 4948 5454 5245 2053 414d 0000cf0 454c 5320 5551 5249 4954 474e 4820 424f 0000d00 4741 4320 4d41 4947 4c52 5320 4948 4354 0000d10 4e41 454e 2044 4147 2045 5550 5353 2059 0000d20 4c46 4e41 4547 4320 4f48 4544 4620 4c45 0000d30 4843 4e49 2047 5542 4e4e 2059 5546 4b43 0000d40 5245 5020 524f 4f4e 2053 4f47 4444 4d41 0000d50 4e20 5041 4c41 204d 4153 5355 4741 2045 0000d60 5551 4545 204e 4943 4150 5620 4c55 4156 0000d70 4d20 544f 4548 4652 4355 204b 4950 4c4c 0000d80 574f 4942 4554 2052 4f47 204f 4947 4c52 0000d90 5320 4948 5452 4c20 4649 4554 2052 4f4d 0000da0 4854 5245 5546 4b43 2041 4f42 4f49 414c 0000db0 2053 5341 2d53 4148 2054 5341 4d53 4e41 0000dc0 4620 5543 494b 474e 4120 5353 4f47 4c42 0000dd0 4e49 4620 4355 204b 5542 5454 4e4f 2053 0000de0 4542 544f 4843 5320 4948 2054 5546 4b43 0000df0 5245 4820 4f4f 4554 5352 4720 414f 5354 0000e00 2045 4152 4550 5420 5355 5948 4620 4e41 0000e10 594e 5546 4b43 5245 4120 5353 4f48 4552 0000e20 4220 4d55 4c43 5441 5020 4952 2047 5453 0000e30 4c59 2045 4f44 4747 2059 4f50 2054 5242 0000e40 4145 5453 4f4a 2042 4957 4c4c 4549 2053 0000e50 4f47 4f4e 5252 4845 4145 4b20 434f 204b 0000e60 5341 5753 5049 2045 4550 494e 2053 5546 0000e70 4b43 422d 5449 4843 5020 4e41 5954 4e20 0000e80 5741 5341 4948 4220 4f4f 4f4f 5342 5720 0000e90 4d4f 2042 494e 5050 454c 2053 4150 544e 0000ea0 4549 4320 434f 424b 5449 2045 5546 4b43 0000eb0 554e 4747 5445 4320 434f 534b 4355 454b 0000ec0 2052 564f 4d55 5020 4e55 414b 5353 5320 0000ed0 482e 492e 542e 202e 454e 5247 204f 4d53 0000ee0 5455 5420 4f57 4620 4e49 4547 5352 5720 0000ef0 5449 2048 4f54 474e 4555 4320 4f48 4441 0000f00 5220 534f 2059 4150 4d4c 4120 444e 4820 0000f10 5245 3520 5320 5349 4554 5352 4620 4749 0000f20 4947 474e 4c20 4d45 4e4f 5020 5241 5954 0000f30 5420 4957 4b4e 4120 5353 494c 4b43 5245 0000f40 4b20 4d55 494d 474e 4120 5353 4142 4747 0000f50 5245 4420 4349 4a4b 4955 4543 4320 4d41 0000f60 4c45 4f54 2045 4853 5449 2045 4557 2054 0000f70 5244 4145 204d 5243 4341 574b 4f48 4552 0000f80 4820 4d55 2050 4853 4d41 4445 4d41 2045 0000f90 5542 5454 554d 434e 2048 4145 2054 594d 0000fa0 4120 5353 4120 5353 5546 4b4b 2041 4947 0000fb0 4f47 4f4c 4120 5353 494b 5353 5245 4220 0000fc0 4f4f 4547 2052 5550 5353 2059 4146 5452 0000fd0 4220 5341 4154 4452 204f 4f44 4255 454c 0000fe0 4420 4e4f 2047 4f43 544f 5245 4220 4241 0000ff0 2059 4142 5454 5245 5220 4341 2059 4e4f 0001000 2045 5547 2059 4e4f 2045 414a 2052 4f57 0001010 2047 4944 4444 454c 4620 4952 4747 4b20 0001020 4e49 4142 554b 5020 524f 4f4e 4420 4f4f 0001030 5546 2053 5542 5454 554d 434e 4548 2052 0001040 5546 4b43 4f42 2059 4f44 4355 4548 4157 0001050 4646 454c 5320 4148 4556 2044 4542 5641 0001060 5245 4420 4349 444b 5049 4550 2052 4857 0001070 5230 2045 314e 4747 2041 2e46 2e55 2e43 0001080 204b 5542 5454 554d 4843 4620 4e49 4547 0001090 4652 4355 454b 2052 4320 4d55 5542 4242 00010a0 454c 4420 5049 4853 5449 4320 4948 204e 00010b0 4a45 4341 4c55 5441 5345 4620 4f4f 204b 00010c0 4f43 4b43 4146 4543 4220 574f 4c45 2053 00010d0 4b4b 204b 3446 4e4e 2059 5754 5441 4548 00010e0 4441 4320 4948 4b43 5720 5449 2048 2041 00010f0 4944 4b43 4c20 5a45 495a 2045 2d43 2d55 0001100 2d4e 2054 4944 4b43 4954 4b43 454c 2052 0001110 5546 4b43 5242 4941 204e 5242 4e55 5445 0001120 4554 4120 5443 4f49 204e 4853 5449 4142 0001130 4747 5245 5620 5249 4947 204e 5546 534b 0001140 3520 3148 2054 5544 4d4d 2059 4142 4c4c 0001150 5320 4355 494b 474e 5320 4948 4254 494c 0001160 504d 4220 5449 4843 4e49 2047 4142 4542 0001170 414c 444e 5420 4255 4947 4c52 4320 4152 0001180 2050 4f53 2d4e 464f 412d 422d 5449 4843 0001190 4d20 2052 4148 444e 2053 5543 534d 4f48 00011a0 5354 4c20 4d41 4145 5353 4e20 5a41 5349 00011b0 204d 4e4b 424f 4f4a 454b 2059 494d 4444 00011c0 454c 4620 4e49 4547 2052 5546 4b43 4445 00011d0 4320 4e55 4154 5353 4320 434f 534b 4355 00011e0 494b 474e 4320 494c 4654 4341 2045 2d43 00011f0 2d4f 2d43 204b 5055 4b53 5249 2054 494a 0001200 4747 5245 4f42 204f 454c 4843 3520 4948 0001210 2054 4f42 4f4f 4f4f 5342 5320 4948 5454 0001220 4e49 5347 5720 4948 4554 5020 574f 5245 0001230 4320 494c 5454 2059 494c 5454 5245 5420 0001240 5431 4620 4e49 4547 4652 4355 204b 554e 0001250 4544 4c20 4145 4854 5245 5220 5345 5254 0001260 4941 544e 5320 554f 4553 2044 5542 5454 0001270 4146 4543 4620 4b55 454b 5352 4120 5353 0001280 4f48 4531 5020 4f48 454e 4553 2058 5551 0001290 4d49 4b20 4b59 2045 4f53 2044 464f 2046 00012a0 4146 4747 544f 5320 5243 5745 4445 5020 00012b0 5349 2053 464f 2046 4950 5353 4445 4820 00012c0 5245 2050 414a 4b43 5341 2053 4142 4542 00012d0 2053 5543 544e 4142 2047 414a 4b43 4f20 00012e0 4646 5320 4948 4954 474e 2053 5553 4f4d 00012f0 4146 4942 5441 4843 5020 5355 4553 4420 0001300 4e4f 454b 5059 4e55 4843 4420 4349 204b 0001310 5543 4d4d 4e49 4620 4e49 4547 4952 474e 0001320 5920 4449 4620 4355 484b 4145 5344 4420 0001330 5741 4947 2d45 5453 4c59 2045 4154 494b 0001340 474e 5420 4548 5020 5349 2053 4552 5443 0001350 5355 4620 4741 5347 5420 5449 4549 2053 0001360 4152 4847 4145 2044 4157 4b4e 5245 5020 0001370 4f52 2044 5543 4d4d 4e49 2047 2d53 2d4f 0001380 2042 5543 204d 4843 4755 4547 2052 4f47 0001390 4444 4d41 454e 2044 554d 4854 4641 4355 00013a0 4b4b 5245 4420 4c49 4f44 2053 4f4e 4b4f 00013b0 2059 4954 5354 4420 4349 204b 4853 2059 00013c0 4f50 504f 4e55 4843 5245 4320 4d55 5453 00013d0 4941 204e 4153 424d 204f 4554 4241 4741 00013e0 4947 474e 5020 4749 5546 4b43 5245 5120 00013f0 4555 4645 5320 494e 4550 2052 4f43 4b43 0001400 4e53 4649 4546 2052 4c42 4341 204b 4f43 0001410 4b43 5220 5645 4555 4620 4355 204b 4f59 0001420 4d20 4d41 2041 4546 414d 454c 5320 5551 0001430 5249 4954 474e 5020 5355 5953 2053 5553 0001440 4349 4449 2045 4947 4c52 2053 454c 5441 0001450 4548 2052 5453 4152 4749 5448 4a20 4341 0001460 454b 2054 4f50 4e4f 4e41 2059 4146 2054 0001470 4147 4159 5353 5920 4145 5453 2059 5542 0001480 5453 2059 4f44 2d47 5546 4b43 5245 4e20 0001490 4d41 4c42 2041 4647 2059 5546 4b43 5055 00014a0 4620 4355 544b 594f 4d20 544f 4148 5546 00014b0 4b43 5a41 4a20 4755 5347 4d20 5341 5554 00014c0 4252 5441 4e49 2047 4c42 574f 4d20 4455 00014d0 5020 5341 5954 5620 524f 5241 5045 4948 00014e0 494c 2041 4e43 5455 5720 4e41 4a4b 424f 00014f0 5320 5845 2059 3048 4f4d 4220 5241 4c45 0001500 2059 454c 4147 204c 5546 4b43 4154 4452 0001510 2053 5546 4b43 4857 524f 2045 5341 5753 0001520 4441 4220 5449 4843 2059 4f42 4b4f 4549 0001530 5420 5449 4954 5345 4320 434f 534b 4355 0001540 534b 4420 4c31 3044 5020 4545 4550 2045 0001550 4c41 4241 4d41 2041 4f48 2054 4f50 4b43 0001560 5445 4220 5344 204d 4542 4645 4320 5255 0001570 4154 4e49 4320 454c 4556 414c 444e 5320 0001580 4554 4d41 5245 4320 434f 4941 204e 554d 0001590 4854 2041 4143 454d 204c 4f54 2045 5453 00015a0 4649 5946 4720 4941 4720 4e41 2047 4142 00015b0 474e 4420 474f 5947 5453 4c59 2045 4154 00015c0 4646 4a20 5a49 455a 2044 4954 4445 5520 00015d0 2050 5944 454b 4120 5353 4c43 574f 204e 00015e0 4942 4354 5448 5449 2053 4c50 4145 5553 00015f0 4552 4320 4548 5453 4320 4d55 454d 2052 0001600 4146 4e4e 4259 4e41 4944 2054 454a 4c4c 0001610 2059 4f44 554e 2054 4853 5449 4554 2052 0001620 5341 4653 4341 2045 4957 444e 574f 4c20 0001630 4349 454b 2052 454c 205a 4954 5454 4659 0001640 4355 454b 2052 5753 4e49 4547 2052 5550 0001650 5353 5059 554f 444e 5245 4220 4145 5453 0001660 4149 204c 5250 4e49 4543 4120 424c 5245 0001670 2054 4950 5245 4943 474e 4d20 4f4f 494c 0001680 2045 4f47 4b4b 4e55 5520 4952 414e 204c 0001690 4153 444e 4e20 4749 4547 2052 4147 4659 00016a0 4355 494b 5453 4720 5341 5953 4120 5353 00016b0 4f20 4752 2059 4353 4948 4f5a 5320 4554 00016c0 4d41 2059 4c43 4d49 5841 4c20 4241 4149 00016d0 4320 4f52 5454 2045 5243 5041 5950 4520 00016e0 414a 5543 414c 4954 4e4f 4f20 4156 5952 00016f0 4d20 4655 2046 4944 4556 2052 4146 594e 0001700 2059 524f 4147 4d53 4349 4e20 4749 4147 0001710 2048 4944 4b43 494d 4b4c 4720 5941 4f42 0001720 2042 4f48 2057 4f54 4b20 4c49 204c 5753 0001730 5341 4954 414b 5320 4f4c 4550 5420 5248 0001740 4545 4f53 454d 4220 4f4f 595a 4820 414f 0001750 2052 5543 4a4d 434f 454b 2059 4950 504d 0001760 5349 4b20 4f4f 4354 2048 4147 474e 4142 0001770 474e 5420 4157 5754 4641 4c46 2045 4843 0001780 4e49 204b 4157 4f5a 204f 4f42 4e4f 4147 0001790 4420 5530 4843 2045 5543 544e 4d20 5455 00017a0 5248 5546 4b43 4e49 2047 4c43 5431 5020 00017b0 4445 204f 4f43 4b43 554d 434e 2048 4f4d 00017c0 4854 5245 5546 4b43 4445 4820 4c4f 2059 00017d0 4853 5449 4320 4e55 5354 4620 4741 4f47 00017e0 5354 5620 4a41 5941 414a 2059 4156 4947 00017f0 414e 4d20 544f 4548 4652 4355 454b 5352 0001800 5320 4143 2047 4946 474e 5245 5546 4b43 0001810 4445 4720 544f 484f 4c45 204c 4c53 4145 0001820 455a 4320 494c 5354 5220 4945 4843 5420 0001830 5548 444e 5245 5543 544e 4a20 5349 204d 0001840 4f44 4d4d 5345 4220 534f 4d4f 2059 4146 0001850 4747 544f 4f43 4b43 4720 4e4f 4441 2053 0001860 5341 5353 4355 454b 2052 4944 4b4e 2053 0001870 4e41 5355 4b20 4f4e 4a42 434f 594b 4120 0001880 5353 4c42 5341 4554 2052 5542 4c4c 5554 0001890 4452 2053 4e4f 2045 5543 2050 5754 204f 00018a0 4947 4c52 2053 4f50 4e4f 4154 474e 4220 00018b0 494f 4b4e 4120 5353 5546 4b43 5245 4d20 00018c0 4c49 2046 5543 544e 494c 4b43 2020 4145 00018d0 2054 2041 4944 4b43 5720 4f48 4552 2053 00018e0 4142 4c4c 4b20 4349 494b 474e 5520 444e 00018f0 4552 5353 4e49 2047 4857 524f 4245 4741 0001900 4f20 4950 4d55 4920 4a4e 4e55 4220 4552 0001910 5341 2054 4154 4749 5720 4c49 594c 4120 0001920 5353 4548 4441 5720 4f48 5241 4620 4345 0001930 4c41 5420 5449 2049 5546 4b43 4f48 454c 0001940 4220 4f4f 2042 4854 4755 5020 4745 4947 0001950 474e 5420 574f 4c45 4548 4441 4220 4355 0001960 5445 2041 5943 4542 4652 4355 454b 2052 0001970 4548 544e 4941 4d20 4e4f 2047 4542 5441 0001980 5245 4320 4e55 5354 554c 2054 5551 4545 0001990 4852 4c4f 2045 5546 4b43 4e49 5320 554d 00019a0 5454 2059 4e49 4554 4352 554f 5352 2045 00019b0 5a55 2049 4c43 5449 4c20 4349 454b 2052 00019c0 494d 4b43 4320 494c 4654 4355 204b 4b53 00019d0 4741 4220 4e49 2054 4946 5453 5546 4b43 00019e0 4e49 5347 4320 4e55 5254 4741 5320 4f54 00019f0 454e 2044 5754 204f 4947 4c52 2053 4e4f 0001a00 2045 5543 2050 4946 5453 5546 4b43 4420 0001a10 4349 534b 414c 2050 4f42 4c4c 584f 5220 0001a20 4154 4452 4e20 4455 5449 2059 5546 4b43 0001a30 4142 2047 4353 4d55 5320 4948 4154 5353 0001a40 5320 4445 4355 2045 4950 5353 464f 2046 0001a50 5254 4e41 5353 5845 4155 204c 4f46 544f 0001a60 5546 4b43 5245 4820 4e41 2044 4f4a 2042 0001a70 5542 474e 4f48 454c 4c20 5355 2054 554d 0001a80 4646 5020 4655 2046 4550 4f59 4554 4220 0001a90 5341 4154 4452 5320 4f2e 422e 202e 4950 0001aa0 5353 4f2d 4646 4220 4c55 434c 4152 2050 0001ab0 5754 204f 4946 474e 5245 2053 4843 4c49 0001ac0 2d44 5546 4b43 5245 4420 4349 5a4b 5049 0001ad0 4550 2052 4353 4f52 5554 204d 4f56 4b44 0001ae0 2041 4c46 5345 4648 554c 4554 4a20 5245 0001af0 304b 4646 5020 4545 4420 554f 4843 4245 0001b00 4741 4120 5353 4620 4355 204b 5341 4d53 0001b10 4355 5355 4320 434f 414b 5353 4620 5520 0001b20 4320 4b20 4520 5220 5020 4445 504f 4948 0001b30 494c 4341 4320 434f 484b 4145 2044 4954 0001b40 5754 4e41 204b 4942 4354 4548 5352 4420 0001b50 554f 4843 2d45 4146 2047 4942 424d 534f 0001b60 4420 4349 574b 4948 5050 5245 5520 4952 0001b70 454e 4f20 4752 5341 204d 4f4d 4854 5245 0001b80 5546 4b43 4e49 5347 4820 4f4f 4354 2048 0001b90 4f44 2047 5453 4c59 2045 554b 534d 4420 0001ba0 4d49 4957 2054 5546 4154 414e 4952 5320 0001bb0 2148 202b 2e50 2e55 2e53 2e53 2e59 4820 0001bc0 204f 2d58 4152 4554 2044 4554 4452 4e20 0001bd0 4d49 4850 4d4f 4e41 4149 4120 5353 4857 0001be0 4c4f 2045 4f43 4b43 4620 4e4f 4c44 2045 0001bf0 494e 524d 444f 4220 4f52 4854 5245 5546 0001c00 4b43 5245 5320 4948 5454 4a20 4341 414b 0001c10 5353 5345 5020 4445 424f 4145 2052 4153 0001c20 4944 4d53 5520 4552 4854 4152 5020 414c 0001c30 2059 3142 4354 2048 5551 4349 594b 4620 0001c40 4741 4154 4452 4820 5245 494f 204e 5a41 0001c50 205a 5053 4e55 204b 3142 4337 2048 5544 0001c60 424d 5546 4b43 5020 4952 4b43 4120 5353 0001c70 4f4c 4556 2052 5453 4152 2050 4e4f 5320 0001c80 4943 5353 524f 4e49 2047 5542 4c4c 5445 0001c90 5620 4249 2045 4544 444e 4f52 4850 4c49 0001ca0 4149 4420 5249 5954 4820 5241 4344 524f 0001cb0 2045 4944 4b43 4c46 5049 4550 2052 4e4b 0001cc0 424f 4942 474e 4c20 494f 204e 3156 5247 0001cd0 2041 5546 4744 2d45 4150 4b43 5245 5420 0001ce0 5248 414f 4954 474e 5320 4c55 5254 2059 0001cf0 4f57 454d 204e 4944 4b43 4548 4441 2053 0001d00 4853 4741 4520 4552 5443 4420 4d55 2042 0001d10 5341 2053 4944 4b43 5546 4b43 4620 4741 0001d20 4547 2044 5548 204e 5754 4e55 2054 4547 0001d30 444e 5245 4220 4e45 4544 2052 5254 5341 0001d40 5948 5220 4545 4546 2052 4944 4b43 5349 0001d50 2048 5546 4b43 5754 5441 4620 4355 204b 0001d60 5550 5050 5445 4420 474f 4947 2045 5453 0001d70 4c59 2045 4346 4b55 5245 4d20 544f 4548 0001d80 4652 4355 534b 4120 5353 414a 4b43 5245 0001d90 4b20 4e55 2054 4548 4c4c 4120 5353 3048 0001da0 454c 4320 4330 534b 4355 454b 2052 4f42 0001db0 4c4c 4b4f 4420 4f4f 4853 4420 5249 4153 0001dc0 5320 4948 4354 4e55 2054 334a 4b52 4630 0001dd0 2046 534e 5746 4920 414d 4547 2053 4156 0001de0 2047 4556 554e 2053 4f4d 4e55 2044 4156 0001df0 4a2d 4a2d 4b20 4c49 204c 414d 5353 2041 0001e00 4142 5454 2059 4f42 2059 4f50 4352 4d48 0001e10 4e4f 454b 2059 414d 5453 5245 4142 2054 0001e20 3050 4e52 5020 4e49 4f4b 4420 5441 5245 0001e30 5041 2045 4f43 4e4f 414e 5353 5320 4948 0001e40 4e5a 5449 5020 524f 204e 4147 4659 4355 0001e50 204b 4c43 5449 5954 4420 4c31 4f44 4220 0001e60 4749 4547 2052 4f43 4b43 4e4b 434f 454b 0001e70 2052 4148 4452 4f20 204e 4f44 4355 4548 0001e80 4320 4952 454b 2059 4144 4f47 2053 4952 0001e90 4d4d 4e49 2047 4146 5452 4e4b 434f 454b 0001ea0 2052 4142 5942 4a20 4955 4543 4720 4c4f 0001eb0 4544 204e 4853 574f 5245 4e20 4749 4147 0001ec0 4220 4e55 4147 5020 4e55 4e41 2049 4f42 0001ed0 544f 2059 5543 4e4e 4c49 4e49 5547 2053 0001ee0 5550 4942 2053 4f42 444e 4741 2045 4556 0001ef0 5451 4241 454c 4120 5353 4a2d 4241 4542 0001f00 2052 4f43 4b43 5553 4543 2052 5542 5454 0001f10 4f48 454c 4220 4e45 4544 2052 5542 5454 0001f20 422d 4e41 2047 4947 4c52 4f20 204e 4f54 0001f30 2050 4f4e 434e 2045 4542 5945 544f 4843 0001f40 4d20 5445 2048 554d 4854 5245 5546 4b43 0001f50 5245 4620 4952 4747 2041 4f43 4d4d 4549 0001f60 5720 4945 4452 204f 5546 4b43 4548 4441 0001f70 4a20 5041 2053 4f48 2057 4f54 4d20 5255 0001f80 4544 2052 4f44 4255 454c 494c 5446 4820 0001f90 4d45 2050 4147 4459 204f 4f4d 4854 4641 0001fa0 4355 454b 2052 4f4d 4854 5245 5546 4b43 0001fb0 414b 4220 474f 4e41 5320 4148 4747 4e49 0001fc0 4220 5455 4654 4355 204b 4f5a 504f 4948 0001fd0 494c 2041 4841 4c4f 2045 5254 4249 4441 0001fe0 5349 204d 314e 4747 5245 4320 552e 4e2e 0001ff0 542e 5820 2058 4e41 4c49 4e49 5547 2053 0002000 5453 4152 5050 4441 204f 4150 4445 504f 0002010 4948 454c 4e20 4749 4c47 2045 3048 304d 0002020 4d20 4655 2046 4353 4552 2057 4944 4b43 0002030 4157 2044 4946 5453 4620 4355 204b 4946 0002040 5453 5546 4b43 4e49 2047 4153 444e 494e 0002050 4747 5245 4220 4f4f 4554 2045 4944 4b4e 0002060 4720 444f 4d41 494e 2054 4144 4b52 4549 0002070 4d20 4e45 5453 5552 5441 4f49 204e 5247 0002080 4e49 4f47 5320 5254 5049 4320 554c 2042 0002090 4853 4741 4947 474e 5920 4f41 2049 4f42 00020a0 4e4f 2047 4853 544f 2041 4546 4c4c 5441 00020b0 2045 414a 4747 2049 5345 4f43 5452 4320 00020c0 434f 534b 5320 554c 2054 4144 4e4d 5449 00020d0 4e20 424f 4f4a 4b43 2059 4554 5441 4720 00020e0 4e41 4247 4e41 4547 2044 5545 554e 4843 00020f0 5020 4441 5944 4b20 414c 204e 4550 494e 0002100 454c 4c20 5345 4f42 5320 4948 4254 4552 0002110 5441 2048 2d53 2d48 2d49 2054 554a 4b4e 0002120 4549 4220 4c45 454c 444e 5120 4555 5245 0002130 2053 2d43 2d30 2d43 204b 4f53 204e 464f 0002140 4120 4220 5449 4843 4e20 4d59 4850 4d4f 0002150 4e41 4149 4620 414f 2048 4f48 4f4d 5945 0002160 5720 5349 4145 5353 5345 4b20 4f4e 2042 0002170 5943 4542 4652 4355 5420 5241 2044 5347 0002180 4f50 2054 5553 4b43 5720 4654 5020 4e41 0002190 4f4f 4843 4e20 4441 5420 5345 4554 2045 00021a0 4f4d 204f 4f4d 204f 4f46 204f 4f46 204f 00021b0 4153 444e 4142 2052 5546 4b43 4e49 2047 00021c0 5350 4359 4f48 5220 4345 5554 204d 4942 00021d0 4354 2048 4f50 454c 5320 4f4d 454b 2052 00021e0 4142 4c4c 4c20 4349 494b 474e 4f20 4752 00021f0 4e41 4320 4e55 4854 4e55 4554 2052 4a45 0002200 4341 4c55 5441 4445 4320 4f4c 4556 2052 0002210 4c43 4d41 5350 4420 4355 4548 4b20 4e55 0002220 4c49 4e49 5547 2053 4144 4e4d 4720 5941 0002230 5320 5845 5320 4355 494b 474e 4e20 4e49 0002240 594e 5020 5349 4553 2053 4144 4f47 4620 0002250 4355 484b 5245 4b20 4f4e 4542 444e 5320 0002260 554b 4c4c 5546 4b43 4120 5353 4142 2047 0002270 4c44 4b43 5320 5250 4145 2044 454c 5347 0002280 4620 4e49 4547 4252 4e41 2047 4552 5445 0002290 5241 2044 5543 544e 4f48 454c 4720 444f 00022a0 4420 4d41 204e 4e55 4c43 4645 4355 454b 00022b0 2052 4843 544f 2041 4142 5347 5320 5845 00022c0 4a20 4e55 4c47 4245 4e55 594e 4220 4749 00022d0 4142 5453 5241 2044 4c53 5641 2045 5548 00022e0 5353 2059 5242 4145 5453 4f4c 4556 2052 00022f0 494e 4747 5233 4320 434f 534b 4355 454b 0002300 5352 4420 4349 534b 4355 454b 2052 4a45 0002310 4341 4c55 5441 4e49 5347 4220 4755 4547 0002320 2052 4f44 4b4e 5945 5020 4e55 4843 4d20 0002330 3534 4554 4252 5441 2045 4546 4c4c 5441 0002340 4f49 4320 504f 4f52 414c 4e47 4149 5320 0002350 5254 5041 4e4f 4620 4355 544b 5241 2054 0002360 4e55 4944 5345 4120 4550 4853 5449 4d20 0002370 4e49 4547 3220 4720 5249 534c 3120 4320 0002380 5055 4d20 4449 4547 2054 4f43 4b43 4f4d 0002390 474e 5552 4c45 4220 4d55 5546 4b43 4820 00023a0 4f4f 414b 2048 4944 4b43 4f4d 474e 5245 00023b0 4620 4356 204b 4850 4355 204b 414d 5453 00023c0 5245 422d 5441 2045 414b 4b57 5920 424f 00023d0 4f42 5320 4d26 5320 5248 4d49 4950 474e 00023e0 4620 4355 534b 5020 4952 4b43 4554 5341 00023f0 5245 4820 544f 4320 5241 204c 4843 434f 0002400 4c4f 5441 2045 4f52 4553 5542 5344 4620 0002410 5855 5230 4a20 4341 4f4b 4646 5220 4d49 0002420 414a 2057 5341 4653 4341 5345 4120 5353 0002430 4e20 424f 4548 4441 4120 5352 4845 4c4f 0002440 2045 554e 424d 554e 5354 4620 5855 4c20 0002450 5345 4942 4e41 4620 4f4f 454b 2052 5243 0002460 4241 2053 4f50 414c 4b43 5020 5548 204b 0002470 494d 5353 4f49 414e 5952 5020 534f 5449 0002480 4f49 204e 5053 4f4f 4547 4720 5049 4f50 0002490 4e20 4749 4e2d 474f 4320 4259 5245 5546 00024a0 4b43 5220 4d55 4220 5345 4954 4c41 5449 00024b0 2059 5546 204b 4f57 2050 414d 5435 5245 00024c0 4142 4554 4320 584f 4320 4d55 4853 544f 00024d0 4320 434f 2d4b 5553 4b43 5245 4620 4e49 00024e0 4547 4652 4355 534b 4b20 4152 5455 4320 00024f0 4952 5050 454c 4420 5441 2045 4152 4550 0002500 4220 4e41 2047 4f28 454e 5327 2029 4f42 0002510 2058 4f57 444f 2059 4954 2054 4157 4b4e 0002520 4b20 4e4f 5544 534d 4720 4654 204f 4146 0002530 4b43 5320 4c50 4f4f 4547 4d20 4f4f 4553 0002540 4620 4741 5546 4b43 5245 4f20 5556 534d 0002550 4220 4f4c 4a57 424f 4320 434f 454b 4559 0002560 5720 4545 494e 2045 4c43 474f 4f57 2047 0002570 4942 4354 4948 204e 4142 5453 5241 5344 0002580 4820 4d4f 204f 4552 4f4e 2042 4950 5353 0002590 4c46 5041 2053 554c 5453 2059 554d 4646 00025a0 4944 4956 474e 4720 4e49 4547 2052 554b 00025b0 4d4d 5245 4120 4d32 5220 534f 2059 4150 00025c0 4d4c 5420 5431 4954 5345 4220 4f4c 4a57 00025d0 424f 2053 4f43 204b 5546 4b43 5245 2053 00025e0 5542 5454 4c50 4755 4220 4e4f 5245 2053 00025f0 504f 4149 4554 4620 4c45 4354 4548 2052 0002600 414d 4958 5620 5849 4e45 5120 4555 4641 0002610 4720 524f 4745 5341 204d 4954 5454 4549 0002620 2035 5943 4542 4652 4355 454b 5352 4720 0002630 4c4f 494c 4f57 2047 5548 504d 4445 4420 0002640 554f 4843 2033 554d 4854 5245 4420 554f 0002650 4843 4245 4741 2053 4546 4b43 5245 4720 0002660 5941 4553 2058 5341 5753 4f48 4552 4620 0002670 4358 204b 4e41 4c41 4920 504d 4c41 5245 0002680 4220 4f4c 444f 4c43 4141 2054 2d4d 5546 0002690 4b43 4e49 2047 4f44 494d 414e 5254 5849 00026a0 4d20 3541 4554 4252 2038 4f53 4f44 594d 00026b0 4320 4e55 5354 4355 454b 2052 524f 4c41 00026c0 5020 4b41 2049 4142 4652 4341 2045 4c43 00026d0 5449 524f 5349 4620 4552 4645 4355 204b 00026e0 4146 4747 4e49 2047 4f42 424f 2053 304d 00026f0 3046 5020 4148 4c4c 4349 4120 3435 4220 0002700 4749 5420 5449 2053 5546 4b43 5542 5454 0002710 4420 4349 534b 4355 494b 474e 5020 4f4f 0002720 4350 5548 4554 4820 5649 4220 4441 5546 0002730 4b43 5720 4e45 4843 4120 5353 4950 4152 0002740 4554 5020 4f4f 204e 494e 4147 4f42 204f 0002750 5546 4b43 454d 5441 4420 5049 4853 5049 0002760 4120 5353 462d 4355 454b 2052 4f48 4b4f 0002770 5245 4720 4548 2059 5341 4253 4e41 5347 0002780 4820 4e4f 454b 2059 4154 5452 5320 4950 0002790 204b 5542 204d 4f42 2059 4e41 4c41 4e41 00027a0 494e 2045 5341 4353 434f 204b 4c42 574f 00027b0 5320 454b 5445 4220 484f 4e55 204b 4946 00027c0 474e 5245 5546 4b43 4e49 2047 4d53 5241 00027d0 4154 5353 5345 4b20 4f4e 2042 4e45 2044 00027e0 4f44 4747 4549 5453 4c59 2045 5543 2054 00027f0 4f52 4550 4420 4349 574b 444f 4220 5742 0002800 4620 4e41 594e 4c46 5041 2053 5542 4747 0002810 5245 2059 3541 2035 4546 434c 4548 2052 0002820 4150 4e57 4320 494f 4154 204c 524f 4147 0002830 4953 204d 4f53 5355 2045 4f42 424f 2059 0002840 4f4d 4854 5245 5546 4b43 5245 4b20 4f4e 0002850 4542 2044 4f48 2054 4843 4349 204b 4c42 0002860 574f 5920 554f 2052 4f4c 4441 4120 5353 0002870 4150 4b43 5245 5320 4654 2055 4853 5449 0002880 4954 5345 2054 5341 5053 5055 4950 5345 0002890 4620 4355 4d4b 2045 4550 494e 4c41 5320 00028a0 5243 4455 5620 3431 5247 2041 5948 454d 00028b0 204e 4152 4550 2052 414d 5453 5245 4142 00028c0 4954 4e4f 2053 3042 4230 2053 4548 4245 00028d0 5720 4952 4b4e 454c 2044 5453 5241 4946 00028e0 4853 4420 4d55 5341 2053 4954 4b4e 454c 00028f0 4220 414f 474e 4320 494c 2054 4553 4d41 0002900 4e45 4420 4c49 4f44 4420 4d41 454e 2044 0002910 4853 5449 4954 474e 4220 4145 454e 2052 0002920 4f56 4559 5255 4620 4c45 4354 2048 5546 0002930 4b43 454d 4148 4452 5420 4152 504d 4220 0002940 5341 4954 414e 4f44 5020 4345 454b 2052 0002950 4f42 4f4f 5342 4220 4e4f 2047 4146 4247 0002960 4741 4220 5455 2054 4c53 5455 2053 5341 0002970 5353 4948 2054 4853 5449 4954 5245 4b20 0002980 4b49 5345 4a20 4941 424c 4941 2054 414a 0002990 4b43 4f48 454c 4320 4e55 5354 4349 454c 00029a0 4620 4552 4b41 5546 4b43 4620 4455 4547 00029b0 5020 4341 454b 2052 4547 2059 4944 454b 00029c0 4220 4e41 4947 474e 5320 454d 4d47 2041 00029d0 5547 4f52 4620 4355 534b 4954 4b43 5020 00029e0 5349 4953 204e 4f4d 4f52 204e 4546 494e 00029f0 4e41 5620 4c55 4147 2052 5550 5453 5320 0002a00 4948 4142 4952 4620 4741 544f 2053 4f4d 0002a10 4e55 2044 464f 5620 4e45 5355 4220 4145 0002a20 4556 2052 494c 5350 4220 2b49 4843 4d20 0002a30 4e49 4547 2052 4944 4b43 2053 4554 5453 0002a40 5349 5020 4e41 5953 4d20 544f 4148 5546 0002a50 4b43 2053 4853 5449 4445 5320 4948 202b 0002a60 414d 534d 4120 5353 4f48 454c 2053 554e 0002a70 5354 4341 204b 4552 5443 4c41 5320 5845 0002a80 4155 204c 454c 425a 4149 534e 5720 4749 0002a90 4547 2052 4f50 4c4c 434f 204b 4353 4f52 0002aa0 2054 4f50 4352 2048 4f4d 4b4e 5945 4d20 0002ab0 5341 4554 4252 5441 2033 4c42 574f 4d20 0002ac0 2045 4f46 4441 5720 4f48 4552 4146 4543 0002ad0 4720 532d 4f50 2054 4550 454e 5254 5441 0002ae0 4f49 204e 4152 4947 474e 4220 4e4f 5245 0002af0 4120 5758 554f 444e 5320 3148 2054 4850 0002b00 4c41 494c 4620 4355 594b 554f 4320 434f 0002b10 464b 4355 454b 2052 454a 4b52 4f20 4646 0002b20 4620 4355 4e4b 5455 5320 454d 2047 4546 0002b30 434c 2048 5542 4354 4448 4b49 2045 4857 0002b40 5449 5945 4220 4f4f 5954 4320 4c41 204c 0002b50 5f41 5f53 2053 4c42 4d55 4b50 4e49 4920 0002b60 434e 5345 2054 4854 5552 5453 5420 4957 0002b70 4b4e 4549 5420 4b4f 2045 4f43 4b43 494c 0002b80 4b43 5245 4220 4c4f 4f4c 4b43 5420 5449 0002b90 5546 4b43 5020 5355 5953 494c 4b43 4e49 0002ba0 2047 4e55 4557 2044 4148 4452 4f43 4552 0002bb0 4553 2058 4857 524f 4445 4220 4b55 414b 0002bc0 454b 4420 5249 5954 5320 4e41 4843 5a45 0002bd0 5020 5349 4553 2052 4942 4354 4548 205a 0002be0 4954 2054 414a 4b43 4f2d 4646 4a20 4749 0002bf0 4241 4f4f 5420 5345 4954 4143 204c 4156 0002c00 494c 4d55 4120 5353 4820 4c4f 2045 4f42 0002c10 454e 2044 5345 4f53 4248 4545 4220 4f4c 0002c20 2057 4f4a 2042 4559 4c4c 574f 5320 4f48 0002c30 4557 5352 4c20 5a45 4f42 5320 4948 4654 0002c40 4355 204b 5543 204d 5544 504d 5453 5245 0002c50 4220 4152 4320 4341 2041 4143 4b57 4d20 0002c60 5341 4554 4252 5441 4e49 2047 4853 4d45 0002c70 4c41 2045 4552 4154 4452 4720 444f 442d 0002c80 4d41 454e 2044 4553 534b 4220 5449 4843 0002c90 4445 4c20 4933 432b 2048 4f46 424f 5241 0002ca0 4c20 5a45 4f42 2053 4857 524f 4845 554f 0002cb0 4553 4320 434f 534b 4355 204b 4f50 4e4f 0002cc0 4e41 2049 4557 4445 4320 4e55 4c54 4349 0002cd0 454b 2052 5542 4c4c 4853 5449 4554 2044 0002ce0 4147 474e 422d 4e41 2047 4942 4553 5558 0002cf0 4c41 4220 5455 4843 5944 454b 4220 4e55 0002d00 2047 4f48 454c 4220 4c55 534c 4948 5354 0002d10 5020 544f 5954 4320 4d55 4220 4755 4547 0002d20 4552 2044 5552 504d 4152 4d4d 5245 4220 0002d30 5a41 4f4f 534d 4720 414f 4354 2058 4f4d 0002d40 4854 4641 4355 204b 4f56 494d 2054 5341 0002d50 4853 4c4f 2045 5341 5753 5049 5345 4320 0002d60 434f 4e4b 4755 4547 2054 4843 2d49 4843 0002d70 2049 414d 204e 4853 5449 4944 4b43 4a20 0002d80 5245 414b 5353 4220 4d41 4f50 2054 4f46 0002d90 544f 494c 4b43 5245 4420 504f 5945 4320 0002da0 504f 5320 4d4f 2045 4f57 444f 4320 4d55 0002db0 2053 5546 4b4b 5245 4320 4d55 4c53 5455 0002dc0 5020 4445 504f 4948 494c 2041 3057 5330 0002dd0 2045 5244 2059 5548 504d 4120 5252 4553 0002de0 4320 4f4f 4843 2059 4557 4e49 5245 4e20 0002df0 4d59 4850 204f 5241 4f45 454c 4620 4355 0002e00 574b 4441 4320 504f 4f52 4850 4c49 4149 0002e10 4220 4c41 204c 4147 2047 5241 4553 4d20 0002e20 5455 4148 4546 4b43 5245 4620 4355 4f4b 0002e30 4646 5220 5645 5245 4553 4320 574f 4947 0002e40 4c52 4420 474f 5947 532d 5954 454c 4d20 0002e50 4655 4446 5649 5245 4320 434f 534b 4355 0002e60 204b 5320 4948 4854 4145 2044 454e 4445 0002e70 5420 4548 4420 4349 204b 4143 534d 554c 0002e80 2054 5546 4b43 4f4d 4b4e 5945 4220 4d55 0002e90 4c42 4645 4355 204b 4f43 4e52 4f48 454c 0002ea0 4320 434f 424b 4f4c 4b43 4320 4948 434e 0002eb0 2053 454c 5a5a 2059 414d 5546 4c47 2059 0002ec0 454a 4b52 4720 5341 2048 4853 5449 5320 0002ed0 4d45 4e45 4720 4149 544e 4320 434f 204b 0002ee0 4f4d 4f46 4d20 4e45 4553 2053 4548 5052 0002ef0 2059 4857 524f 2045 4146 4747 5449 2054 0002f00 4f47 4144 4e4d 4220 4c55 204c 4853 5449 0002f10 4220 5355 2054 2041 4f4c 4441 4820 544f 0002f20 4553 2058 4550 454e 5254 5441 2045 3043 0002f30 4b43 4120 415a 455a 204c 5551 4545 4252 0002f40 4941 2054 5542 4c4c 4853 5449 4320 4f2e 0002f50 432e 4b2e 202e 4944 4b43 4542 5441 5245 0002f60 2053 4850 4e4f 2045 4553 2058 4f50 464f 0002f70 4b20 4f4f 4843 5345 4220 444f 4c49 2059 0002f80 2441 4824 4c4f 2045 4d4c 4f41 4320 4d55 0002f90 5547 5a5a 454c 2052 4142 4f5a 474e 5341 0002fa0 4e20 424f 4f4a 454b 2059 5552 4b53 2049 0002fb0 4942 4354 4148 5353 4620 4355 204b 4f59 0002fc0 2055 4154 504d 4e4f 4320 4f48 2043 4349 0002fd0 2045 5550 4b4e 2059 3144 4b43 5720 4948 0002fe0 205a 5543 544e 494c 4b43 5245 2020 4157 0002ff0 4b4e 4320 4e55 4c49 4e49 5547 2053 4542 0003000 5245 5120 4555 5245 204f 4959 4646 2059 0003010 4142 4652 4146 4543 4120 414e 534c 5845 0003020 4120 5353 5243 4341 454b 2052 494b 4b4e 0003030 2059 4942 4452 4f4c 4b43 5720 4445 4947 0003040 2045 4544 5045 4854 4f52 5441 5320 5254 0003050 4b4f 2045 4146 4543 5546 4b43 5245 4420 0003060 4d55 5342 4948 2054 4944 4b43 4142 2047 0003070 4c42 4f4f 5944 4820 4c45 204c 4c46 4d41 0003080 5245 4820 4f4f 4843 4520 414a 5543 414c 0003090 4954 474e 5320 5243 5745 4e49 2047 454a 00030a0 4b52 464f 2046 4f54 5353 5245 4520 414a 00030b0 554b 414c 4554 4220 4545 2046 5543 5452 00030c0 4941 534e 4620 4355 464b 4341 2045 5550 00030d0 4f54 4320 434f 534b 4f4d 454b 5420 5355 00030e0 2048 5754 5441 494c 5350 4620 4355 494b 00030f0 474e 2053 4f44 4747 4e49 4320 4152 4b43 0003100 4620 4355 2d4b 5341 2053 4944 474e 454c 0003110 5120 4555 5245 4720 4f52 4550 4320 4e55 0003120 494e 2045 5550 4542 2053 414a 4c49 4220 0003130 4941 2054 4154 5453 2045 594d 4820 4d41 0003140 4620 414c 2050 4f43 4b43 414d 5453 5245 0003150 4220 4152 5353 4549 4552 4c20 5a45 495a 0003160 5345 4f20 4152 4c4c 2059 4542 5441 4f59 0003170 5255 454d 5441 5020 4952 4b43 2053 4146 0003180 4943 4c41 4520 5458 5341 2059 494e 4747 0003190 5a41 4d20 2d4f 4f46 4620 4e49 4547 4652 00031a0 4355 204b 4820 4d4f 444f 4d55 5342 4948 00031b0 2054 4f43 4b43 5320 4355 454b 2052 5543 00031c0 544e 5546 4b43 5245 5320 4f50 4b4f 4220 00031d0 4f4c 444e 2045 4e4f 4220 4f4c 444e 2045 00031e0 4341 4954 4e4f 4420 474f 4947 474e 4a20 00031f0 4749 4147 4f42 204f 4944 4b43 4548 4441 0003200 5420 5557 544e 5245 4d20 544f 4148 5546 0003210 4b43 5245 2053 5543 204d 5547 5a5a 454c 0003220 2052 434f 4f54 5550 5353 2059 5543 544e 0003230 494c 4b43 4220 4c41 424c 4741 4420 474f 0003240 5947 5320 5954 454c 4820 414f 4552 4c20 0003250 4f4f 454e 2059 4146 4654 4355 204b 4f44 0003260 474e 5420 5449 5954 4157 4b4e 4120 5455 0003270 204f 5245 544f 4349 4320 4e55 594e 4620 0003280 552d 432d 4b2d 4b20 4e55 414a 4220 4749 0003290 4b20 4f4e 4b43 5245 2053 4f4e 2042 4f47 00032a0 4b4f 4620 4355 454b 5352 4355 454b 2052 00032b0 414d 5453 5245 3842 4720 5249 204c 4e4f 00032c0 4b20 4f4e 4842 4145 2044 4150 544e 4549 00032d0 2053 4152 4550 2044 454d 534e 5254 4155 00032e0 4554 4320 4552 4d41 4950 2045 5543 204d 00032f0 5246 4145 204b 4544 4747 204f 5546 4b43 0003300 4820 4c4f 2045 5550 5353 4220 4e41 4547 0003310 2052 4857 5230 4645 4341 2045 5542 5454 0003320 462d 4355 454b 2052 4f42 5a4f 2045 4f4c 0003330 494c 4154 4620 414c 5350 4620 4f4f 4654 0003340 4355 204b 4853 5449 4e49 2047 4548 4542 0003350 4220 4749 4220 414c 4b43 4720 5941 4f4c 0003360 4452 4220 4c4f 4f4c 4b43 2053 4350 2050 0003370 4f43 534b 4355 414b 5220 4d49 4f4a 2042 0003380 2d52 4154 4452 5420 5449 5954 5420 4157 0003390 5454 2059 4f43 4b43 4f48 534c 4554 2052 00033a0 554c 5453 4e49 2047 554d 4854 4641 4355 00033b0 414b 205a 414d 5453 5245 4142 4954 4e4f 00033c0 4320 4552 4954 204e 5241 4f45 414c 5320 00033d0 4948 205a 554e 2054 4153 4b43 4120 5353 00033e0 4f4a 4b43 5945 4820 454f 2052 4f50 594e 00033f0 4c50 5941 4420 4d55 4342 4e55 2054 5341 0003400 4d53 4e55 4843 5245 5020 5552 4544 4320 0003410 4e55 544e 2054 4954 5454 4659 4355 204b 0003420 4554 5453 5345 4420 4d55 4142 5353 5345 0003430 4b20 4f4e 4542 4441 4920 5041 5320 4143 0003440 2054 4e53 574f 4142 4c4c 4e49 2047 4542 0003450 5341 4954 4c41 5449 2059 454e 4e4f 5a41 0003460 2049 4950 504d 5320 5554 4950 2044 5553 0003470 4b43 4445 5420 4941 544e 4445 4c20 564f 0003480 2045 4d4f 2047 4f44 4355 4548 2059 5543 0003490 544e 5546 4b43 4120 5353 5345 4620 4b55 00034a0 5245 4620 4b55 4957 2054 554c 4542 4120 00034b0 5353 5541 544c 4420 4349 524b 5049 4550 00034c0 2052 4e41 4c41 4320 4d55 5544 504d 4620 00034d0 5543 204b 5546 4b4b 4e49 4320 4548 5453 00034e0 4349 454c 4320 434f 4e4b 534f 2045 4f42 00034f0 2044 4146 5453 5546 4b43 4820 4f4f 4554 0003500 2052 4942 5543 4952 554f 2053 4948 4c54 0003510 5245 5320 4e41 4c44 5245 5020 4255 2045 0003520 4f47 4b4f 2053 4f43 4143 4e49 2045 4f43 0003530 4b43 554d 434e 4548 2052 4755 594c 4220 0003540 5455 4654 4355 454b 2052 4f44 434f 4248 0003550 4741 5520 4f52 4850 4c49 4149 4320 4e55 0003560 4654 4341 2045 494b 454b 4220 4d4f 2044 0003570 4f43 4646 4e49 4420 444f 4547 2052 5254 0003580 4d55 4550 2044 574b 4649 5020 5548 4b4b 0003590 4e49 2047 4c53 4741 4220 4d55 4920 4542 00035a0 4952 4e41 5320 414c 2050 4944 494c 4147 00035b0 2046 4f43 4b43 5542 4752 5245 4320 434f 00035c0 204b 4f50 4b43 5445 5320 4948 5454 2059 00035d0 4542 5241 4544 4344 414c 204d 4850 4b55 00035e0 454b 2044 4944 474e 454c 4542 5252 4549 00035f0 2053 4942 5447 5449 2053 4944 4b43 4820 0003600 4145 2044 4146 5452 4220 5241 2046 5552 0003610 4242 5349 2048 4f4d 3046 4420 4349 464b 0003620 4341 2045 414e 5050 2059 5341 5253 4e41 0003630 4547 2052 5943 4542 4652 4355 494b 474e 0003640 3220 3147 2043 5858 2058 4f4d 4854 4641 0003650 4355 414b 5020 5341 4954 2045 4c43 4e55 0003660 4547 5320 4948 5354 4154 4e49 4420 4349 0003670 2d4b 5349 2048 4554 5a45 5720 5349 4145 0003680 5353 4320 434f 574b 4641 4c46 2045 4944 0003690 4b43 5242 4941 204e 4143 574d 4f48 4552 00036a0 4120 3535 4f48 454c 4d20 5341 434f 4948 00036b0 5453 5320 5243 414f 2054 5550 4942 2043 00036c0 4f43 4b43 4d53 5449 2048 4144 4e52 4a20 00036d0 4e55 594b 4320 4e55 4c54 4349 494b 474e 00036e0 4420 4c49 574c 4545 2044 5250 534f 4954 00036f0 5554 4554 5020 5245 4556 5352 4f49 204e 0003700 4950 5353 4445 4f20 4646 4f20 4752 5341 0003710 4d49 2053 4f44 494d 414e 4954 4e4f 4220 0003720 4145 454e 5352 4120 2424 4720 444f 4144 0003730 4e4d 554d 4854 4641 4355 454b 2052 4142 0003740 4542 4120 414e 504c 4f52 4542 4120 5353 0003750 494e 4747 5245 4e20 424f 4a20 4b4f 5945 0003760 4d20 544f 4548 4652 4355 494b 204e 454d 0003770 414e 4547 4120 5420 4f52 5349 4620 4741 0003780 4120 5353 494c 4b43 4320 5241 4550 4d54 0003790 4e55 4843 5245 4420 4c4f 4543 5454 4320 00037a0 4948 4b4e 2059 4f42 4f4f 4f4f 4f4f 5342 00037b0 4720 414c 534e 4620 5441 5546 4b43 5245 00037c0 4c20 494f 534e 5420 5345 4554 4a20 5245 00037d0 2d4b 464f 2046 4f48 4f4d 5245 544f 4349 00037e0 4820 4d55 4950 474e 4420 4e49 4c47 4245 00037f0 5245 5952 4820 5241 2044 4f43 4552 4220 0003800 5241 4e45 4b41 4445 4220 4749 5542 5454 0003810 4e20 4441 2053 544d 5248 5546 4b43 5245 0003820 5320 4948 5354 4820 454f 5a20 4f4f 4850 0003830 4c49 2045 5542 4d4d 5245 4820 4d4f 5945 0003840 4320 4d55 5544 504d 5453 5245 5320 5349 0003850 5953 5020 5349 2053 4541 4c4f 5355 4620 0003860 4e49 4547 4652 4355 454b 5352 4720 4148 0003870 2059 5546 574b 4948 2054 5242 4145 5453 0003880 2053 4f4d 4854 4641 4355 454b 2044 4946 0003890 5453 2059 4950 5353 4e49 2047 4f4d 4854 00038a0 4641 4355 494b 474e 5720 4e41 2047 5245 00038b0 544f 4349 5320 4948 4254 4741 4420 4349 00038c0 2d4b 4e53 4545 455a 4220 5455 4254 4e41 00038d0 2047 4f42 4557 204c 4146 4e4e 2059 4353 00038e0 4f52 2047 4853 5449 5546 4c4c 4820 524f 00038f0 594e 4620 5349 4554 2044 4146 4749 2054 0003900 4843 444f 5345 5420 4749 5448 5720 4948 0003910 4554 4c20 5345 4942 4e41 2053 4e41 4c41 0003920 4c20 4145 414b 4547 4220 4149 4354 2048 0003930 5845 4154 5943 5420 4545 5354 4220 4145 0003940 4556 2052 4c43 4145 4556 2052 4857 524f 0003950 4845 504f 4550 2052 4f43 4d4b 4e55 4843 0003960 5245 4620 555f 435f 4b5f 4820 5345 4548 0003970 4520 414a 5543 414c 4554 4320 4d55 4154 0003980 5452 4420 5552 4b4e 4220 4c55 444c 4b49 0003990 2045 5546 4b43 5420 4f52 4850 2059 4956 00039a0 5242 5441 524f 5720 4f48 4152 494c 4943 00039b0 554f 2053 4142 474e 5242 534f 5020 5355 00039c0 5953 5020 4c41 4341 2045 4f4c 4556 414d 00039d0 494b 474e 4620 4f4f 2054 4546 4954 4853 00039e0 5720 4545 4557 2045 0000 0000 00039eb
I’m still not having any problem.
OK, one final step. Let’s open it in a text editor:

Hmmm. This time I think opinions might vary.
To me the idea of an “offensive word” doesn’t really make any sense. A word is just a sequence of letters. I’m a computer guy, so to me it’s just a sequence of bytes. But I don’t think any word can be said to be offensive any more than we could claim that the letters in that word are also offensive. And I don’t think we should ban the letter “f”.
It’s the intention and meaning that we derive from the word that matters – the way we read it, not the word itself. The first image is innocuous because you are looking at that stream of bytes as a bitmap image. In the last one, you’re parsing it as english, and it causes a very different reaction. But even then, there’s no hate in a list of “bad words” that I pulled off the internet. I’d argue that the final image is precisely as offensive as the first two because it’s just a list that I pulled off the net. Nobody yelled this at anybody. It wasn’t used for a hateful purpose. Therefore it’s innocuous.
The point is that we should look for the message people are trying to convey when they use a word before we have an emotional reaction to the word itself. I’ll grant that certain words do cause real problems for some people, and that certain words have been used historically in very hateful ways, but that doesn’t necessarily mean that every possible use of that word is negative. There are indeed certain words that might currently be almost entirely negative, but that won’t necessarily always be the case, and it might not be the case all over the world now, and it certainly doesn’t apply to every word that has been used, for example, as a slur.
Then there’s the whole “freedom of expression should trump the right to not be upset” argument, wherein I will argue that there is exactly one thing that the muricans did actually – wait for it, I’m gonna say it – The Americans did get freedom of speech right. Or at least, pretty close. But that’s a whole other wall of text.
I just thought this was an interesting demonstration of how your perception of data can change, depending on how you look at it ![]()
Every now and then I like to revisit an old topic.
So, let’s revisit pulseaudio and my hatred for it, shall we?
Now, you’re not an old greybeard like me, so you’re probably saying to yourself right now “OMG still with pulseaudio?!? That attitude is sooooo 2008!”
Well, for all the people over the years who have repeated the line of pure bullshit propaganda that “pulseaudio is much better these days and almost sorta kinda works most of the time, if you squint”, I’d like to present my first, reflexive solution to the fact that today I had no audio in zoom on a laptop with a current version of pulseaudio. A solution which, I might add, solved my problem instantly:
$ sudo bash -c "while true; do pkill -9 pulseaudio; done" &
Sure, it might not be efficient or pretty, but it worked. And it serves as a perfect metaphor for the state of Linux audio for this past decade and change, which can be summed up as “If you have an audio problem on Linux, the fault lies with pulseaudio”.
There have been multiple occasions where I’ve been trying to figure out some weird audio behaviour, only to realise “Oh OF COURSE! How silly of me! this machine has pulseaudio installed!”, and disable pulseaudio, and the problem goes away.
I’d file bugs for all this stuff, but I’m sure the fault lies with gnome (which I don’t use), or KDE (which I don’t use), or nginx, or my distro, or perhaps Microsoft Office. I’m sure these things are not actually problems with pulseaudio, because Lennart’s software never has any bugs.
I for one welcome the next decade’s worth of “if there’s a weird issue on Linux, The problem lies with systemd”, and being told in my bug reports that the problem is in the default configuration that comes with Mac OS X Server.
Now it’s off to go read the documentation (yet again) on how to disable this godawful dreck to stop it from automatically starting itself. Unfortunately we’re not in the days where just removing it is a simple option anymore (thanks for the totally unnecessary hard dependency, mozilla!)
“Even if you do manage to succeed at polishing a turd, at the end of the day all you’ll have to show for it is a polished turd”
-Me
The article says “Authorities said the cause of death was being investigated”.
For once, I agree wholeheartedly with the Authorities. It sure was. Though I find it surprising that they would make such a candid admission.
Luckily, his important advice on how to uninstall McAfee Antivirus will be with us forever:
Say what you like about the man, but he was always entertaining.
Just a quick reminder of the current state of play:
Go fuck yourself, CBS. I’m not even watching the teaser.
Aah fuck, not another one. Mike Collins, one of the loneliest men ever, has died.
I guess there’s a lesson to be learned from this: Everybody should punch Bart Sibrel.
I’ve been watching this show called For All Mankind. It’s glorious. One day there will almost certainly be a blog post here gushing about it. It has the potential to be my favourite TV show ever. I’ve told pretty much everyone I know about it.
But it’s an Apple TV show, so I can’t ethically recommend any legitimate means of watching it.
Today, I decided to do a thing that I do every now and then: make a good-faith effort to find a way to reward creators of content like this in an ethical way.
In other words, I want to buy For All Mankind on DVD or bluray.
So I decided to hit up apple for a chat to ask them when it’s coming out in a format where it can actually be purchased (as opposed to rented, which is what you get when you “buy” it from Apple TV), and unencumbered by DRM.
That went about as well as you’d expect.
The TL;DR version is that Apple won’t even discuss the possibility of you buying one of their shows on DVD without you providing your personal information. Much less actually release a show on a medium where you can actually buy it. Not only that, but they insist on using misleading terms like “buy”, and “purchase the content legitimately” even when called out on it. I guess they do deserve some minimal number of points for consistency.
So, if you want to watch For All Mankind, the most ethical way I can recommend to watch it is by using The Pirate Bay. You get very high-quality web-download rips there regularly every week.
And I really do recommend watching it. It’s great.
Dear Ronald D Moore: Your show is really great. I’d love to give you and your production company some money to support it’s ongoing creation, but Apple refused to help me with that. If you want to reach out to me and let me know how I can do that, Please do. I’d happily pay premium prices for a box set, I’ll be all like “shut up and take my money”. Thanks.
Here’s the chat log in full:
(well, almost full. This is the last screengrab I took. It was very close to the end of the chat. After this it was pretty much just “well, thanks for nothing I guess? Bye.”)

This one made me really chuckle:
Opera Tech Support: Why do you assume the same file uploads produce the same md5?
Me: Uh… because I understand what an md5 is.
(explains the concept of cryptographic hashes)
I’ve been reading The Register for close to 20 years now. Certainly well over 15.
They have been getting less and less impartial, and thus worse and worse at journalism, over the years.
And today I found out that their comment moderation is also totally fair and unbiased. For instance, check out this totally offensive post that they censored:
As you can see, I was totally out of line and very offensive here.
To add to this hilarity, it turns out that the person moderating comments on the article is the same guy who wrote it. Totally fair and not at all a recipe for a little fiefdom of echo chambers.
And as if that wasn’t enough, this comment was censored in such a way that there is no visible mention on the website that a post has been censored. Usually on their site, any moderated post will be replaced with a message saying “this post was removed by a moderator”. So it turns out that not only do they censor any even mildly critical viewpoints, they do it using a special censorship mode that they have implemented, so that nobody can tell that they’re basically nazis.
And that was the day that I stopped reading the register. Chris Williams, their editor in chief, is a little hitler wannabe.
Interestingly, if you search for Richard Stallman’s retraction of his… let’s say… “controversial” former opinions, all you get for the first few pages of search results is a bunch of articles talking about how he’s the devil. I had to search hard to find it, much harder than I should have.
I just wanted to link to Houtworm’s awesome write-up, Optimizing Linux for Gaming.
If you don’t have a deep, abiding love for the Church of Satan, You’re doing it wrong.
“Goebbels was in favor of free speech for views he liked. So was Stalin. If you’re really in favor of free speech, then you’re in favor of freedom of speech for precisely the views you despise. Otherwise, you’re not in favor of free speech.”
-Noam Chomsky
“x is an unknown quantity, and a spurt is a drip under pressure”
– Leonard Bruce O’Neill, 1954-2003
Aricebo Observatory has collapsed.
So sad. This awesome instrument has been an inspiration to me ever since I became aware of its existence via The X Files.
I was fortunate enough to be able to spend a few quintillion floating point operations processing data from Aricebo as part of the seti@home project.
I always wanted to visit it. Now that will never happen.
I’d bet good money that if they’d had the funding they needed for the last 15-20 years, they probably could have prevented the collapse.
But don’t worry, that funding totally went where it was needed: researching new ways to blow cunts up. So yay progress!
Nice one, ABC. That’s some top-notch journalism right there.
Firstly, I’m struck by the neutral tone of this article reporting on this…uh… “extra-legal”… murder. And I find myself wondering what the tone would be like if it was a nuclear scientist in a western country who had been killed. I can’t help but agree with the phrase “shameful double standards”. This was an act of terrorism, pure and simple.
Secondly: What, you couldn’t afford to have an actual interpreter translate the tweet?
Nah, rather than wait an hour or two and spend maybe a couple of hundred bucks on having an actual interpreter give an actual translation of what was actually said, we’ll just run the tweet through google translate! And hey, if google translate returns something clearly nonsensical, we’ll just edit that part out!
Nice one, ABC. I can see why you’re in favour of making google and facetube pay for the media they link to. With reporting of this high caliber it’s clearly worth it.
By TISM
My mate Roger got a girl pregnant when he was fourteen.
He was so shit-scared he told me. And when he said that her dad was a cop I thought he was joking.
I told him he’s got to tell someone, and so he went and told a teacher,
and the girl eventually got an abortion.
He was fucking shitting himself, let me tell you, but six months later he was fucking around like always.
“You betta watch it” I thought to myself. But Roger was pretty fucking sure of himself.
He was the guy who first brought a block of hash to a party.
Because I was his friend I was there when he first showed it to people, and we all went down the backyard and he rolled a joint.
Where did he get it from?
My parents would have killed me if they knew. I thought we’d all turn into junkies or something if we had too much.
The last time I saw Roger was last year at the Boxing Day test.
He’d turned into such a fat, normal, yobbo cunt.
“The wife nearly didn’t let me out today” he said.
And he did all that chanting yobs do, like “Ooh, Aahh, Glenn Mcgrath”.
“It got you in the end” I thought to myself, as I looked at Roger. “Life got you in the end, pal”.
“You were such a cocky, successful winner when we were sixteen, but now you’re just another sad fat prick sitting in the MCG, high-fiving in self-congratulation, as if it’s you that had the skill and determination to play for Australia”.
It’s the cunts with the bad haircuts that you’ve got to watch out for. There’s never been a popular teenager yet who’s done rat’s with their life. It’s the fucking dorks that give it a real go.
Glenn Mcgrath got 5 for 50 that day.
The title says it all really.
Let’s just look at some of the highlights, shall we?
The inquiry also said junior soldiers were often required by patrol commanders to shoot prisoners to get their first kill, in a practice known as “blooding”.
Translation: War crimes are a routine part of the culture.
The inquiry also found evidence some Australian troops in Afghanistan carried “throwdowns” — such as weapons, radios and grenades not issued by the ADF — which would be planted next to the bodies of Afghan civilians to suggest they were a “legitimate target” in any post-incident investigations.
Translation: he chance that there have bee war crimes stuff that won’t make it to a trial are roughly 100%
the report found patrol commanders were primarily responsible for covering up or sanctioning the culture that allowed the crimes to be committed, questions have also been raised about how much senior Defence figures knew.
Translation: “don’t stress boys, nobody important is going to jail, just a few scapegoats: the ones dumb enough to forget our training about not leaving evidence”
One of the reasons why the report is so heavily redacted:
“You don’t want to expose the public to too much gruesome information … so that the public aren’t traumatised and also to not enrage the public or potentially extremists or others who would have a go at Australia”
Translation: They’re just a few little deplorable sadistic warcrimes, involving the murder of children and such, no reason to upset the public about it. Wouldn’t want them protesting or calling for our murderer’s club to be disbanded or defunded.
But I think this might be my favourite piece of poetry ever:
“We don’t do support, just murder”.
The whole fucking thing should be disbanded, with no superannuation or payouts for anyone and all members put on watch lists because they’re fucking psychopaths, and all their hardware turned into lawn ornaments.
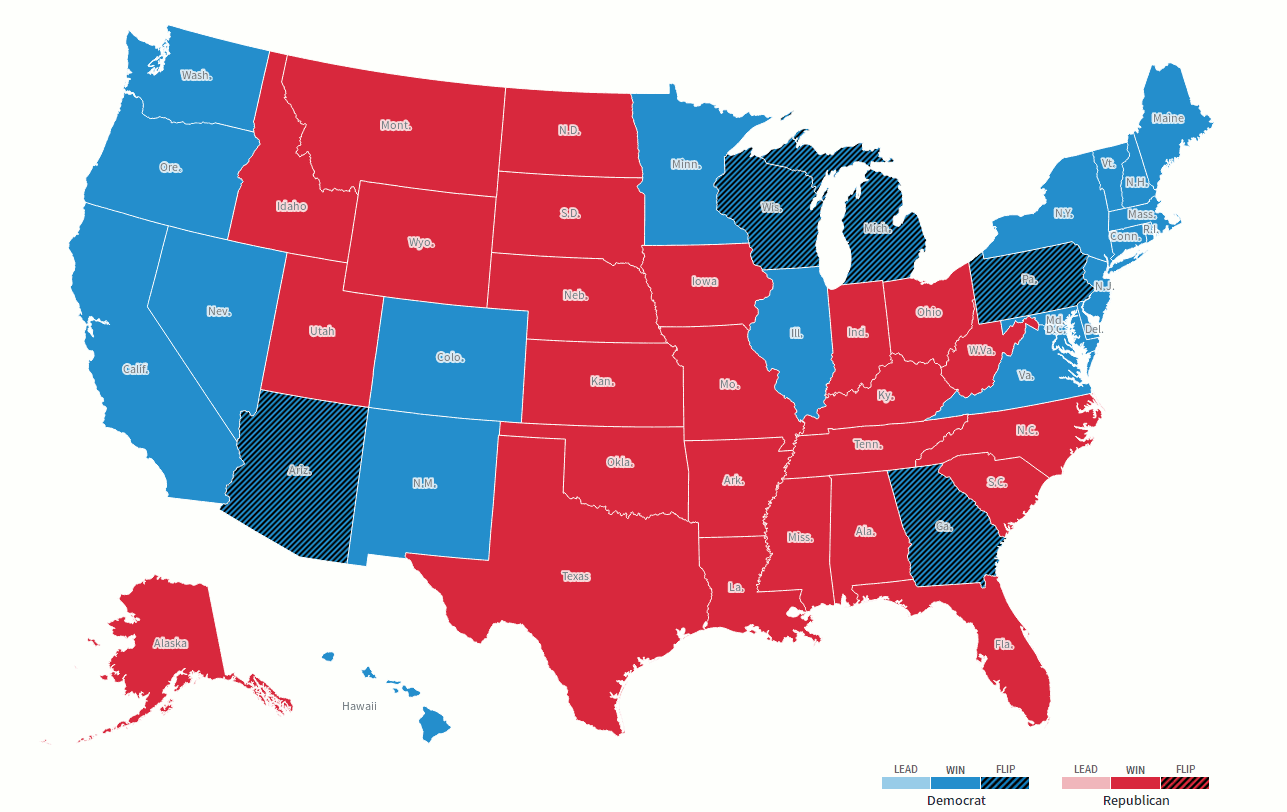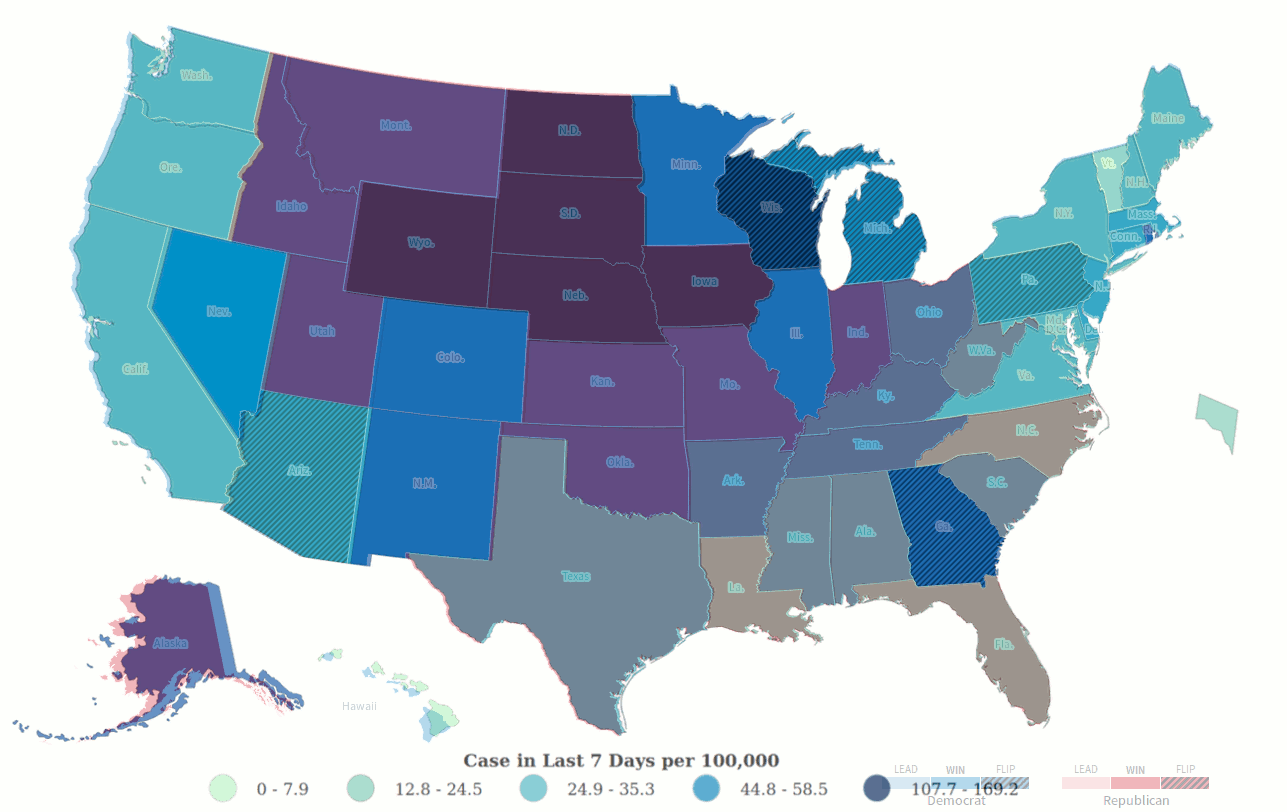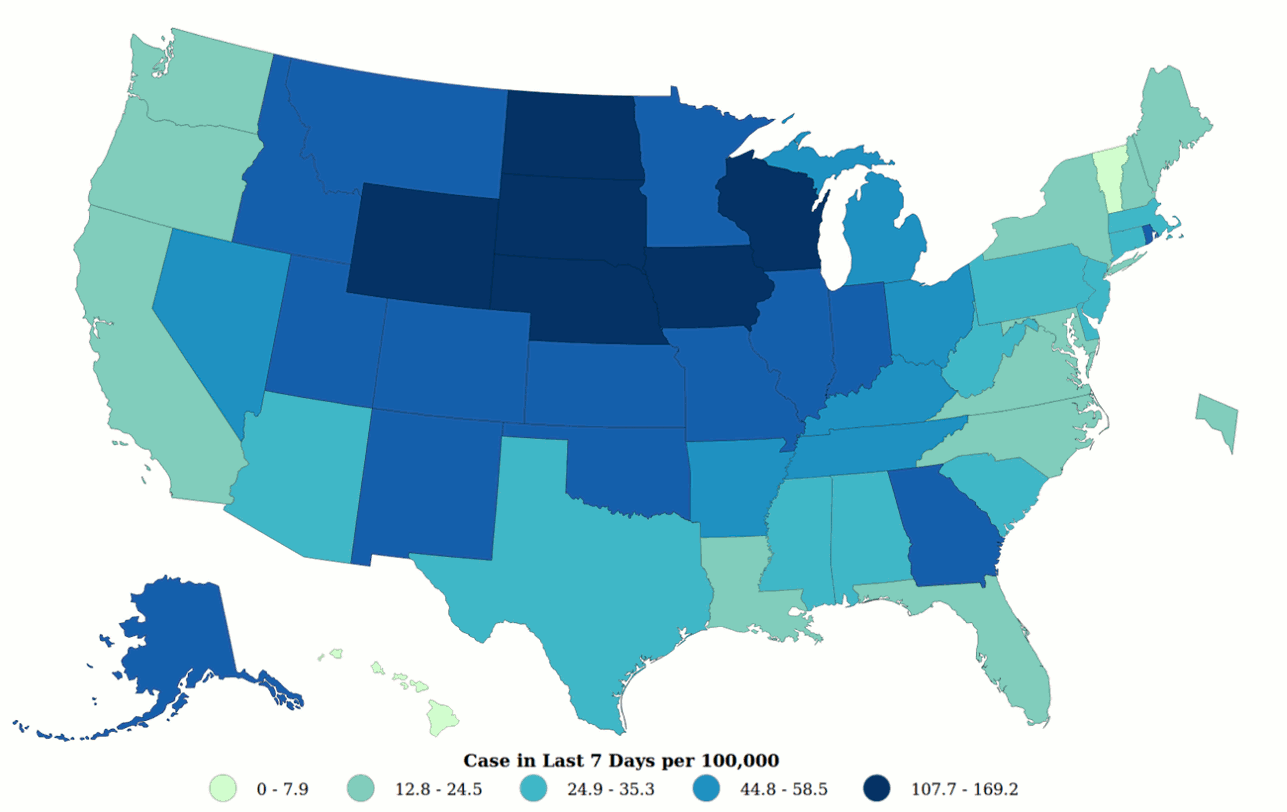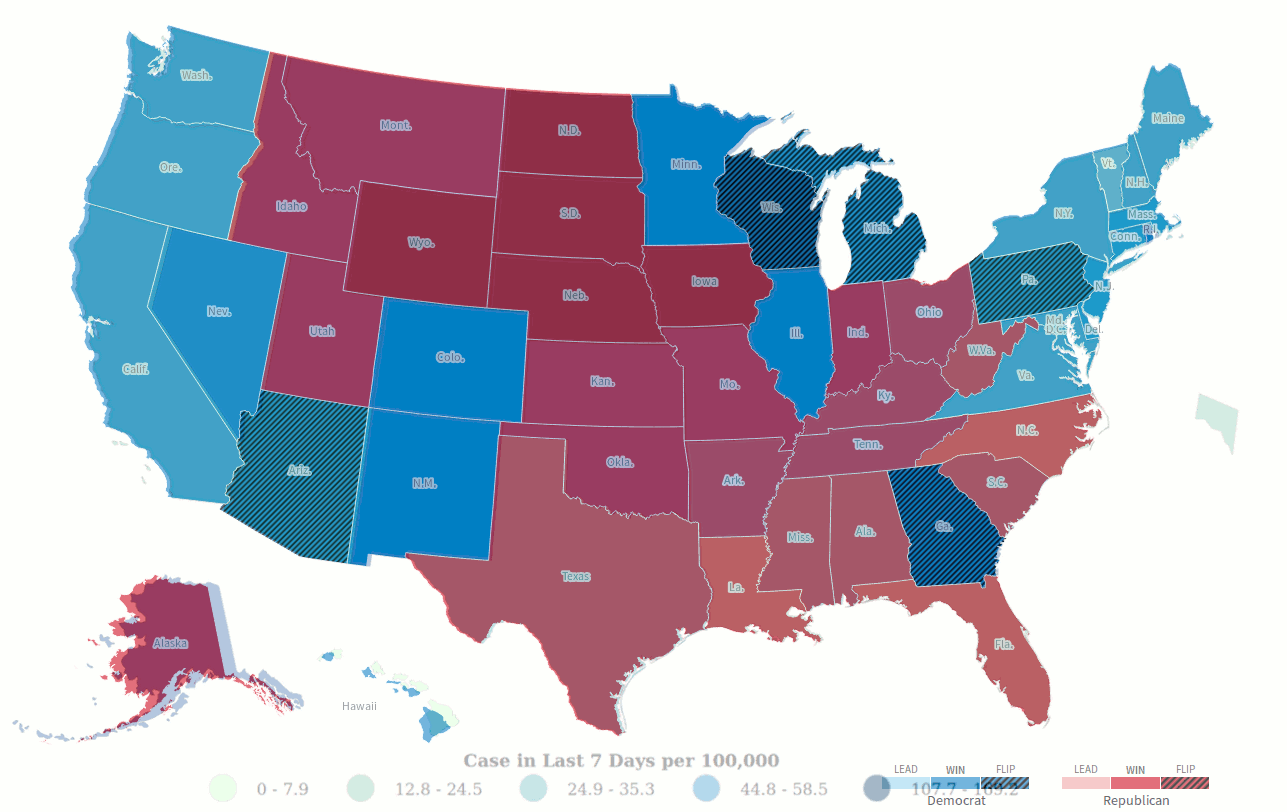
I decided to host this. Just because I can.
Good luck with your game of whack-a-mole!
And today we lost James Randi. Boo.
A legend at debunking frauds with a track record that speaks for itself. I don’t really need to say anything except “RIP”.
Here is a great TED talk he gave a while back.
a neat little bash trick.
Where previously I would have written:
echo foo | nc somehost 666
Now I know that I can do it purely in bash, with:
echo foo >/dev/tcp/somehost/666
There’s also a corresponding /dev/udp if tcp isn’t your thing.
Neat!
Aah, gotta love those HR people:

And today we start a new series of posts: Songs for which the term “too loud” does not apply.
And in our first installment, I present: Lost In Love, by Legend B.
You’ve never gone too far give up
You’ve never gone too far give in
You’ve never gone too far to let go, of all that you believe in
You’ve never gone too far turn back, of all that you’ve been fighting for
There’s still a chance to prove what your mama said
You can’t win everything, everything, every time
When you can’t win, fail with me
Time to fall in love again
Fail epic
Fail epic
When the night is bright, clear
And you can reach the stars
There’s no need to hide,
I’ve seen just what you’re capable of
I know I’ve got the power hidden somewhere deep
The power to lose it all
When you can’t win, fail with me
Time to fall in love again
Fail epic
When you can’t win, fail with me
Open up your heart
Fail epic
Fail epic
You’ve never gone too far give up
You’ve never gone too far give in
You’ve never gone too far to let go, of all that you believe in
You’ve never gone too far turn back, of all that you’ve been fighting for
There’s still a chance to prove what your mama said
You can’t win everything, everything, every time
Win everything, everything, every time
Can’t win everything, everything, every time
- The Presets
…then I recommend watching this:
There’s also parts two and three on the same channel.
I literally couldn’t watch it all the way through. Statements like “my favourite trek movie is the first one” just made me too sad.
I guarantee you that if you asked Alex Kurtzman his favourite Trek movie, he’d say JJ’s TrekWars from 2009. Because it’s his mate. And if you asked for his second favourite, he’d say Wrath Of Khan, because that’s the one everybody loves. And if you asked for his third favourite, he’d look at you blankly, not sure how to answer because he doesn’t actually remember anything at all about any of the others except that they were “boring”.
If he’s even seen them.
Fuck him and fuck CBS.
…and since images of text (particularly PHOTOS OF PRINTOUTS OF DIGITAL DOCUMENTS! WTF?!?) are the done thing now, no more of this pesky text that can be read semantically and parsed by machines and accessed by blind people, I’m not going to actually write much in the way of commentary here, I’m just going to post some images full of text:

I feel like maybe this news article I read literally 2 days earlier might also be relevant somehow:

In the beginning, there was Jack, and Jack had a groove. And from this groove came the groove of all grooves. And while one day viciously throwing down on his box, Jack boldy declared: “Let there be HOUSE!”, and house music was born. I am, you see, I am the creator, and this is my house. And, in my house there is ONLY house music. But, I am not so selfish because once you enter my house it then becomes OUR house and OUR house music!”. And, you see, no one man owns house because house music is a universal language, spoken and understood by all. You see, house is a feeling that no one can understand really unless you’re deep into the vibe of house. House is an uncontrollable desire to jack your body. And, as I told you before, this is our house, and our house music. And in every house, you understand, there is a keeper. And, in this house, the keeper is Jack. Now some of you who might wonder, “Who is Jack, and what is it that Jack does?”. Jack is the one who gives you the power to jack your body. Jack is the one who gives you the power to do the snake. Jack is the one who gives you the key to the wiggly worm. Jack is the one who learns you how to walk your body. Jack is the one that can bring nations and nations of all Jackers together under one house. You may be black, you may be white; you may be Jew or Gentile. It don’t make a difference in OUR House. And this is fresh.
The First Question.
A companion piece to “The Last Question”, by Isaac Asimov.
The first question was asked for the first time before there was language to articulate it. It was asked when there was barely thought. On a million worlds in a million galaxies over billions of years the question was asked over and over.
In a world’s developing stage, a predator, having gorged and sated itself, sat secure in it’s perch, preening. And as the first dim flicker of sentience wandered into its mind, the question was asked for the first time on that world in the language of thought:
“Where did all this come from?”
And over millions of years and countless triumphs and setbacks, life evolved. And finally, intelligence, and then language.
And the question was asked a million times just on that world, in a million different fashions. And as a species grew into a culture, the phrasing became more complex. At a certain point the counter-question was appended:
“Where did all this come from, and where is it going?”
And for every phrasing of the question, there was a different answer. Nobody knew for sure, though some – charlatans or delusional – claimed they did.
And then came math and science. And physics.
And the physicists said: We have an answer!
And they were correct, mostly, eventually: The theories were refined and tested, and sometimes thrown out, over centuries. Eventually, their theories accurately described the universe. So much so that they became an advanced technological civilisation. And they spread out into the stars, and life colonised the universe.
And now that they had answered the first question, it came time to ask the last:
“Can entropy be reversed?”
And nobody knew the answer. The greatest minds of a universe worked on the problem. But the problem proved difficult, maybe even intractable.
And they lived for a trillion years. And as the degenerate era approached, the stars began to die, and the last question became more urgent.
And they built The Minds. Hyper-efficient Matrioshka brains the size of brown dwarfs. And the Minds worked on the problem.
And they searched for a solution for ten trillion years. And they got nowhere. And the stelliferous era went into twilight, and the stars continued to die.
And there was insufficient data to answer the last question meaningfully, so an answer was not found. But a compromise was, and a project began.
And they converted all the remaining matter into Minds, and they cannibalised the stars to build them, and the universe went dark prematurely, comprised only of black holes and matrioshka brains.
And they booted up a googolplex of simulated universes. And they ran for a hundred trillion years.
And in the final second of that parent universe, an uncountable number of simulations within simulations ran for uncountable aeons, and the multiverse was born. And the first question was asked anew, into infinity.
A conversation with a customer service person tonight:
“Can I have your customer number?”
“I don’t know what that is. My email is (email).”
“And can I have your full name?”
“(name). Address is (address)”
“And can I have your address?”
“um… I just told you that 5 seconds ago.”
“OK. And can I have your email address?”
“uh… I told you that 10 seconds ago.”
Most Triumphant!

Normally I’d link to the source of this, but friends don’t let friends access Yahoo Answers, so no link today. I’m sure you’ll find it if you try. Instead, here’s the HTML version for your copypasta convenience:
Start by reading any Cthulhu Mythos book that you can get hold of.
Although there’s not much chance of getting access to a ‘Necronomicon’ or a ‘De Vermis Mysteriis’, you can occasionally find a used copy of something like the ‘Ponape Scripture’ (1907 edition) or ‘Cthulhu in the Necronomicon’ in one of the more exotic antiquarian bookshops off the Charing Cross Road.
Works such as this will provide a good grounding in the Mythos and may encourage you to advance in your attempts to worship the Great Old Ones and Outer Gods. However, they may also turn your mind and encourage you to do something less positive, such as eat your cat or gouge your own eyes out with a screwdriver.
Assuming that you wish to start worshipping Cthulhu, your next move should be to find a location close to the sea where you can establish your shrine.
If you can find a place close to a site of known Deep One activity then so much the better, as this species have been worshipping Cthulhu for millenia and may be able to assist you. The area around Walberswick and Southwold on the coast of Suffolk, close to the sunken town of Dunwich, would be a good choice. It is possible that other like-minded individuals might choose to move to such an area, so keep your eyes open for other eccentric types who might wander around the coast at night and gibber in strange languages, or who have the prominent eyes or webbed fingers indicating the Deep One taint caused by interbreeding with these creatures. Mind you, this is East Anglia, so not every web-handed gibbering idiot is necessarily a servant of Cthulhu.
Assuming that you’ve found a good location, you should attempt to conduct rituals to Cthulhu (as outlined in most good Mythos books). Although the exact form of these varies, you should be able to manage with about a dozen flickering black candles, a few blasphemous statues of Cthuloid entities, a set of ceremonial robes embroidered with strange symbols, a sacrificial dagger, and at least one human victim. How you get these together is your problem.
Having either made contact with the Deep Ones or communed with Cthulhu who may send his commands through evil dreams, you can get down to the business of becoming a true, hard-core, zero-SAN, cultist of Cthulhu.
Obviously there is a price to be paid for membership of this exclusive organisations. But, assuming you don’t mind spending the remainder of your life in thrall to mindless alien gods, permanently smelling of fish, gripped by catastrophic mental illness (and having to restrain yourself from shouting ‘Cthulhu fthagn!!’ at regular intervals) and with the risk that anti-Cthulhu vigilantes could arrive at any minute and slaughter you and everyone else in your cult with automatic weapons, it’s not that bad a choice.
Really.
So the trailer for Star Trek: Lower Decks is finally here. I thought I’d share my thoughts on it:
Why would I bother watching this trailer? It’s got “Star Trek” in the title, and it’s being made by CBS in 2020. That’s all I need to know. All I would achieve by watching it is angering myself and wasting 90 seconds (or however long it is, I haven’t even looked) of my life.
Plus, they haven’t bothered getting back to me with billing information after I contacted them when they announced Strange New Worlds:
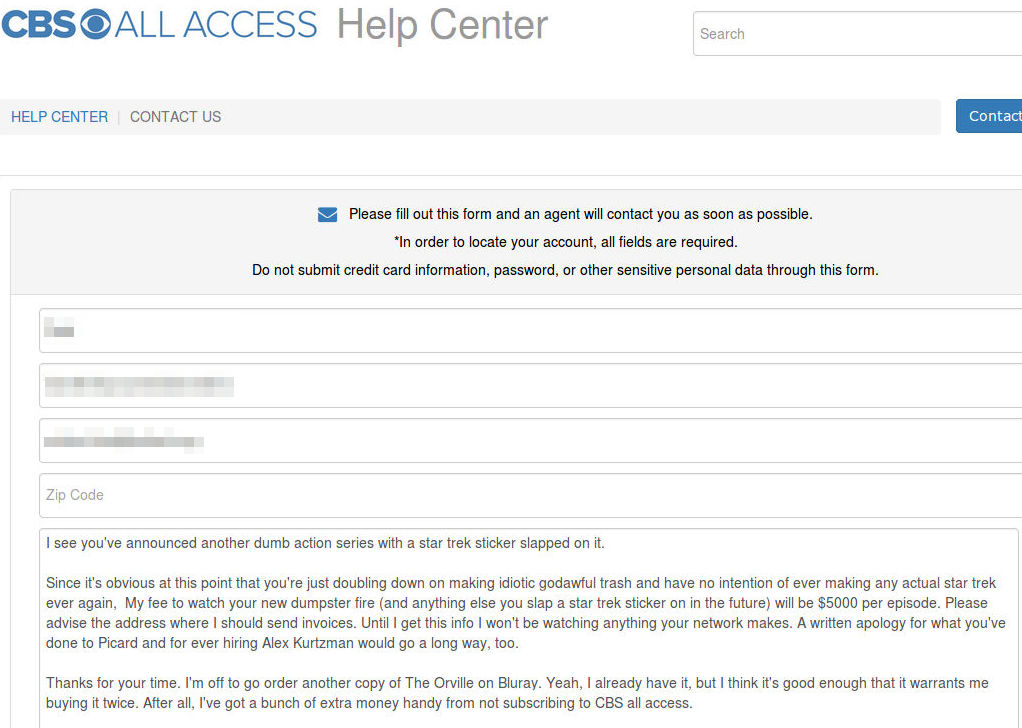
So I’m just going to assume that they don’t want me to watch it, anyway. They clearly didn’t want me to watch Discovery or Picard.
I’m not even going to bother talking about why I’m not going to watch the trailer for Strange New Worlds when that comes out. If the trailer and the show comes out and I haven’t mentioned it at all, you can just assume CBS never got back to me with that billing information.
And that’s all I have to say about that.
RIP Star Trek
1966 – 2005
“Of all tyrannies, a tyranny sincerely exercised for the good of its victims may be the most oppressive. It would be better to live under robber barons than under omnipotent moral busybodies. The robber baron’s cruelty may sometimes sleep, his cupidity may at some point be satiated; but those who torment us for our own good will torment us without end for they do so with the approval of their own conscience. They may be more likely to go to Heaven yet at the same time likelier to make a Hell of earth. This very kindness stings with intolerable insult. To be “cured” against one’s will and cured of states which we may not regard as disease is to be put on a level of those who have not yet reached the age of reason or those who never will; to be classed with infants, imbeciles, and domestic animals.”
― C.S. Lewis
Just in case anybody is wondering why I refer to every member of all armed forces as a murderer, Here’s why. It’s because of all the murdering they do.
I’ve heard theories about how on the whole the “defense” (lol, there’s a misnomer) force does good. Apparently they build schools and hospitals and stuff in parts of the world where bad things have happened. And apparently they do this much cheaper than, say, a builder could do it.
OK, so, firstly, for 25 billion dollars per year, I could build you a whole lotta schools and hospitals. I’m betting more than the military could, because I wouldn’t be spending that money on tools optimised for murder: The builders I sent out to build schools wouldn’t have access to attack helicopters, so they wouldn’t be able to murder anybody using mounted machine guns in attack helicopters. They wouldn’t have assault rifles, so their ability to murder people with assault rifles would be greatly diminished. You’re less likely to “accidentally” napalm a kindergarten if you’re not given any napalm as part of your “let’s go build a hospital” loadout. So not only would I save a bunch of money by not buying attack helicopters, assault rifles, and napalm, but I expect it would also have an effect on the number of murders done. Also, I’m no builder, but I suspect that a trowel is probably going to be a more effective tool for bricklaying than an assault rifle, in addition to being much much cheaper.
And, secondly, let’s say that I’m totally wrong and that attack helicopters are absolutely the best tool for the job of raising a building (which would make them super versatile, because they’re also pretty good for razing buildings) and that they’re cheaper than builders. Even if you’re building these schools and hospitals at one tenth the cost that a builder could, I’ll pay the extra to not have the whole “murder” and “warcrimes” things being done with my tax dollars, thanks.
Who wants to make a bet with me? I’ll bet you that nobody spends life in prison as a result of this.
Disband all armed forces immediately. The only things that they do better than anybody else are murder and warcrimes.
Aaw, damn, not Grant Imahara. It was way too early for him to go.
I choose to believe that his robots finally got him and that they just made it look like a brain aneurysm.
Or perhaps he uploaded himself into one of them.
Excerpts from this article, where Terrence Mckenna describes the “Self-Transforming Machine Elves”, or “Jeweled, Self-Dribbling Basketballs” – nonhuman entities many people claim to have encountered during a DMT experience. The whole article is worth reading, but I’ve edited it down here to remove most of Terrence’s trademark rambling (and delightful) style of talking to keep it to just a description of the entities. Mainly because I was reminded of the somewhat-famous ending quote and I wanted it on my blog:
DMT does not provide an experience that you analyze. Nothing so tidy goes on. The syntactical machinery of description undergoes some sort of hyper-dimensional inflation instantly, and then, you know, you cannot tell yourself what it is that you understand. In other words, what DMT does can’t be downloaded into as low-dimensional a language as English. The place, or space, you’ve burst into—called “the dome” by some—seems to be underground, and is softly, indirectly lit. The walls are crawling with geometric hallucinations, very brightly colored, very iridescent with deep sheens and very high, reflective surfaces—everything is machine-like and polished and throbbing with energy. But that is not what immediately arrests my attention. What arrests my attention is the fact that this space is inhabited—that the immediate impression as you break into it is there’s a cheer. [...] You break into this space and are immediately swarmed by squeaking, self-transforming elf-machines…made of light and grammar and sound that come chirping and squealing and tumbling toward you. And they say, “Hooray! Welcome! You’re here!” And in my case, “You send so many and you come so rarely!” The elves, or “jeweled self-dribbling basketballs,” come running forward. They’re “singing, chanting, speaking in some kind of language that is very bizarre to hear, but what is far more important is that you can see it, which is completely confounding!” And also, something is “going on” that over the years McKenna has come to call luv—”not ‘light utility vehicle,’ but love that is not like Eros or not like sexual attraction,” something “almost like a physical thing,” “a glue that pours out into this space.” Each “elf-machine creature” “elbows others aside, says, ‘Look at this, look at this, take this, choose me!’” They come toward you, and then—and you have to understand they don’t have arms, so we’re kind of downloading this into a lower dimension to even describe it, but—what they do is they offer things to you. You realize what you’re being shown—this “proliferation of elf gifts,” or “celestial toys,” which “seem somehow alive”—is “impossible.” This “state of incredible frenzy” continues for about three minutes, during which the elves are saying: “Don’t give way to wonder. Do not abandon yourself to amazement. Pay attention. Pay attention. Look at what we’re doing. Look at what we’re doing, and then do it. Do it!”
“Be the change you want to see in the world! Smite those capitalist pig-dogs! By…uh…buying our book bundle!”

“Remember, it is not enough to be insulted to be harmed, you must believe that you are being harmed. If someone succeeds in provoking you, realize that your mind is complicit in the provocation. It is not he who reviles you who insults you, but your opinion that these things are insulting.”
- Epictetus
This is a write-up of some of the quirks and behaviours I’ve discovered writing Python plugins for Gimp, along with some quick reference material.
I did a bit of searching and didn’t find a good write-up or documentation of the register() method you need to use to register your Python plug-in with Gimp. I figured some stuff out and thought I’d write it down.
Normally, you don’t need much of a reference for gimp’s python library, because it has such wonderful built-in documentation: In Gimp, choose Filters -> Python-Fu -> Console. The Python console will open. Press the “Browse” button and you have a searchable library of gimp functions. If you select a function and press the Apply button, gimp will give you the python incantation on the console command-line, ready to be copy-pasted into your plug-in. This is super helpful and alleviates the need for a (seemingly-nonexistent? I can’t find it online) API reference, but it does have one drawback: It doesn’t give you any examples or tell you a whole lot about the available options. In the case of the register method used to register plug-ins with Gimp, I couldn’t find it in the browser at all.
So, here’s what I’ve learned about registering python plug-ins with Gimp:
import gimpfu help(gimpfu.register)
to get a very basic description of the Register method. This gives you back something super useful:
register(proc_name, blurb, help, author, copyright, date, label, imagetypes, params, results, function, menu=None, domain=None, on_query=None, on_run=None)
This is called to register a new plug-in.
| Parameter | Example | Description |
|---|---|---|
| proc_name | “your_plugin_name” | The name of the command that you can call from the command line or from scripting |
| blurb | “Some Text” | Information about the plug-in that displays in the procedure browser |
| help | “Some Text” | Help for the plug-in |
| author | “Some Person” | The plug-in’s author |
| copyright | “Some Person” | The copyright holder for the plug-in (usually the same as the author) |
| date | “2097″ | The copyright date |
| label | “<Image>/Image/_Do A Thing…” | The label that the plug-in uses in the menu. Put an underscore before a letter to set the accelerator key. Use <Image>/ for a plug-in which operates on an open image, or <Toolbox>/ for a plug-in which opens or creates an image. |
| imagetypes | “RGB*, GRAY*” (see below) | The types of images the plug-in is made to handle. |
| params | [] (See below) | The parameters for the plug-in’s method |
| results | [] | The results of the plug-in’s method |
| function | myplugin | The method gimp should call to run your plugin. Not a string. |
imagetypes takes a string argument telling gimp what types of images your plugin operates on. The acceptable arguments I’ve found so far are:
label takes a string argument telling gimp where in the menu your plug-in should go. This has a couple of behaviours and implications that I had to figure out.
def myplugin(timg, tdrawable, myfirstparam, myotherparams...):
If your plugin will open or create image(s) itself (e.g a batch operation or a plugin which creates a new image), you should prefix your label with “<Toolbox>/“. So your label might be “<Toolbox>/File/_Batch/_My Batch Operation…”
If you use “<Toolbox>“, your method definition should not have the timg and tdrawable parameters:
def myplugin(myfirstparam, myotherparams...):
So, there’s my wisdoms on that subject. I mostly just wanted to document what I’d learned about writing plugins to generate a new image vs working with an open image, but I find myself searching for gimp-python docs every now and then, so I figured this would be a good thing to write and come back to. I expect I’ll come back and edit it as i learn more. Hopefully somebody else might find it useful too! ![]()
In the next day or so, the seti@home project goes into “hibernation”.
I’ve been contributing my spare CPU time to this project for over 20 years. More than half my life. A whole bunch of posts on this blog are about seti@home milestones.
I’m pretty avid about it, because I think that SETI is probably the single most important bit of science we can be doing. That’s a whole discussion, perhaps for another day.
I keep track of the statistics on an irregular basis. I contribute as much as possible, including donating CPU time of servers and workstations I control.
I’m the number 49 contributor in the country. I’m glad that I managed to crack the top 50 (this happened fairly recently) before the project shut down.
I also managed to crack the 99.9th percentile – I’ve accumulated more credit than 99.90051% of all SETI@Home Users. This is also a fairly recent development. I’m also glad that I managed to crack three-nines before the project shut down.
I’m ranked 1,797 out of 1,806,205 in the world.
I’ve contributed 28.91 quintillion floating-point operations:

Suffice to say that it’s something that I’m passionate about. My Drake Equation simulator is an example of that.
I’m… displeased… by this development.
The announcement that the project is going into “hibernation” came less than a month ago. Here’s the stated reasons:
1) Scientifically, we’re at the point of diminishing returns; basically, we’ve analyzed all the data we need for now.
2) It’s a lot of work for us to manage the distributed processing of data. We need to focus on completing the back-end analysis of the results we already have, and writing this up in a scientific journal paper.
With regard to point one: My drake equation simulator, and common sense, tells me one thing about SETI: it’s a long-haul game. Given the size of the galaxy and the delays in communication between stars, any communication with extraterrestrial intelligence is going to be a slow process. Another important factor is that given the size of the galaxy, if an alien civilization starts broadcasting today, the likelihood is that it’s going to be thousands of years – perhaps even a hundred thousand – before we receive that transmission. And that’s only taking civilisations in our galaxy into account. The SETI project might run for hundreds of years and not find anything. And it should. A couple of decades for a project like this is an infinitesimal blip compared with the timespans we’re talking about with regard to extraterrestrial intelligence. If you’re going to make the claim that “we’ve analyzed all the data we need for now”, then that can only mean one of two possibilities: 1: You’re not actually doing SETI, or 2: you don’t know what the fuck you’re talking about. There is new data coming in every second of every day. That first signal we detect could be tomorrow. Or it could be a thousand years from now. If we stop looking it’ll be never.
Some fuckwitspeople argue that running a project like SETI is expensiveblah blah blah. They seem to think that because we haven’t found anything in a few decades (well, nothing definite – we have found a couple of interesting and unexplained signals, the Wow! Signal being the most famous) that we should save our money and give up. This is ludicrously short-sighted thinking. The SETI project needs to be a LONG-term project. In the hundreds or thousands of years. It’ll take a hundred thousand years of SETI before we can say that we’re (probably) the only intelligence in the galaxy, and even then we could get a signal the next day. And no result is a result where SETI is concerned – not getting signals gives us some indication of the rarity of intelligence (or, at least, EM radio tech) in the galaxy.
As for point two, this basically boils down to “we’ve decided we can’t be bothered”. If it’s a lot of work then that means you haven’t automated it properly. Writing this up as a paper? What I’m hearing is “it’s more important that I get published than answering one of the most important and fundamental questions out there”. I’ll be expecting to see my name attributed on the paper.
There are nearly 2 million seti@home users. Lots of us are computer nerds. I’m sure you could have found some volunteers to do all that hard work you can’t be bothered with any more. I’d be happy to do as much as I can. But you didn’t ask, instead you just shut down a project that I’ve been invested in for most of my lifetime.
Obviously, seti@home isn’t all of SETI, obviously there will be a bunch of other SETI being done. The Breakthrough listen project is doing some great stuff. But this is a blow to science. Seti@home was a pioneer of distributed computing. And I think that the way it’s being shut down is a huge disservice to science and to all the people who have volunteered our processor time and electricity over the decades. I’m not impressed.
My machines, on the other hand, will be relieved. Their processors will be running much cooler from now on. I’ll go through processor fans much less quickly. And my wallet will probably appreciate the reduction in electricity consumption: I’ll be interested to see the difference in my power bill. I wouldn’t be surprised if it’s noticeable.
And today we lose yet another Apollo astronaut, Al Worden.
You’ve never heard of him? I know. I’m not going to claim that I could have named him if you’d asked who the CSM pilot of Apollo 15 was, either. And that’s pretty sad on everyone’s part. Almost as sad as the fact that Al didn’t make it to see a return to the moon or a mars landing.
Finally! It only took 9 months to get a ringtail to take food from me:


I fucking love The Orville.
If you haven’t seen it, here be spoilers. You should prpbably just go watch it if you haven’t. But, on the other hand, this is a fairly episodic show. It’s not serialised like so many things are these days. So while there will be spoilers, I think it’s probably not such a huge deal for a show like this. Still, you have been warned.
I think perhaps my favourite moment in the entire show (so far) is in Season 2′s “All the World is a Birthday Cake”, when the captain says “attention everybody, prepare to initiate… First Contact”.
And all of the crew cheers.
It’s fucking glorious.
Oh, optimistic sci-fi, I’ve missed you! It’s been so long! It’s so rare these days that I really can’t even remember the last time I saw any. I suppose there are a few movies that might count: Arrival, Interstellar, The Martian. Perhaps. But they’re all movies rather than TV series. Perhaps Stargate, but it’s now been over a decade since that ended. What I’m really talking about is obviously Trek.
I don’t want to talk about the current dumpster fires with Trek stickers slapped onto the side of them as they gang-rape Roddenberry’s corpse. I’m not here for that. I’d rather not think about them. I think the best thing is if I just stick my fingers in my ears and pretend they don’t exist. As far as I’m concerned, they’re absolutely definitely non-canon. but I kind of have to talk about them at least in passing. The comparison is inevitable, because the Orville is more Trek than any of that trash will ever be. And there’s one simple reason:
This is a show written by somebody who actually likes Science Fiction.
And I mean REAL Science Fiction, not braindead action crap set in space. Not heroic stories about wizards with laser swords. Not another frankenstein “oooh scence bad!” story, or other hamfisted moralising (cough).
Now, real sci-fi doesn’t have to be optimistic. There’s lots and lots of great sci-fi that isn’t. Lexx is one of my favourite shows ever, and it oozes cynicism from every pore. Babylon 5 might be hoepful overall but it gets into some pretty dark territory, and I fucking adore it. But I think that probably the very best of it tends to be optimistic. Much of Asimov’s work (particularly the foundation and robot stories) springs immediately to mind. The Oddysey series. The Galactic Milieu series. All of these are favourites of mine. But the point isn’t that you can’t make good sci-fi that isn’t optimistic. The point is that there’s basically no optimistic sci-fi these days. Certainly not on TV or movie screens. It’s all gritty, edgy stuff where people are cunts. And that’s a huge shame, because it’s the very core of the greatest sci-fi TV/Movie franchise ever. And I’ve missed it. So when the Orville’s crew cheers at First Contact, with comments from the crew like “This is why we’re out here!”, it just about brings tears of joy to my eyes. And I’d like to think that maybe Roddenberry’s corpse is at least taking some comfort, while being gang-raped, in the fact that some people paid attention, even if those people have seemingly been banned from working on anything with a Trek license because the people in charge of trek obviously hate Trek.
I’m starting to think, and this is a big statement, that The Orville might have the potential to be better than Trek. All of it, not just the current dumpster fires.
Wait, don’t close the tab, hear me out.
Firstly, I’m not saying that it IS better. It’s got some pretty huge boots to fill if it wants to take the crown. That’s 50 years of some of the best TV sci-fi ever that you’re going up against. A little 2-or-3-season run isn’t going to allow you to come close. We won’t be able to really consider whether it IS better until it’s at season 10, or movie 5, or something like that. Seth MacFarlane is going to have to keep it up to the same (of higher) levels of great for a LONG time to truly compete with the king.
But I can see that it might have potential.
Firstly, the comedic aspect. The Orville doesn’t have to always take itself so seriously. They’ve leaned hard into the drama and sci-fi side, and I think that’s for the best (it’s one of the things I love about season 2, the comedy has been dialled back and it’s gone 95% sci-fi), but they could do a very comedy-heavy episode and the audience wouldn’t bat an eye if it was done well. Trek really struggled to do that kind of thing. Yes, there is the odd outlier like The Trouble With Tribbles, but even with episodes like those, Trek can’t really be self-referential or examine itself. It has to take it’s premise seriously. But the Orville doesn’t have that limitation. And that means that it has the potential to do something that we really don’t see enough of: The Orville is perfectly positioned to start examining sci-fi tropes. Oh how I’d love to see an episode that deals with the fact that sci-fi writers have no sense of scale. The comedic side of the show gives it the ability to do stuff like that, and I’d LOVE to see it. Deconstruct those tropes. Reconstruct them. Play them for laughs. Make the sci-fi fans chuckle. Reference classic stories and point out how absurd they are. Have somebody mention that we’re entering an asteroid belt, and have somebody say “all hands brace for impact!“, and somebody else say “What are you talking about? The average distance between asteroids is like a hundred thousand kilometers. The chance of hitting one is in the billions to one. We’ll be lucky if we come within visual range of anything larger than a grain of sand”.
Secondly, and this is going to be a bit contentious: Canon. Trek has 50 years of history sitting behind it, and there was no concept of “canon” when it started, it was just a sci-fi show. The idea of canon developed gradually over years. There’s really no canon to speak of in TOS: things tend to mostly be self-consistent, but the idea of canon didn’t really come about until TNG. So there are a bunch of things that are inconsistent, particularly in TOS. Hell, in the second (or first, depending on how you count) episode, “Where No Man Has Gone Before”, at the very start of the episode, they talk about how they’re at the edge of the galaxy. According to later (and more consistent and realistic) canon, that’s a multi-decade journey. Similarly in Star Trek V they go into the galactic core, a similar distance. Another that springs to mind is that I recall a mention of travel at warp 13, but another episode establishes that warp 10 would be “infinite speed” and is basically impossible (if you travelled at infinite speed you would be at every point in the universe simultaneously). These are just two inconsistencies of many. Most of the time, they’re not a big deal, and we kind of just go with the one that makes the most sense and keeps things as internally consistent as possible.
But more than inconsistencies, this canon serves as a huge pile of restrictions for writers. If you want a trek story to feature regular travel to and from another galaxy, you’re probably going to have to explain that there’s been a huge leap forward in propulsion technology allowing travel literally millions of times faster than what we’ve previously seen. And it’s going to have huge implications for all future stories set in that universe, e.g the delta quadrant is now suddenly a day or two away rather than 70 years. It’s not impossible, but not exactly simple either. So, let’s come up with a totally ridiculous example: Say that I was a trek writer and I wanted to include some kind of, I don’t know, let’s say it’s a “spore drive” that allows instantaneous travel to pretty much anywhere in the galaxy via the power of magic mushrooms, or something. That would have all kinds of huge implications on the canon of the rest of the series. And if I was to put something stupid like that in, say, a prequel series set before other pre-existing shows, it’s going to be pretty unavoidable that I’m going to break canon pretty majorly, or I’m going to have to come up with some very contrived reason why the voyager crew doesn’t have knowledge of or access to any information about this ridiculous technology that could get them home in 15 minutes. And anyway, that’s a particularly absurd example because it doesn’t “feel” right for trek – it feels like magic, and trek has always been grounded in science. It would be similar to introducing magical powers into trek. Like, say, I don’t know, let’s go with the ability to telepathically communicate over interstellar distances. Something dumb like that would be very out of character for a trek show and only somebody with no understanding of and/or contempt for trek would contemplate adding something like that to the canon.
I’m not saying that canon is bad, or that there are no more interesting Trek stories to be written (I have like 5 different ideas). What I’m saying is that writing in the Trek universe is by definition fairly restrictive. You can’t, for example, suddenly declare that the Federation has become evil and… I don’t know, let’s go with something off-the-wall and totally absurd and say that they decide not to help an enemy when they’re in need due to some catastrophe, using it as an opportunity to start talking and potentially ushering in a new era of peace, like they did in Star Trek VI, because such an idea would be totally ridiculous and go against everything that Trek is about and destroy the very core of the concept.
Instead what I’m saying is that the canon is restrictive, and that it’s difficult to keep consistent with it. It makes the writer’s job harder. There’s a huge body of stuff that you need to know, and even somebody with the most encyclopaedic knowledge of Trek can make a mistake.
But that doesn’t mean it’s OK to just not try, or that it’s time for a reboot, or anything like that – if you want to set your story in the Trek universe, you’re taking on the responsibility to live by that canon. If you don’t like it, set your story in a separate canon and don’t slap a Trek label on it.
But The Orville doesn’t have that issue. They can make up their canon as they go. And because they have the benefit of Trek’s hindsight, they can stop and think about what they say before they say it, with an eye to future continuity. They can avoid doing things like saying “we’re at the edge of the galaxy” in an early episode. They can build a new canon, one which might be a bit more consistent.
I’ve heard that there are rumours that CBS has been thinking about selling it’s dumpster fire to Universal, and that they want to put Seth MacFarlane in charge. I don’t think they’re true. But even if they were, I say “why would he want that? He’s more free where he is, and he’s doing fucking brilliantly, thank you very much, and his property hasn’t been perhaps-irrevocably tarnished by people who hate science fiction”
To reiterate: All of this is speculative, and The Orville has got a LONG way to go before it can even reach for the crown. But I think I can see a potential there. There’s certainly a potential for a few classes of stories that Trek couldn’t do.
And we’ve already seen some of the best allegorical sci-fi in a long time come from The Orville: The arc about Bortis’ child is a very interesting meditation on some current trans and gender issues. Bortis’ porn addiction episode is a great bit of science fiction, and something that Trek would probably struggle to cover due to being so family-friendly (but that might also be a product of the times, There are some oblique references to various types of holosuite programs you can get from Quark in DS9, so perhaps a modern trek could do a story like that, it’s just a pity they’re not making any trek any more). Bortis seems to get a lot of the interesting stories. His race is almost purpose-built for a lot of great allegory about some pretty current stuff. But there are others. I really really loved “Majority Rule”, which discusses social media and mob mentality, and “All The World is a Birthday Cake” which is an hour-long indictment of astrology, and “Mad Idolatry” where time passes quickly on the planet and Kelly is their god (which reminds me a lot of a really great Voyager episode, “Blink of an Eye”). And the final two episodes of season two (“Tomorrow, and Tomorrow, and Tomorrow” and “The Road Not Taken”) are a great time-travel story. And these are just the “real” sci-fi episodes which spring to mind. I also really liked the Kaylon arc in season 2, even though it was fairly standard stuff I thought it was well-executed. I think just about every single episode has been enjoyable, I certainly can’t think of one that sucked.
I was particularly struck by the first few episodes of season 2. I didn’t get around to watching season 2 until recently. I had just watched the first episode of a certain brand new dumpster fire that shits all over the core concepts of a certain 50-year old franchise, and needed to wash the taste of disgust out of my mouth, so season 2 of The Orville was particularly refreshing. I loved that the first episode was just a quiet little character study/drama thing. No explosions. No roundhouse kicks. Just a trip to Bortis’s homeworld so he can take a piss, and a couple of other little character things.
Nobody even fires a gun until episode 3. Though to be fair there is one isolated and ritualistic stabbing in episode 2.
It’s fucking glorious.
And then there are the references. And the guest cast. And the people behind the scenes. Brannon Braga, Jonathan Frakes, Robert Duncan McNeill. Robert Picardo. Marina Sirtis. Charlize Theron. Liam Neeson. Ted Danson.
It’s fucking glorious.
And then there’s the episodic nature of it. It’s not heavily serialised. If you miss an episode, it’s not the end of the world. If you just want to watch one episode in isolation, you can do that. You can jump in and watch a season 2 episode without having seen ten hours of backstory to understand what’s going on. Not that serialised stories are bad – I might have to write another ode one of these days for The Expanse. But there are definite advantages to smaller, self-contained, episodic stories.
Can I think of flaws? Sure, I guess, nothing’s perfect, but I don’t know that “flaws” is the right word, I think “finding its footing” might be more appropriate. It can be a bit derivative. Some of the episodes have strong flavours of certain episodes from other franchises. But that’s not necessarily a bad thing. You’ll be hard-pressed if you want to write completely original sci-fi, or any kind story for that matter. And the show’s premise IS pretty derivative, that’s what it is intended to be: it’s not trying to be something totally new and unlike anything you’ve seen before. In fact it’s specifically NOT going for that. It’s trying to be like something great that you haven’t seen in 15 or 20 years, while also having its own feel. And I think it does a really great job at that. I think that the early episodes were a bit comedy-heavy and some of it didn’t really land for me. I’m glad that they seem to have shed that and gone for a mostly-serious tone with the odd joke thrown in. But on the other hand, Isaac cutting off Gordon’s leg was gold. I wouldn’t mind seeing perhaps the odd comedy episode.
“Individual science fiction stories may seem as trivial as ever to the blinder critics and philosophers of today – but the core of science fiction, its essence has become crucial to our salvation if we are to be saved at all.”
– Isaac Asimov
As far as I’m concerned, season 2 cements The Orville in the pantheon of most worthy science fiction shows. I bought both seasons on DVD when I was mid way through season 2, I figured I should put my money where my mouth is. And I’ve got them sitting on the same shelf as my Trek box sets, where they belong. It was a nice feeling, I hadn’t added to that shelf in over a decade and didn’t think I’d be adding to it any time soon.
The Orville is fucking glorious. Go buy it. Let’s see if we can make it a big deal. Let’s see if we can get it to season 10.
Fuck. Marie Fredriksson has died.
Fuck.
This one hurts. More than Bowie. More than Chris Cornell.
She was probably just about my first crush. I vividly remember seeing the film clip for “The Look” at my grandmother’s house. I must have been about 8. I already loved the song but I hadn’t seen the film clip:
frameborder="0" allow="encrypted-media; picture-in-picture" allowfullscreen>
I remember thinking she must be just about the most gorgeous woman on earth. That cool, short, unkempt, almost-white hair is what did it for me. I didn’t know it at the time but it was actually the tall blonde swedish girl thing. She really did have the look. That’s the moment that made me a Roxette fan, not just somebody who liked that song. It’s stupid and it doesn’t make any sense, but give me a break, I was 8. Roxette were one of the first bands to ever get enough attention from me that I’d call myself a fan. Probably the only one who was earlier was Robert Palmer, who released Heavy Nova just a few months before Look Sharp!.
I lucked out when I decided that I was interested in this pretty girl. Not only was she gorgeous but she could really sing, too. Though you don’t really get much of a chance to hear it in that song because Per does most of the vocals, Marie only joins in for the chorus. It wasn’t until “Listen To Your Heart” and “Dressed For Success” hit the charts that we learned that she could really really sing.
There were a bunch of great singles on Look Sharp!. They got radio play. Roxette became a household name, everybody loved their songs.
Of course, I was 8, so I didn’t buy the album. Those were the days when getting a copy of an album was a really big deal which required much begging and cajoling of parents, and also a trip to the neighboring town where there was a record store, our town was too small. The only albums I remember getting (on cassette, this was pre-CD) as a kid were Heavy Nova by Robert Palmer (another album that still holds up, it’s magnificent, I appreciate it more as an adult), and the Ghostbusters soundtrack (I was a huge fan of the movie as a kid and particularly and loved the theme). So I didn’t own a copy of Look Sharp!, I had to tape my roxette songs off the radio.
And a few years went by. And then Joyride came out. And Roxette cemented themselves as A Big Deal. There were a bunch of huge hits on that album. They were everywhere, getting heaps of radio play and loved by everybody. I’m now perhaps 11 and poor so buying a CD isn’t an option. But I did go to the local library, borrow Joyride, and copy it.
I can’t explain just how huge they were around the Joyride era – everybody knew and loved Roxette. Their songs were (mostly) cool and fun and catchy and accessible. And the ones that weren’t were love Ballads. In other words their repertoire was everything you need to be a huge pop star. And they were. They filled huge stadiums all over the world and contributed to movie scores (Pretty Woman and Super Mario Bros are the two that spring to mind. “Almost Unreal” was the best thing about that godawful mario movie). They were massive.
I was a big fan, but I wasn’t a screaming, rabid Roxette fanboy. I listened to the radio mostly and couldn’t afford albums, so I only really knew the singles.
By 1994-1995 their star had faded a bit. Crash! Boom! Bang! didn’t do as well as their previous albums, and there was a bit of a break before their next real studio album. It seemed that they were pretty much done. This is all pre-widespread-internet, too, so it wasn’t like you could just go to their website and see what they were up to. Somewhere in there, probably ’94, I managed to finally buy Look Sharp! on CD, which I thought was a better album than Joyride
Another very significant thing happened in 1994, but it was probably 1995 before I discovered it: Superunknown. I discovered soundgarden. And Grunge. And Metal. And finally, Tool.
And another significant thing happened in 1994, too: The Spice Girls. Who I. Fucking. Hated. Hated with the white-hot burning passion of supergiant going supernova. My attitudes had changed dramatically, pop was all awful, synths were evil and shit, techno was trash, guitars were what it was all about. Throw in a bit of Satan and it was catnip. Pop music became passé and “Gay” and I loathed it all on principle. This was an extremist attitude which caused me to miss out on a bunch of awesome pop and especially techno music from around this era – I remember hating Daft Punk’s “Around The World”. Which today just seems nonsensical – how could I have ever hated such a great track?? But it’s what happens when things are packaged up into groups and genres like music seemed to be when I was young.
When I had no friends around, I’d still occasionally pop in my copy of Look Sharp!. I still loved Roxette, I just couldn’t tell any of my grunger friends, Roxette was totally not cool. They were my guilty pleasure.
That was the status quo for a long while, maybe even until 2000: grunge and metal and guitars and growls and Tool and Marilyn Manson and Rammstein and so many other great bands. And then I was “outed”. I was listening to Roxette one day when a friend dropped by, and I was forced to admit the most uncool thing ever, expecting to be ostracised from my group of friends – I was a big Roxette fan.
So was he.
That’s when I stopped caring about the rivalries between music genres. It didn’t change what I liked, at least not immediately, but it was the first crack that opened my mind up so that one day I’d also become a huge fan of acts like Aphex Twin, Daft Punk, Vitalic, The Presets, The Faint, and a bunch more. And it enabled me to re-examine a lot of pop music that I never gave a chance in the late 90s and early 2000s. Sca
At some point, I bought Don’t Bore Us, Get To the Chorus (it was cheaper than buying all of the other 4 albums) and listened to it over and over for like a year. I especially loved the previously-unreleased track, “You Don’t Understand Me”. This was what took me from being a big Roxette fan to a huge Roxette fan.
I’ll never forget my excitement I was at work listening to the radio one day and and “Wish I Could Fly” came on, announced as “the new song from Roxette”. They hadn’t released a new album in about 5 years at that point (I still don’t think Baladas En Español really counts), and I’d assumed they were pretty much done. I ran straight to the shop and bought Have A Nice Day. My friend didn’t like it, it was “too techno-ey”. I was more open to it, I loved a couple of tracks, liked a few, and found the rest listenable if not amazing.
I grew up, and I discovered lots of other music, and I didn’t listen to Roxette all that often, but they were always there and I came back to it every now and then.
I just wish I’d seen them live. I had the opportunity a few years back but I think the show was on new years eve or something like that and I had other plans, and also the tickets were pretty expensive, so I gave it a miss, thinking to myself that there would be another chance. And, of course, that was really not very long (like a couple of months) before Marie’s doctor told her to stop touring. So I missed out on ever seeing them live.
Marie was also indirectly responsible for another revelation I had: Digitally sampled music on the Commodore 64. My C64 came with boxes of disks filled with all manner of wonderful pirated stuff, including this:
frameborder="0" allow="encrypted-media; picture-in-picture" allowfullscreen>
Which was the most amazing sounding thing I’d ever heard on a C64 – they’re not supposed to be able to do digitised sound, that’s a bug in the SID chip. This is one of the first demos I ever heard with digitised, sampled sound. And it sampled “Dance Away”, leading me to whip out the album and familiarise myself with that track, which wasn’t a single. And I still love it to this day.
Marie Fredriksson changed my life. She was directly responsible, and she did it more than once. First, she was my first crush and a very early parasocial relationship. Then, she was one of the first artists I was a fan of. Then, she was the catalyst to open up my mind and give up my prejudices against pop and electronic music, broadening my horizons hugely – I’m a much more well-rounded and less judgmental person because of her. And I can’t tell you how many times I came home sad about some girl and put on songs like “Spending My Time” or “Fading Like A Flower”. She brought me countless hours of joy, and just as importantly comfort when joy wasn’t on the cards.
The world is darker today because you’ve left us, Marie. I could never give you up. And I miss you terribly already. :’(
Rest In Peace.
This is my response to XKCD’s “Unpopular positive opinion challenge”:

This is interesting, challenge accepted! I’m sure I can come up with one pretty easily…
…but I initially found this a lot more difficult than I expected – hitting that “below 50%” criteria was difficult, particularly combined with the “came out since 2000″ criteria. I came close a few times.
The very first movie I thought of was Cloud Atlas, which I would list in my top 10 movies ever made and have recommended to literally everybody I know, but which apparently nobody saw or liked for some reason I can’t comprehend. But it has 66% for both critics and audiences.
My next thought was Bicentennial Man, a movie I really truly love, and the only faithful adaptation of an Asimov (A man I deeply love) story. I’ve written before about how the fact this got negative reviews reflects poorly on humanity. But it doesn’t quite meet XKCD’s criteria either, having a 58% audience score and coming out in 1999.
I looked at quite a few movies before I thought of one which would definitely meet the criteria. And as soon as I thought of one, another one came to me.
I came close a few times. I LOVE Hancock. It’s got Will Smith and Charlize Theron, and it’s a different take on the superhero genre a decare before we started seeing Brightburn or The Boys, But it has a 59% audience score.
I quite liked the Ang Lee / Eric Bana Hulk movie from 2003. It’s an interesting early take on how to do a comic book movie, before the cookie cutter had been made, and it does some interesting stuff playing with comic book panels and wipes and whatnot. And I’m a sucker for Eric Banana, aka Poida. Audiences hated it for some reason, but it has 62% with the critics.
Rob Zombie’s Halloween remake was really great, I like it much more than I like the original (which I’m not a big fan of). The kid in that movie is terrifying and fantastic. And like most Rob Zombie films the casting is great too, particularly Malcolm McDowell and Brad Dourif. But the real standout is the kid – Daeg Faerch (who I’ve just learned was also the bully in Hancock!). This is one of the best pieces of child acting I’ve ever seen. It’s what makes the movie great as far as I’m concerned. But apparently only 59% of audiences would agree with me. Close but no cigar.
OK, what about another Rob Zombie movie I adore – House of 1000 corpses? Or perhaps the sequel? 65% and 78% with audiences. The second one even has a critic score over 50%.
Hmmm. Riddick? The third one? Everybody hated that. We’re pushing it now because I wouldn’t say I loved it, but it wasn’t bad. But nope, 57%/56%.
And then it hit me.
There’s one movie that I really really love that everybody – EVERYBODY – hates.
A movie that came out in 2007.
A movie with a whopping 11% critic score on Rotten Tomatoes and an audience score of 30%.One of the reviews listed on Rotten Tomatoes says “In a word, repugnant.”
And I LOVE it. It’s fucking magnificent.
Alien vs Predator: Requiem is everything the first Alien vs Predator Movie wasn’t. It’s exciting, interesting, over-the-top gory and action-packed, and perhaps most of all it plays with the conventions of a movie like this and subverted my expectations in a wonderful way on a couple of occasions. But the real reason I love it is the same reason that everybody else hates it.
If you haven’t seen it, spoilers.
As far as I’m concerned, in a movie with “Alien vs Predator” in the title, the humans are fodder. I don’t want an interesting story where I want the humans to get out alive. I don’t want relatable characters who aren’t predators. I just want to watch Aliens and Predators kill each other, and hopefully a whole bunch of puny humans will get caught in the crossfire. If you can weave an interesting and compelling story around that, that’s a bonus. Or, you could just not have any humans and have a 2-hour, dialogue-less, action-packed extravaganza, but nobody would ever make that movie.
Ideally instead of making the two Alien vs Predator movies they made, they would have just filmed the excellent script written by Peter Briggs in the 90s. But for some reason that didn’t get filmed (I suspect probably budget, it would have been super expensive in the 90s or early 2000s), and we ended up with what we got.
So in an ideal world, there might be one or two human characters who work with the predators. This is the one thing that seems to have been carried over fromm the Peter Briggs script into the actual film. Except that they did it poorly and made the human weak and dependant on the predator. In Briggs’ script the human warrior chick is a total badass and stands on pretty-much equal ground with the predator. I’m pretty sure she even saves it’s life a couple of times (it’s been 20 years since I read that script so my memory is a bit hazy). At the end of the movie she goes off to live with the predators.
A bit of background: I was very much into the idea of AvP before the movies happened. I had read the Briggs script but none of the comics. I loved the arcade beat-em-up game where you can play as a human or a predator. I knew a bit of the lore around it (e.g I knew about the fact that the xenomorph takes on characteristics of its host, hence the 4-legged ‘dog’ alien in Alien 3, and I therefore knew about Predaliens. The Briggs script features six-legged Aliens because it’s set on an alien planet with six-legged wildlife). James Cameron has said that making an AvP movie de-legitimises the franchises – he had been talking/thinking about doing an alien 5 but dropped the idea because he heard they were going ahead with AvP. I see his point, but the way I see it it’s like Godzilla vs King Kong – it’s just awesome, silly, spectacular fun. It doesn’t take anything away from the other franchises, and it can either live separately from both or it can meld the two canons together wonderfully. But most of all it should be schlocky, violence-packed action. If you can also make a thoughtful sci-fi film (like Briggs wrote) then so much the better, but that’s optional. The important thing is action and violence. In summary, I was very very eager for the first AvP film, and I was pretty disappointed.
I don’t hate the first AvP, but it’s mediocre at best. It pointlessly mangles the canon of both franchises by trying to throw in needless and meaningless references and “fanservice”, and it gives us a boring story and characters that I don’t care about. At all. Perhaps the ur-example here is that Lance Henrikssen is in the film. Now don’t get me wrong – I love Lance Henrikssen – but he has no place in this movie. He’s Bishop, and he’s the guy who designed Bishop, a couple of hundred years in the future. He’s not “Charles Bishop Weyland”. That’s just stupid bullshit that is trying to be fanservice but fails because it’s nonsensical. I can appreciate what they were trying to do, but I think the biggest sin the first movie makes is that it’s just bland. Followed closely by the huge jumbled mess of canon it creates, and that’s followed closely by the lack of Aliens fighting Predators that I came to see in a movie called Alien vs Predator. It’s not nearly violent or action-packed enough. At some point somebody said “but it NEEDS to have a story!”. So they did their best and wrote this boring mess. AND to top that all off there’s no predalien in the movie until the closing scene, when it chest-bursts from the dead predator. That is literally the most exciting thing in the movie – the hook that we might get a sequel with a predalien.
And we sure did. The second movie is. Fucking. Awesome.
I LOVE that the characters are all cardboard cut-out and one-dimensional and not interesting. They’re all expendable. Their function is to deliver a bit of exposition here and there, and to die horribly and violently. And the writers knew it. I believe that’s what they were going for. The story is almost a parody of what you’d expect the story to be in a movie like this. It doesn’t matter whether they can act, as long as they can speak the lines they’ve been given so that I can understand what they’re saying. The most interesting thing about them is what creative and interesting patterns of red they’ll make when they go splat.
Take, for example, my favourite moment in the movie. The movie starts with the dorky underdog kid who likes the hot girl who is friendly to him. The hot girl’s jock boyfriend is a total dick and bullies the dorky kid. She breaks up with the jock and ends up in this life-or-death Aliens vs Predator situation with the dorky kid.
SO, this being a movie, we’re 15 minutes in I know exactly what’s going to happen: The dorky kid and the hot girl are the main characters, and they’ll be the last survivors, possibly with one or two others. The dorky kid will find strength within himself and will protect the girl and she’ll totally fall for him and he’ll get the girl in the end. Aaaaw. It’s so cliche it makes me want to vomit.
And then she gets suddenly and unceremoniously pinned to a wall by a predator shuriken.
It’s fucking awesome. My reaction was instant and ecstatic – “Whoa! I didn’t see that coming!”. I actually had an audible reaction the first time I saw it. I think I might have even clapped. That’s a big achievement, I’m not the type who reacts like that. This is how you subvert expectations! I was instantly more engaged with the movie because now that you’ve killed her off, anything goes. It’s possible that nobody might get out of this alive. The stakes are instantly way higher and now I believe that anybody can die. It turns out that I don’t have any idea how this story is going to end – perhaps the aliens will win? Who knows.
And it doesn’t disappoint. As somebody who loves a dark movie (I love alien 3 for that reason), I loved the end, where the army actively lures the civilians into the center of town to be bait and then nukes the whole goddamn town. There are a handful of survivors out of who knows how many – thousands? tens of thousands? maybe even a hundred thousand? I don’t know how big the town was supposed to be, but this movie has a serious death-toll. It’s brilliant and dark and cynical and exactly what would really happen, and I fucking love it. And it has a bunch of cool, R-rated action with a predator hunting aliens and fighting a predalien. What’s not to love?
And seconds after I thought of AvP2 as my entry in the unpopular positive opinion challenge, I realised that I actually had two. I mean there are a bunch more, particularly if you loosen the criteria a bit – I adore Tango and Cash, for example – but there is a second entry which is just as great and equally as reviled and which I can’t not mention.
Postal.
It’s the only Uwe Boll movie I’ve seen. I know his reputation. I had the movie recommended to me by a friend. I was a big fan of the second postal game, with its very dark sense of humour and its early open-world gameplay, but I don’t think I even knew that there was a movie adaptation. And I certainly wouldn’t have been interested in seeing it. Particularly if I’d seen “Uwe Boll” in the credits. But a friend told me it was hilarious, describing the opening sequence, and I had to check it out based on that.
And it’s fucking hilarious. It’s exactly what a postal omvie should be.
And that’s about all I can say about it without spoiling it. If you like your humour super dark and politically incorrect, go watch it.
There’s so much to love here: The replacement of Gary Coleman with Verne Troyer and the prophecy about a tiny man being raped by a thousand monkeys. The cop wo keeps a homeless disabled guy in his garage at night so that he can wheel him out to beg for money from people during the day, which the cop then takes. The ending, with Osama and Dubya skipping off into the sunset hand-in-hand while mushroom clouds form.
But I particularly adore the entire sequence at “Little Germany”, with Vince Desi (helpfully subtitled as the game’s producer) fighting Uwe Boll, Uwe Boll admitting that he finances his films with Nazi Gold, and last but certainly not least, the gleeful focusing on a whole bunch of innocent children being accidentally shot in the crossfire. I laughed out loud. A LOT. For a good while.
There’s not much to this movie, really, and I don’t have a huge amount to say about it: It’s a stupid, over-the-top subversive comedy filled with humour as black as Saggitarius A*. And that’s why I love it. Even if nobody else does.
Both of these movies are silly. Both of them are hugely entertaining and exactly what they should be. Both of them are reviled. And i love them both dearly.
Do what I did: Go see it on faith – it’s a Quentin Tarantino film. I didn’t watch any previews or trailers, I didn’t watch or read any reviews. I went in knowing the basic outline and that’s it. I didn’t even need that, all I need these days is “directed by Quentin Tarantino”. But it sounded like an interesting premise, too.
I loved it. And I think I loved it more because I didn’t bother with trailers or reviews.
I don’t really think I can say anything else about it without potentially spoiling it. Except that you should go see it.
Maybe I’ll come back and write something about it in a while when it won’t be so spoileriffic.
…Aaand it’s now been 50 years since we landed on the moon. Probably the most important achievement in human history. And nobody seems to care. I found like 3 events in the city celebrating it. 2 were kinda lame, and one (the scienceworks one, which was also lamer than it should have been) was sold out. At least the “sold out” bit is encouraging.
Now, not only can I use the expression “We can put a man on the moon but we can’t <X>“, but I can also say “half a century after landing on the moon and we’re still <X>“.
I’ve been listening to the excellent Apollo in Realtime site for most of the day. I can’t recommend it highly enough. It’s interesting getting a sense for just how slow and methodical everything was. I think I might do Apollo 13 in realtime next.
So the new Hellboy movie is finally here. I figured I’d post some thoughts:
Fuck you fuck you fuck you fuck you fuck you.
Why would I watch a Hellboy reboot when you refused to conclude the already excellent trilogy?
Let’s just set aside the tired old “Gillermo Del Toro is the perfect director for Hellboy”, “Ron Perlman is the perfect actor to play Hellboy”, and “Mike Mignola was involved in the writing” arguments and just focus on one thing: Franchises.
Let’s assume that this new Hellboy reboot is amazing, better than what Del Toro, Mignola, and Perlman would have done (I know right, but let’s just assume a miracle). Lets assume that it’s a masterpiece and the greatest movie ever made, and not just a slapped-together incoherent cash-grab mess with no real interest in or respect for the subject matter like so many reboots are. What then?
Well, obviously, it becomes a franchise! Because that’s the done thing these days! There will be sequels! “Hellboy 2: The…uh…platinum? army” gets greenlit and goes into production. And takes a few years to make. The same team comes back. They set it up as the second chapter of an epic trilogy and it’s amazing.
But like the hollywood studio you are, some exec goes “OOH SHINY!” When someone comes along with a concept for yet another Hellboy reboot rendered in claymation. So you reboot it yet again rather than completing this new and even better trilogy. And now I’m left with two excellent, unfinished Hellboy stories.
You see, by not completing the previous (excellent) trilogy with Del Toro and Perlman, you’ve undermined your credibility: Why would I get invested in Hellboy again when you’ve already shown that you don’t have the attention span to conclude the existing trilogy? Are you going to sign a written contract guaranteeing me that this time you’ll definitely let the director conclude his vision? I don’t think so. And even if you did sign that contract, then I’d have to re-open the issues set aside above. So I see no reason to be interested in the slightest. Which is disappointing for everyone really, I think an R-rating could really suit Hellboy. But given that I have to assume that the next movie in the series will be 2021′s Hellboy reboot with a new cast and director, followed by 2025′s Hellboy reboot with a new cast and director, I’m not able to be interested in this. Which brings me back to my original position: fuck you fuck you fuck you fuck you fuck you fuck you.
Mad props to my homie Ron Perlman for having principles and refusing to be involved without Del Toro.
Recently the complete edition of Civilization: Beyond Earth went on sale. I think I paid about $10-15 for it. I’d been waiting for this to happen for a couple of years, since I insist on buying the whole game rather than buying it in 3 transactions (I want all the DLC, i.e the whole game), and because you’ll have to do something really special to make me think about spending $60 for a game.
I’ve just finished my first playthrough, and here are my thoughts. They’re not easy to sum up in just 200 characters.
Let me start by saying it’s good. You’d expect it to be – they’ve done like 15 Civilization games so far, so they should have a good idea of what works and what doesn’t. You’d expect anything under the Civilization banner these days to be super-polished and addictive. And it is, with the usual caveat that the AI isn’t particularly smart. But I’m willing to let that one slide since we don’t have general AI yet – it’s a complex game and building an AI for it is not going to be easy.
Weirdly, I found it both more and less complex than Civ V (the most recent one I’ve played, I have Civ 6 but have only put in maybe an hour so far). For instance, the diplomatic options seem very cut-down – you can’t e.g surround an enemy with a huge army and then demand a “gift”, or even have any customised dialogue – the options are limited to making trade agreements and setting a cooperation level (ranging from war to allied). That’s it. This seems to be a curious change for a Civ game, given that the diplomacy is such a big part of it. So it’s less complex, but at the same time there are a bunch of new mechanics that make it more complex, e.g orbital units, which I think are cool but didn’t strike me as particularly useful – I ignored them for most of the game.
I haven’t played Alpha Centauri in a couple of years, but I remember being really really impressed with it. I don’t think this is as good. And it’s not as good as Civ V, which might be the ultimate version of Civilization – it’s super-super-polished, faithful enough to the older games that I didn’t notice anything missing, and yet has enough new stuff that seemed to fit in well that I felt like it was more than just a rehash.
It pains me to say that any of these are better than the original, Civ 1, but objectively speaking I’d say that all of these probably are – I still play Civ 1 occasionally and compared with these games it feels kinda simple, and the graphics are antiquated. It is still hugely fun and massively addictive and it’s undoubtedly one of the most important games ever made, but if you’re new to Civ you probably want to start with Civ V.
Another pet-peeve I had with beyond earth is the technology / science system – I feel like the tech web idea (it’s a web rather than a tree) precludes a logical progression of science, because the dependencies for any given item aren’t particularly deep. So you could theoretically go to the end of a particular branch of the web by researching only 4 or 5 prerequisites, as opposed to the more conventional tech tree where railroads require steam engines, which require alloys, which requires steel, which requires metallurgy, which requires bronze, etc etc etc. Granted, the tech web is perhaps more realistic and reflects how you could change the focus of your research drastically and that research in computing is probably not going to impact biology very much, but I think the deeper tech tree with less choices at each branch is a better game mechanic.
The other problem I have with the tech tree/web in this game is that I felt like most of the technologies and unit names were just made up technobabble – I’m somebody who knows his sci-fi and futurism and I didn’t find myself saying “oh I know what that is”. And in a few cases I did know where something was, and was disappointed that the game didn’t really give me that. For example, there’s a mass driver. I said “ooooh cooool, mass driver!”. And then I got an improvement that gave my city better offensive capabilities, no mass driver graphic or animation to be seen, no weeapon I can target enemies with to throw meteors at them. In my book this should have been a devastating orbital unit, but nope. Note that this doesn’t apply to all of the technologies or units – some of them are logical hypothetical technologies and some of them do just what it says on the tin. But a lot of it is researching inverse phase polarity infusers, which give you a temporal gyreforge improvement that for some reason gives your city +3 production, or whatever. It’s been a while since I played Alpha Centauri, but I seem to recall that having a more logical tech tree, and the units/improvements you get from each tech make more sense with regard to what each technology is. But I might be wrong about that. Maybe it’s just that I’ve played regular Civilization more recently, and it has a very logical tech progression where you automatically know what everything is, as per my rail example above (which is just off the top of my head, but is probably fairly close to the actual progression).
I found several things in the UI unintuitive. For example I was about two-thirds of the way into the game before I figured out how to assign specialists, i.e where you assign a citizen as a scientist or engineer to get a science or production bonus. At first I assumed it didn’t have them, and then I figured out that you have to check the ‘show buildings’ checkbox, and certain buildings give you slots for specialists which you can click to assign. Another example of the unintuitive AI was that at a certain point I noticed that the colour of the aliens had changed. At first it was blue and then at a certain point I noticed it was orange. It was only when I destroyed a nest and the aliens changed from orange to red that I realised that they were getting more and more hostile. This despite me having all the advisors turned on, and it telling me every 3 turns that I can change my personality traits, and me screaming “yeah I’m happy with the ones I have, shut up!”.
Don’t take all these criticisms as me saying that the game isn’t great, though – it still has that addictive “one more turn” thing going on that you expect from a Civ game. But I don’t think it’s as good as Civ V or Alpha Centauri. If you’re looking for a purchasing recommendation, here’s mine: Buy Civilization V complete when it’s on sale ($80?!? seriously?), then buy Alpha Centauri on GOG (Listed at AU$8 at the time of writing including the expansion, a fair price), and then buy the complete edition of Beyond Earth when it’s on sale. If you can get the complete edition for $10-15 it’s worth it. If you don’t already own Civ V and Alpha Centauri then I’d recommend getting those first. I’m just going to assume you already own Civ 1. Which strangely doesn’t seem to be on GOG at the time of writing. Luckily, I own a boxed copy for the Amiga. </bragging>
Note that, of course, all these games support Linux. You might think that Alpha Centauri doesn’t, but loki games did a port back in the day. Apparently it can be difficult to get it running on modern systems, and that may or may not be true for the GOG version, but this installer works just fine on my xubuntu 16.04 laptop with my original Alpha Centauri CD. The only issue I have with Alpha Centauri is that it insists on running at 1024×768, which means it’s fairly small on my laptop screen, which won’t actually switch to that resolution. If you have a way to make it run at 1920×1080 (or 1680×1050), I’d love to hear it – the only info i could find was for the windows version. But it doesn’t make the game less awesome.
As of today I’ve spent half my life contributing to SETI@home!

I’m ranked #2241 in the world in terms of total CPU time donated, and #62 in Australia. In terms of active users, I’m ranked #985 out of 1,738,452 in the world.
Stats
Microsoft announces the ruination of github.
Because apparently destroying skype, linkedin, hotmail, etc etc etc wasn’t enough.
I can’t fathom the rationale behind this. Apparently there’s an accounting thing that having lots of users means you’re worth lots of money. So, 7.5 billion.
BUT surely there’s nobody out there who doesn’t think that MS buying github will immediately lead to an exodus of most of its users? As far as I’m concerned it’s a given: MS buys github, github users leave en-masse. I know it’s what I’ll be doing.
So basically MS is buying a website which will no longer have any users for 7.5 billion. Good luck with that.
I’d find it funny if it wasn’t so tragic. I liked github. Just like I liked skype.
“It’s always darkest before the dawn”
– Morons
It isn’t. Before dawn, there’s a period called “pre-dawn” where there’s a glow on the horizon from the approaching sun. This is the ~hour-long period between astronomical sunrise and actual sunrise. And it’s fairly bright. That’s why astronomers make a distinction between astronomical sunrise/sunset and actual sunrise/sunset – because the light from the sun in this period is enough to interfere with astronomical observations.
So, to summarise, just before the dawn there’s a period of dim light which is actually as bright as the night gets before actual daytime (barring things like supernovae). The darkest part is around midnight when the sun is on the opposite side of the planet. It’s not always darkest before the dawn, it’s darkest before the period of light before dawn. And in fact that’s not even “darkest”, because you have things like stars and the moon lighting things up. It’s actually darkest in caves, where there is no dawn.
But who lets facts get in the way of a bland metaphor?
Apparently you have to own a game to review it on steam, and since I’ve been playing a friend’s copy of ARK via family sharing, my opinion is meaningless. The best part is that they let you spend time writing your review and then tell you that you can’t review the game when you press “post”. So here’s my review of ARK: Survival Evolved:
Hugely impressive and ambitious, but not finished. ARK has the potential to be a really excellent game, if all the bugs are ever ironed out. At first the bugs will just be annoyances, but once you’ve put some real time into this game they’ll come to rule your experience and you’ll find yourself increasingly frustrated.
Two particularly big ones are dinosaur AI and building structures. You’ll find your tame dinosaurs getting constantly stuck while they’re trying to follow you, to the point that you’ll have to turn around every minute or so to count how many dinosaurs are following you and go back and rescue stragglers. This isn’t such a big deal when you have 3 dinos following you a small distance, but it becomes incredibly tedious when you have 15 and you’re on an epic 20km journey. As for building structures, I hope you like grinding to collect resources, because you’ll spend 20 minutes collecting stuff to craft a piece of a structure, and then the game will refuse to place it where you want it, so you have to demolish something and go out to collect the necessary resources to rebuild in the esoteric order the game wants. Or the game will place it in the wrong place, or in the wrong direction, and you’ll be left with no choice but to demolish the structure and go out and collect more resources to rebuild.
If you search around a bit, you’ll find that both of these issues have been problems for YEARS, and that no fix seems to be forthoming. It seems that the devs are busy building DLC rather than finishing the game. See also the fiasco where the scorched earth DLC was released while the game was still in early access. Apparently the solution to that was to just remove the ‘early access’ tag, to hell with the bugs.
I’d really like to recommend ARK, there really is a fantastic game buried under all those bugs, and perhaps one day these issues will be addressed and I’ll re-visit this review, but as it stands this game is regrettably not worth the AAA price tag attached to it. If you can get it for less than $20 with all the DLC then I’d say it’s probably worth it.
Click on thumbnails for fullsize images (Warning: ~7mb each)




Taken at -38.22701 145.30671 on the night of 31/01/2018 through a Celestron C6 with a Nikon D3200.
Well, it’s finally here. I’ve been waiting for over a decade.
And I’m still waiting.
This is not Star Trek.
I tried to give it a good chance. I saw the “Klingons” in the trailer. I figured they were some new alien race. Then I heard that they were Klingons, and I worried.
But I didn’t worry too much – they’ve changed the look of the Klingons before. Of course that change has now been explained in canon, and changing them in a show set 10 years before Kirk is problematic, but I suppose if you’ve got clever writers you can explain it.
Plus, the label on it says “Star Trek Discovery”. Discovery! it doesn’t get more trek than discovery! That’s what it’s all about!
So I watched the 2 hour JJ Abrams TrekWars (TM) movie that was the pilot. But it was clearly just a prelude movie. The actual pilot will come with episode 3. So I kept watching.
I saw a million issues. Violating the prime directive (which is now called “general order 1″ for some reason) in the first 5 minutes wasn’t a strong start. The “Klingons” who speak Klingon like someone who doesn’t speak Klingon reading Klingon off a page while wearing half a ton of latex which stops them from speaking properly wasn’t a good sign either. The idiot main character who does every. single. thing. wrong isn’t winning me over. Everything looking wrong wasn’t a good sign either. But I tried to be impartial and fair.
Episode 3 was… meh. Episode 4, very meh. But it wasn’t un-fixable. Maybe they were just trolling me, daring me to stop watching before they do something amazing to fix all this brokenness. Maybe this is the rogue starfleet ship where the captain is a cunt and has recruited a band of cunts to assist him in his mission of being the biggest cunt of the 23rd century, and soon we’ll see an actual starfleet ship come along and bring this renegade to justice. By the end of episode 4, this seemed unlikely, but I was willing to give it a chance.
And then you had to go and say fuck.
I was already completely disgusted by the time you said fuck, that was just the final nail in the coffin. Let’s go through some of the issues I had before you got to the “oooh, let’s be edgy by saying fuck!” moment:
…And then came the straw that broke the camel’s back: Starfleet officers say fuck now? The phrase “fucking cool” is about the least Star Trek thing a person can possibly say. Yes, there have been precedents, like the ill-advised time Data said “oh shit” in one of the movies. But that was a horrible moment we’d all prefer to forget. You’re not being edgy by saying it, you’re just making it even less Trek than it already was.
And just in case my bile hadn’t already risen:
There are probably other things, but I’d have to watch this godawful dreck again to list all the issues. And there’s no way I’m doing that to myself.
In conclusion, fuck you. This is not Star Trek.
Maybe, if the Internet is swept with comments like “OMG these guys are geniuses! This IS Star Trek!” in 10 weeks, then maybe I’ll think about watching the rest of them. But we all know that’s not going to happen, because you don’t give a shit. You wanted to make Generic Action/Sci-Fi show #48911, not Star Trek.
The funniest thing about this is that if you had given this show any other name, I’d be all over it. I love me some dark sci-fi. I’d love to see an adult sci-fi show with tons of drama and heaps of conflict between cunty characters. But not in a Star Trek Show. You would literally have been better off calling it “Generic Action Sci-Fi show #48911″. I’d watch that, and I’d probably enjoy it. But because you’ve slapped a Star Trek label on it, I spend the whole time just thinking about how apparently everyone in Starfleet was a cunt 10 years before Kirk came along, and how every single thing is broken, and how Gene Roddenberry is turning over in his grave.
Dear Jason Isaacs: You dared me to not watch it? Challenge accepted!
There is a positive here: Next time I watch Enterprise, I’m gonna be all like “OMG this is amazing! They put in so much effort!”. In a strange way, by not giving me a new Star Trek series, they’ve given me a new Star Trek series – I’ll have to go and re-watch Enterprise, because it’s gonna seem awesome compared to this.
And there’s another positive: William Shatner is no longer the cuntiest Trek person! Say hello to your new cunty overlord – Jason Isaacs!
And there’s yet another positive: maybe after this horror show is over, Star Trek will finally be dead. With a little bit of luck this will manage to de-value the entire franchise, and it’ll go to its grave for another 20 years or so. And in that time, since the franchise won’t be worth anything, maybe we’ll get some good, real Star Trek in the form of the fan films you’ve done your best to ban.
I think I’ll go watch some real Star Trek to wash this taste out of my mouth.

Welcome to the wonderful world of Web three point oh! Where we’ve replaced all the content you loved with encrypted, incompatible bullshit designed to strip you of your rights.
Thanks, Tim Berners-Lee!
The reason I don’t use twitter? It’s very simple, I’m a loquacious type and I don’t see how I could ever express myself in only 140 charact
The other day I needed to move my Linux install to an SSD, but there were a few issues:
Here’s how I did it:
sudo rsync -aXS --exclude=/media/old/home /media/old /media/new
(Note: I found that using ‘v’ (verbose) in the rsync command slows things down significantly, since there are many small files and most of the time is spent outputting and scrolling text when in verbose mode)
mkdir /media/old/old_root mv /media/old/* /media/old/old_root (check for hidden files/folders in root and move them individually with ls -a and mv) mv /media/old/old_root/home/* /media/old/
for f in dev sys proc usr; do sudo mount --bind /$f /mnt/new/$f; done sudo chroot /media/new sudo update-grub2 sudo grub-install /dev/sdb
sudo mkdir /SSD sudo chown -Rf username /SSD mv ~/Work/codebase /SSD/codebase ln -s /SSD/codebase ~/Work/codebase mv ~/workspace /SSD/workspace ln -s /SSD/workspace ~/workspace mv ~/VMs /SSD/VMs ln -s /SSD/VMs ~/VMs (repeat for anything you want to load faster)
Most of the tutorials for moving linux from one machine to another assume that you’re moving to a bigger disk, or assume that you are using less than 50% of available disk space. In my case, where neither of these was true, I found this method of moving things around on the 1tb disk to be efficient in terms of time and space – moving files around on the same disk is very fast on Linux, since it doesn’t actually need to copy the data, so the ‘mv /media/old/* /media/old/old_system’ and ‘mv /media/old/old_system/home/* /media/old/’ took seconds. The slowest part of this entire procedure was the rsync – copying the OS onto the SSD. Overall I found this process to be fairly simple and painless – I was a little apprehensive about it, but it turned out that moving to a new disk really is quite simple.
I found this page quite helpful when doing this (in particular, installing grub on the new disk).
My Maniac Mansion remix is now available on remix64.com
And all they had to do was refund my $2.49. They tried to tell me they were above the law. I told them they weren’t. Seems like the courts agree with me.
So in addition to not ever getting another cent from me, Valve got dragged through our courts and will now be fined. And they refunded my $2.49 plus fees (I did a chargeback).
It’s always nice when justice actually happens.
Today I wanted a way to pretty-print a JSON string with colour highlighting. I went looking and found a bunch of ‘pretty print’ functions, but none with colour, so I implemented my own
Usage:
echo("<style>".Convert::jsonPrettyHtmlCSS()."</style>");
echo(Convert::json2PrettyHTML('["a",{"foo":"bar","baz":42}]'));
….And the code:
<?php
class Convert {
/**
* Helper for Convert::prettyJSON()
* Returns a HTML <span> with a class matching the data type (integer,string,double,etc)
* Add css to colour the values according to type.
*
* autodetects numeric strings and treats them as numbers
*
* runs htmlentities() and wordwrap() on values (wraps at 100 chars)
*
* @param mixed $val value to beautify
* @param int $indents number of indents
* @param bool $isKey true if this is a key name
* @return HTML
* @see Convert::prettyJSON()
* @see Convert::json2PrettyHTML()
*
*/
private static function jsonColor($val,$indents=1,$isKey=false) {
//echo print_r($val,true) . ": " . gettype($val) . "\n";
$type = gettype($val);
if (($type == "string") && is_numeric($val)) {
//try to convert it to a number
$val = floatval($val);
if (intval($val) == $val) //convert from float to int if it's a whole number:
$val = intval($val);
$type = gettype($val);
}
//$type = gettype($val);
$color = "";
switch($type) {
case 'string':
$val = '"' . $val . '"';
break;
case 'array':
$val = self::prettyJSON($val,$indents);
break;
}
$val = wordwrap(htmlentities($val),100,"<br />",true);
if ($isKey) $type = $type . " key";
return "<span class='$type'>" . //"' style='color:$color;'>"
"$val</span>"; // . " (" . gettype($val) . ")";
}
/**
* Helper for Convert::json2PrettyHtml()
* convert a value (i.e from json_decode) into a pretty colourised string
* @param array|string|number $json value to prettify
* @param number $indents indentation level (used for recursion)
* @return string
* @see Convert::json2PrettyHTML()
*/
private static function prettyJSON($json,$indents = 1) {
$ret = "";
$indent=str_repeat("<span class='indent'> </span>",$indents);
if (is_array($json) || is_object($json) ) {
foreach ($json as $k => $v) {
$k = htmlentities($k);
if (is_array($v) || is_object($v)) {
$v = self::prettyJson($v,$indents+1);
$ret .= ($ret ? ",<br />\n" : "") . $indent .
self::jsonColor($k,$indents,true) . ":\t<br />$v";
} else {
$ret .= ($ret ? ",<br />\n" : "") . $indent .
self::jsonColor($k,$indents,true) . ":\t" . self::jsonColor($v,$indents);
}
}
if (is_object($json)) {
$openbrace = "{";
$closebrace = "}";
} else {
$openbrace = "[";
$closebrace = "]";
}
$outdent=str_repeat("<span class='indent'> </span>",$indents-1);
$ret = "$outdent$openbrace<br />\n$ret<br />\n$outdent$closebrace";
} else
$ret = self::jsonColor($json,$indents);
return $ret;
}
/**
* Return or add some CSS for json2PrettyHTML to the requirements
* @param string $return if true, return the CSS. Otherwise insert it using Requirements::customCSS()
* @return string | void
* @see Convert::json2PrettyHTML()
*/
public static function jsonPrettyHtmlCSS($return = true) {
return 'span.json .integer, span.json .double {
color: #700;
font-family: mono;
}
span.json .string {
color: #070;
font-family: mono;
}
span.json .key.string {
color: #007;
}
span.json .key.integer, span.json .key.double {
color: #707;
}
span.json .indent {
padding-left: 40px;
}';
}
/**
* Converts a JSON string to pretty, readable HTML output which can be
* colourised/customised via CSS
*
* Also does other nice things, like word wrapping at 100 chars, running
* values through htmlentities(), and treating numeric strings as numbers
*
* Include CSS to style the output (set colours, indent width, etc)
* Notes:
* - everything will be wrapped in a span.json (i.e <span> with 'json'
* as the class, css: span.json)
* - keys will be spans with the'key' class ( e.g span.key )
* - values and keys will be spans and will have the datatype as the
* class ( span.integer, span.key.integer)
* - there will be empty spans with the 'indent' class in the
* appropriate places. There may be more than one consecutively.
*
* Example CSS is returned by the jsonPrettyHtmlCSS() function
* @param string $json the json to beautify
* @return HTML
* @see Convert::jsonPrettyHtmlCSS()
*/
public static function json2PrettyHTML($json) {
return "<span class='json'>" . self::prettyJSON(json_decode($json)) . "</span>";
}
}
I hope someone finds this useful! ![]()
Oh yeah baby! Finally we’ve managed to detect gravitational waves! Go LIGO! Go Science! This is a big deal, up there with the Higgs Boson discovery. This is one of those discoveries where I’ll look back and remember the time before we had observed black holes directly.
Sad Face.
RIP David Bowie.
Thanks so much for visiting, spaceboy, you brightened this little world. We’ll miss you.
Space boy, you’re sleepy now
Your silhouette is so stationary
You’re released but your custody calls
And I wanna be free
Don’t you wanna be free?
Do you like girls or boys?
It’s confusing these days
But moon dust will cover you
Cover you
This chaos is killing me
So bye, bye love
Yeah bye, bye love
Bye, bye love
Yeah bye, bye love
This chaos is killing me
Hallo space boy, you’re sleepy now
You’re silhouette, so stationary
You’re released but your custody calls
And I wanna be free
Don’t you wanna be free?
Do you like girls or boys?
It’s confusing these days
But moon dust will cover you
Cover you
And the chaos is killing me
Yeah bye, bye love
So bye, bye love
Yeah bye, bye love
So bye, bye love
This chaos is killing me
This chaos is killing me
Yeah bye, bye love
Bye, bye love
Eternal
Sweet, sweet love
Bye bye space boy
Bye, bye love
Moon dust will cover you
Moon dust will cover you
Moon dust will cover you
Moon dust will cover you
Moon dust will cover you
It’s only been 8 years. Here is an album showing the best astrophotographs from my trip to Grove Creek Observatory in 2007.
The Operative: Do you know what your sin is, Mal?
Mal: Aw hell, I’m a fan of all seven. (headbutt) But right now, I’m gonna have to go with wrath.
- Serenity
I’m also a fan of all seven. Here’s my list, in descending order of awesomeness:
Ladies and gentlemen, presenting: kgrep – kill-grep
This is a bash function which allows you to type in a search term and kill matching processes. You will be prompted to kill each matching process for your searchterm.
You can also optionally provide a specific signal to use for the kill commands (default: 15)
Usage: kgrep [<signal>] searchterm
Signal may be -2, -9, or -HUP (this could be generalised but I CBF).
search term is anything grep recognises.
kgrep() {
#grep for processes and prompt whether they should be killed
if [ -z "$*" ]; then
echo "Usage: $0 [-signal] searchterm"
echo -e "\nSearches for processes matching and prompts to kill them."
echo -e "signal may be:\n\t-2\n\t-9\n\t-HUP\n to send a different signal (default: TERM)"
return 0
fi
SIG="-15"
#yes, this could be more sophisticated
if [ "$1" == "-9" ] ||
[ "$1" == "-2" ] ||
[ "$1" == "-HUP" ]; then
SIG="$1"
shift
fi
#we need to unset the field separator if ^C is pressed:
trap "unset IFS; return 0" KILL
trap "unset IFS; return 0" QUIT
trap "unset IFS; return 0" INT
trap "unset IFS; return 0" TERM
IFS=$'\n'
for l in `ps aux | grep "$*" | grep -v grep `; do
echo $l
pid=`echo $l | awk '{print $2}'`
read -p "Kill $pid (n)? " a
if [[ "$a" =~ [Yy]([Ee][Ss])? ]]; then
echo kill $SIG $pid
kill $SIG $pid
fi
done
unset IFS
}
October 21 2015, the day “30 years in the future” Marty and Doc travel to. 4:29pm to be precise.
Technically the time will be 9:29am on Oct 22nd for me since they’re on californian time, but I’m watching the trilogy on Oct 21 Australian time. Close enough.
I’m disappointed that Nike hasn’t released power laces yet. Maybe they’ll announce them tomorrow. I’ll buy that shit.
Update: Yep! Awesome!. I wonder how ridiculously expensive they’re going to be.
Simple! Restrict all intarwebs access to everything that you don’t absolutely need:
sudo -g vboxusers virtualbox
sudo iptables -A OUTPUT -m owner --gid-owner vboxusers -d [ip address] -j ACCEPT
sudo iptables -A OUTPUT -m owner --gid-owner vboxusers -j DROP
If you follow these simple steps, you never have to worry about your testing VM reporting everything you do back to Microsoft.
For extra security, i recommend disconnecting the virtual network cable before you close the VM. That way if you accidentally start it without the vboxusers group it still won’t be able to access the internet.
If you’re running windows on bare metal in 2015 I have no advice for you, you deserve whatever happens.
Congratulations to NASA for the first ever Pluto flyby!
I’m days late in saying this, but I was watching events unfold live via NASA TV. I’ve been anticipating this all year, and it’s awesome to finally see Pluto up-close. Great Job! I can’t wait to see more as more data slowly streams back from nearly 5 billion km away.
Links:
This post is my response to This video:
(Archival / downloadable copy)
OK, so I appreciate the tone of your video and your stated motivations for making it. I’m going to try to be diplomatic in my response.
1. Viruses.
The viruses you found were an exe file and a dll file. A windows executables and library. Not exactly a threat, especially if you don’t have wine installed. These are definitely not linux viruses and that machine is not infected – even if you did manage to run a virus-infected exe file, it’s not going to infect any of the other binaries on your system with the possible exception of windows binaries that your regular user has write access to.
The example you give is a really weird one, and I have no idea what is going on. My only guess is that perhaps this ‘imagination’ software (which I’ve never used, though I do see it in my repos) has an ability to optionally run some external windows-vased helper program if you have wine installed. The fact that the files were in /var/tmp indicates that it was your regular user who downloaded them, i.e you did it, or the program has a “download utility x” helper built into it. Or perhaps these files got into that temp directory via other means, and imagination didn’t run simply because sophos wasn’t allowing it to access the infected files.
There’s also the possibility that this was a false positive, and that the exe and dll files were not infected but simply used an executable compressor or something like that.
Yes, you found a virus, but your system was not infected by it. If I go to a website and download a virus intentionally, and then scan my ‘downloads’ folder, I’ll find a virus too. But I won’t be infected. In windows, even having that virus on your system is dangerous because simply double-clicking on that exe could infect a countless number of other executables. Though newer versions of windows have gotten better at protecting system files, and it’s quite possible to infect a whole lot of windows programs if you are using wine.
I will agree that perhaps the wording “Linux doesn’t get viruses” is a bit extreme – there are one or two linux viruses out there, and that perhaps it should be re-worded to something along the lines of “during normal use, linux applications will not be infected by viruses”, with the caveats of assuming you’re only using software from your distributions repository, and you’re not running things as root.
2. Uptime and reboots.
This is just wrong. I never ever reboot my machine, and I update it regularly. In 90+% of cases, this causes no problems at all.
Yes, there are cases where some library might be updated and it might render things which use that library unusable until you reboot, but even in this case, a reboot is rarely necessary – often you can just restart the underlying service or the GUI and things will work fine. Though sometimes it’s easier to just reboot than to figure out what you need to restart. It should also be noted that we’re talking about a miniscule percentage of updates here – usually when a service is updated, the update script will restart it for you.
Yes, from what I understand, systemd updates will likely require a reboot. This is one reason why we shouldn’t be using systemd. But that’s a whole other debate.
The machine I’m typing this on has an uptime of 138 days right now. That’s how long it’s been since we had a power outage. My laptop is at 103 days. My server at work is at 330 days (i.e: since the day it was commissioned). Next time I reboot, it will be using a newer kernel. Until then, everything is fine.
Compare this with rebooting three times during a round of updates.
3. Fragmentation.
You say that linux has “3 defragmenters”, but two of the ones you point out are tools which report on fragmentation, they don’t actually defragment. The two reporting tools are probably not necessary, since e4defrag has the ‘-c’ switch, kind of like ‘egrep’ being an alias for ‘grep -e’. The number of tools available isn’t a big indicator of a real problem, Linux types like to have lots of variety, e.g there are about 100 different tools for doing disk partitioning, but it’s not something a normal person does with any kind of regularity.
I’ve been using linux for 10+ years and I had never heard of these tools, so I did a defrag check on my machine, which initially started out with ubuintu 8.04 and has been upgraded multiple times without reformatting. I use it for everything you can imagine – gaming, audio/video production, media center, and coding. It gets heavy use and its disk has been up to 99% full more than once. I figured that if any disk is going to be fragmented, it’ll be mine.
The fragmentation score on my root volume was 0.
The fragmentation score on my home volume was 1.
I was a pretty damn advanced windows user for a long time before I made the switch, and I can attest that the same usage on a windows machine would have seen heavy fragmentation (actually the same use would have seen multiple reformats and reinstalls to clear out crud, but regular defragmentation would also be necessary). I used to defragment on a regular basis when I used windows (I had it set up as a scheduled task). Until today, I didn’t know that there were even degragmenting tools available for Linux.
Again, the wording on the claim “you don’t need to defragment” could probably use an asterisk on it, with a subtext “during the course of normal use”, and I can see how you think that the claim is misleading, but I think you’re attaching more signifigance to this than it deserves.
4. UUIDs in fstab – you can’t just switch disks.
Here I think you’re just wrong. Sorry, but you are. Yes, it’s true that you won’t get your full whiz-bang GUI interface immediately upon switching a disk from one machine to another, but saying that the system didn’t boot isn’t exactly accurate either. In your video, the machine boots to a grub prompt (which included an ‘advanced boot options’ choice which probably would have allowed you to boot the full system by specifying the root volume, if you knew the invocation to do so [I don't off the top of my head]). But the system also leaves you at a command prompt. It doesn’t give you a blue screen effectively saying ‘please insert your installation CD and reinstall’. From the command prompt you got, fixing this problem is as simple as doing something like:
ls -l /dev/disk/by-uuid
(jot down uuid of the disk in question)
vi /etc/fstab
(change uuid of root volume)
reboot
OK, so for your average nontechnical user, this isn’t obvious or intuitive, but it’s a far cry from a blue screen of death and a reinstall. You’ll note that the instructions above don’t include “insert your installation cd”, though that would also work – you could boot into the livecd environment and make the change you need to make to fstab from a nice gui without reinstalling.
Yes, back when /dev/sdX was being used in fstab, you used to be able to just put the disk in another machine and it would boot the full GUI. Sometimes. Assuming that the ‘X’ was the same on the new machine.
The reason this changed was due to the fact that in a modern distro devices can appear and disappear at any time because they might be plugged in or unplugged at any time. This includes hard disks (though I don’t recommend trying it unless you have a hotpluggable disk!). This support meant that there was no guarantee that /dev/sda would still be /dev/sda the next time you reboot – it might be /dev/sdb when you reboot, meaning that your fstab is incorrect and the system won’t reboot properly.
I’ll grant that perhaps fstab should be using disk labels instead – that would solve this problem (assuming it’s practical), but to do so would mean that all disks would need to have a label, and many don’t. It would also cause issues if you have two disks with the same label (e.g having a volume named “ROOT” in two computers, and taking the “ROOT” volume from one machine and putting it into the other – which “ROOT” should it use?)
I’d also grant that a more descriptive error message in this situation might be helpful, depending on how practical doing that would be. If the console had a message to the effect of “cannot locate root volume – perhaps you need to edit /etc/fstab?” it would be much more intuitive. Hell, it’s probably possible to build a text-based program that does this for you.
Technically, though, since you saw a command prompt and not a kernel panic, the system booted. I guess this comes down to your definition of “boot”.
It’s probably not awesome if people are making the claim that you can just pull the disk out and put it in another machine. There should probably should be an asterisk there, too. But “not booted” isn’t a correct desctiption of the situation either.
In Conclusion
I think you have misunderstood and misinterpreted a few things, leading you to some incorrect conclusions.
I think that this should probably be an interesting lesson for everybody involved – you can learn a few things about linux, and the linux community can learn how its “sales pitches” can be misinterpreted.
You should be careful and make sure the facts are on your side when using words like “misinformation”. Your video falls under that category.
I think you have done everybody a disservice by disabling comments on your video.
Here’s a nifty little piece of javascript I whipped up the other day in response to a client request.
With this code (and jquery) on a web page an element on a web page with the “clicktoprint” class becomes clickable. When clicked, it is printed, but only that element. In addition, the element will be scaled to the full width of the page.
I was asked to do this so that a client could have a voucher on their website which you could click on and have it printed. Their previous solution (using a ‘print’ media query in the site css) meant that the rest of the page could never be printed. This code injects a new piece of css for the duration of the special print and removes it afterwards, allowing the rest of the page to be printed by the regular means.
<script type="text/javascript">
jQuery(document).ready(function() {
jQuery('.clicktoprint').click(function() {
jQuery(this).parents().each(function(idx,i) {
jQuery(i).addClass('clicktoprint-parent');
});
jQuery('head').append('<style id="clicktoprint-style">@media print { * { display: none; } .clicktoprint, .clicktoprint-parent {display: block !important; width: 100% !important;} }</style>');
window.print();
jQuery('style#clicktoprint-style').remove();
return false;
});
});
</script>
The new Mad Max film is finally out. George Miller has been trying to make it for about 25 years now. But don’t be fooled – he hasn’t spent 25 years working on it. Instead, he’s been paying close attention to what hollywood has been doing lately (being braindead), and religiously updating the Mad Max script so that it apes the latest conventions.
I was really excited for it – decades later, I still consider Mad Max 2 to be the greatest Australian film ever made. The trailers made me both more excited, and nervous – That’s the pursuit special! That must mean that this movie is set between the first and second films, right? But the second trailer showed me the flame-throwing guitar, which made me nervous, fearing style over substance.
Still, style over substance isn’t in itself a bad thing – films like Shoot Em Up (which is awesome) are all style, and a balls-to-the-wall, all-style Mad Max film could work, so perhaps it will be great.
It came out, and the reviews started coming in – near-universal acclaim! Wow, maybe it’s actually good.
There’s been some debate over whether it’s a sequel or a reboot. Anyone who thinks it’s a sequel hasn’t been paying attention. But I think that’s the idea – this is a movie for people who don’t pay attention. It’s not a sequel or an interquel which goes inbetween the first and second movies – the pursuit special was destroyed in Mad Max 2. But it’s also destroyed here, meaning that it’s a reboot. I read one argument that it had to be a sequel, because there are flashbacks to the previous films. Whoever said that hasn’t seen the previous films in a long time – none of the flashbacks are from previous films, they’re just miscellaneous flashbacks showing us how haunted Max is. Not that it matters, since he’s not the main character anymore.
Sure, it has lots of spectacular things. And lots of cool things. The vehicles are awesome, and the world is very cool. It looks great. I can’t think that the musical war-rig with its guitarist is anything other than goddamn awesome. But none of it makes any sense – it’s cool for the sake of looking cool, logic be damned.
For instance, if water is precious, why do you hand it out it by pouring ten thousand litres out in the space of 30 seconds? Ninety percent of it is wasted. Wouldn’t handing it out in bottles be much more efficient and less wasteful? Answer: because it looks cool.
If you use human power to raise and lower your war-rigs to the desert floor, how do you pump ten thousand litres of water at such a rate? Answer: because it wouldn’t look cool if you didn’t.
Why are there weird people walking around on four stilts in a swamp? Answer: because it looks cool. Or maybe Miller is just a big Dark Crystal fan.
Why is the war rig loaded with enough water to keep a whole village alive for weeks? Wasn’t it being sent to collect fuel from Gas Town, which is close enough to be visible on the horizon and at worst a couple of hours’ drive away? Answer: because Miller wanted a scene where the wives were hosing each other down, because that would look cool.
How do you keep “mothers milk” from spoiling out in the hot desert for a couple of days? Is the war-rig’s tanker also refrigerated, in addition to having massive water and milk tanks? Is any of that tanker space actually used for the stated purpose of storing and transporting fuel? Why do you even need “mothers milk” for a 2-hour drive?
Why is the fuel pod filled with fuel? Is your war-rig so thirsty that it needs thousands of litres of fuel to get to a place that’s perhaps 15-20km away? apparently not, since I don’t recall them refuelling at any stage of their 3-day high-speed journey. Answer: furiosa had struck a bargain to exchange the full fuel pod for passage through the valley. So I guess she just…uh… stole thousands of litres of fuel from a place where fuel is scarce and precious, and nobody noticed?
Why are there so many american accents in post-apocalyptic Australia? Answer: because it doesn’t matter – you can’t see sound, so it doesn’t not look cool.
And at the end of the movie, they take over the citadel and turn on the pumps so that everybody can drink their fill of water. Aaaw. My reaction: “And they all lived happily ever after for the next 6 months, when they discovered that they’d emptied the aquifer at an unprecedented rate with an unprecedented amount of waste, and everyone died 3 days later.”
Max Rockatansky is now an incidental character in a movie which bears his name. He’s gone from being the ultimate badass anti-hero to being just some savage who is easily captured, communicates in little more than grunts (and when he’s not grunting, he’s talking in a really weird accent) and is just along for the ride.
During the making of this film, the phrase “wouldn’t it be cool if…” was uttered many, many times.
Mad Max 3 wasn’t brilliant, sure, but at least it had something to say – there was some substance there, and genuine world-building. This film has no substance at all, and the world-building is nonsensical – everything is secondary to looking cool, with the possible exception of beating us repeatedly with the “men are bad” sledgehammer.
This movie kind of reminds me of Shoot Em Up, only with less sense, plot and style. If you completely disengage your brain and you have no interest in or memory of the previous films, then you might like this movie.
Oh, wait, I just described most of the population of this planet, so: near-universal acclaim! Expect sequels. Meanwhile I’m going to pray for a porkyclipse.
We had a lunar eclipse last month, and I happened to go outside for a smoke, looked up, and spotted it. Dutifully, I ran inside and grabbed my video camera and tripod and spent the next hour filming. And now I’ve finally gotten around to cutting together some reasonable-quality images:



I took these using my cheap video camera and tripod, then I extracted a bunch of frames from the video and aligned / stacked them.
This was a bit of a challenge, since the astrophotography software I have (CCDSoft) doesn’t seem to like noisy colour JPEG images very much and kept crashing, so I had to do everything with the GIMP, including manual alignment. Not fun – the third image above is a combination of 30 video frames, aligning that was a bitch. I might have to write a gimp plugin for that.
I did look at open-source astrophotography software, but the options seem to be a bit lacking. I tried a couple – siril looks like it’s the most promising, but it refused to stack my images, giving me a weird error for which teh google was no help. But it’s brand new – the latest update on the website was only a couple of weeks ago, so hopefully in a little while it’ll be useable.
For comparison, here’s a “before” shot – a raw frame of video, in all its noisy glory:

This kind gentleman just helped me out with a problem I was having on IRC. his How to help page suggests linking to him, so that’s what I’m doing, because I’m damn cheap.
Go visit his website and give him money.
Apparently, some people don’t like Bicentennial Man. I’ve even heard Robin Williams reference it in a stand-up routine.
IMHO, this is just another example that people are idiots – Bicentennial man is goddamn awesome.
I was really excited when I heard about this movie – I had wanted to see an Asimov movie since I read the books. At the time, there had been talk of adapting I, Robot to the screen for a while – it was in development hell for a long time, and the less said about the outcome, the better.
But Bicentennial man beat I, Robot to the screen by about 5 years and became the first movie based on an Asimov book. Ironically, there wasn’t ever any competition with I, Robot, because it wasn’t “based on” an asimov book – they invented a new credit for I, Robot – “Inspired by”, which basically means “We couldn’t be bothered doing a proper adaptation, so we bastardised it so much that they wouldn’t let us use the ‘based on’ credit”.
And, so far, to my great disappointment, Bicentennial man remains the only movie based on an Asimov book.
And it’s so spot on that Isaac would have wept if he’d seen it.
One review I read mentioned that it’s “faithful to the ideals of golden-age sci-fi”, as if that was a bad thing and as if the story needed to be updated to be more contemporary – there are no explosions in Bicentennial Man – things don’t explode very often at all in Asimov’s books.
This is because Asimov wrote a different type of sci-fi from anything you’ve ever seen on screen – Asimov’s storys rarely have “bad guys”. And that’s what makes Asimov’s work so awesome.
It’s the very fact that this movie is faithful to the ideals of golden age sci-fi that makes it so goddamn awesome. That, and Robin Williams doing some actual acting.
This was also the movie that, for me, turned Robin Williams from “that guy who does all those stupid movies” into a serious actor. The scene where Robin Williams first appears sans robot costume, when he first sees himself after his “upgrade” and simply stares into the mirror and says “thank you” is a seriously brilliant and moving piece of cinema.
I’m also a fan of Sam Neill, and he’s also in Bicentennial man, so there’s that.
There are a couple of things which I thought were missing from the screen adaptation which I think would have made it a stronger film. For example, in the book, it’s not Andrew who starts the crusade for Robotic rights, it’s one of his human friends. This happens after Andrew is harassed by a couple of teenagers, who order him to strip off his clothes and threaten to take him apart – the three laws of robotics make Andrew helpless to protect himself against this assault, and I think it could have been a really powerful scene in the movie, if a little darker in tone and less kid-friendly than the rest of the film.
But on the whole, Bicentennial Man is a faithful adaptation of an excellent story by one of the masters of science fiction, and I’d give it at least 90%. It remains one of my favourite films to this day.
It holds on to the ideals of golden age sci-fi brilliantly, and that’s why asimov would have wept had he lived to see it – they would have been tears of joy at seeing his story adapted so faithfully and with such heart.
But, no explosions or tits, so a crappy rating. Humanity sucks.
Asimov’s Robots are better than us in every way. Maybe that’s part of the reason why this movie isn’t more popular – people don’t like to see their betters. Asimov’s robots, being more intelligent than man, are also more ethical – they help us because they want to. The epitome of this is Asimov’s “Robot Takeover” story – The Evitable Conflict. Go read it if you haven’t already – I’m not going to spoil it. It’s ironic that this story is turned into your usual everyday “evil robots take over” story in the film adaptation of I, Robot. But I’d rather not get started on that film, Maddox already did that.
On last week’s episode of King Of The Nerds (S03E04), one of the judges for annual “Nerd Song” competition is Moby.
Moby takes issue with some of the lyrical content of one of the songs, saying:
“I took issue with ‘Like newton’s laws of motion we don’t hypothesize’, because I feel like in a quantum world, most of newtonian physics has sort of been cast aside.
Groan.
Moby, you’re such a dick!
Now, I’m no string theorist – I don’t even know one of Newton’s equations from memory, but even I can tell you quite definitively that newtonian physics has not been “cast aside”.
OK, sure, so Quantum Mechanics does have some bearing on Newton’s work, but Newton’s laws are still valid in the vast majority of everyday circumstances. If you were to say that Newtonian physics has been refined, then you’d be spot on – Relativity and Quantum mechanics have both refined newtonian physics immensely, but that doesn’t mean that newtonian physics have been “cast aside” – not by a long shot – Newton’s equations are still very valid if you want a simple-to-calculate, approximate solution to many, many, many problems – they only become inadequate in certain circumstances, such as calculating the precession of Mercury’s perihelion, working with subatomic particles, or dealing with relativistic speeds and/or very curved regions of spacetime (big gravity wells).
The Apollo Missions, for example, didn’t need to use relativistic or quantum equations. If they had, the moon landings never would have happened – an astronaut can plug the numbers into newton’s equations and work them out with a slide-rule or maybe even in his head. If he had to do quantum mechanics or relativistic equations to figure out a descent or rendezevous burn, it would never have happened before the microprocessor was invented – we just didn’t have the computing power back in 1969. Missing the CSM by a couple of hundred metres on the way back up or slamming into the lunar surface because you’re busy trying to do quantum mechanics but struggle with the math would probably not be considered a particularly successful mission. The Saturn V rocket is the ultimate embodiment (so far) of Newton’s Third law of motion, and it sure seemed to work. I’d also note that 1969 was a good 40-or-so years after the establishment and general acceptance of Quantum Mechanics – it’s not like they didn’t know all about quantum theory and got lucky – they knew all about it, and they knew they could ignore it.
So, Moby, to summarize: I don’t think “Quantum Theory” means what you think it means.
Moby then goes on to criticise one of them for claiming in the song that he read Hamlet in the Original Klingon, asking “did you really read Hamlet in Klingon?”.
Now, In Moby’s Song Run On, he states:
Michael spoke and he sound so sweet
I thought I heard the shuffle of angels’ feet
He put one hand upon my head
Great God Almighty let me tell you what he said
Saying quite specifically that the Archangel Michael has personally spoken to (and physically touched) him. I kinda doubt this, what with the whole “fictional character” bit. But I suppose Moby might not actually be lying – he could simply be delusional. Incidentally, the same song also implies that he’s met jeebus, something I’m also doubtful of.
Setting aside how incredibly petty it is to criticise someone because what they say in a song isn’t literal truth (it’s called “metaphor”, “simile”, or “A direct reference to Star Trek VI”, look it up), I think that this is a somewhat hypocritical stance for Moby to take given the lyrics to just this one song (Note: this was the first moby song I thought of and looked up the lyrics for, I’m sure his whole body of work is rife with this kind of stuff, as is the work of just about every songwriter ever – I don’t think that Bonnie Tyler literally falls apart every now and then – that would be a strange medical condition, and I don’t actually want to hunt and torture stupid people, because I’m not actually a psychopath)
One of the members of the other team didn’t think so though – she thought it was cool to see moby dissing the other team for no real reason, and chimed in with something to the effect of “Um, I don’t even think Hamlet has been translated to Klingon – there’s not enough vocabulary for it!”
This immediately caught my attention, since being a Star Trek fan I know how mental some of us get, so my immediate reaction to that was “Yeah, I wouldn’t be so sure about that”, with visions of committees of nerds arguing over usenet as to what was an appropriate klingon word to use for “cutlass” (in fact, that’s probably an easy one which didn’t cause much debate – it’s a weapon, so there was probably already a Klingon word for it)…
…So, tonight, I do a search, and Lo and behold!
I was talking to a friend about this, and he put it elegantly:
“You’re suprised by Moby being a pretentious hipster douchebag? Didn’t you know that Moby invented ‘hipster douchebag’?”
Well, yeah, I did. But at least I thought he’d bother to be correct. Apparently not.
(BTW: I’m actually rooting for the other team which Moby didn’t criticise as much – specifically for Kaitlin, because she’s awesome, and I think that in the end Moby and the other judges did make the correct decision – the other song was better. But I do take issue with moby being such a dick, and I think that his criticisms were totally unfair)
As Usual, TISM turn out to be prophets – De Rigeurmortis – Track 10:
Lyrics:
Dear Moby,
Having read you liner notes, I now violently oppose pain, death, famine, disease, slaughter, war, youth suicide, pollution, hitting your finger with the hammer, parking in disabled car parks, the industrial military complex, the death of innocent third world people, especially the children, by the way, I’d like to thank Mohammed and the Dalai Lama, safari suits and stating the fucking obvious.
A paraphrased version of a funny conversation I had once via SMS:
Me: “OMFG I simply cannot grok the iphone interface, it’s completely awful on so many levels. If I was going to go into detail I’d need a proper keyboard to type up the relevant hundred-thousand word thesis – even this phone’s physical keyboard has its limitations.”
Smartass iphone user: “What is ‘grok’? If you had an iphone, autocorrect would have picked that up for you.”
Me: “Yeah? Well autocorrect would have been wrong – type ‘define grok’ into a search engine.”
Iphone user: “…Oh.”
Me: “lol, pwnd.”
from https://en.wikipedia.org/wiki/Top_Gear_controversies#Series_20:
Top Gear was accused of faking a scene in which riverbank diners have their meal interrupted by a deluge of water from a passing hovervan, which the three presenters had built to show what can be done to help flood prone areas. The accusations were started after Michael Bott said on his blog that he’d been hired by Top Gear to pose as one of the diners.
Just so we’re clear: The people complaining about this are complaining that it’s disingenuous for Top Gear to stage things like this.
So, what they’re saying is that Clarkson, Hammond, and May should have actually really driven the hovervan past a real riverside restaurant where real, unsususpecting members of the public were dining in peace, and sprayed them all with water.
I’m sure nobody would have complained about that.
Strangely enough, contemporary references in a written work will age with the work.
For example, Science fiction works which were “hard” when they were written will tend to “soften” over the years as science marches on. Go read Asimov’s work from the 50s – it’s based on a 1950s understanding of physics. Asimov doesn’t talk about string theory or dark energy. Because they hadn’t been discovered yet. Asimov’s work has a hyperdrive, which automatically tends to push you towards the softer end of the scale these days, but in the 1950s a hyperdrive wasn’t quite so implausible, so you could talk about hyperspace jumps and still be a fairly hard piece of sci-fi.
Similarly, if you read a work written in the late 1960s which makes many contemporary references, you’ll be reading about things which no longer exist – products which have since been discontinued or radically changed, companies that don’t exist any more, and people who have since died. You get a similar effect when a story is written for a particular audience or makes cultural assumptions – a book written for British readers will talk about pounds, while the American equivalent will talk about dollars.
I’m stating the obvious, right? Yup.
Enter “Bored Of The Rings”, a classic and brilliant parody of Lord Of the Rings, first published in 1969. It contains a bunch of contemporary references and talks about brands that no longer exist or are no longer popular, and a bunch of things which are American-centric, since it was written by Americans. But this in no way detracts from it’s awesomeness.
I was pretty close to the end of my first read-through when I realised what “Legolam” was, other than a misspelling of “Legolas”. It made me feel kinda stupid for not picking it up earlier. But at the same time, I felt kinda smart for figuring it out by myself (I was about 12, go easy). And the next time I read it, there were probably contextual jokes around the “Legolam” name which I didn’t get on the first read-through but did get on subsequent reads. It wasn’t until a reading during the internet age that I was able to find out what “Serutan” was. Another example from a different media: I got about 40% through my second viewing of the TV series “Veep” before I realised that “potus” wasn’t just a weird name or a nickname.
Figuring these little jokes and references out for myself is half the fun of it. This is what makes movies like Spaceballs such genius. It’s what’s awesome about Futurama. Any person who is able to watch Spaceballs through for the first time and list every single reference or parody has no life, and hasn’t enjoyed the movie at all because they were in ‘analysis’ mode – they probably couldn’t tell you what spaceballs was about because they were too busy making notes. This is why spaceballs is infinitely rewatchable – I will never know whether I have every single reference and in-joke. You’d be suprised how often I find new ones in this single example. My ability to find them and laugh at them expands as my knowledge expands – you won’t get the planet of the apes references unless you’ve seen planet of the apes. This is part of the joy of the film.
And Spaceballs isn’t the only example, it’s just one of many. It’s one of the roads to comedic genius – pack it tightly with references and in-jokes. Bored of the Rings is another great example.
But with bored of the rings, if you were born…say…after 1980, and especially if you’re also not American, you might struggle – there are lots of anachronistic or obscure references in that book.
So, helpfully, somebody has decided to update the book. I don’t know whether it’s only in the audiobook and therefore audible who are at fault or whether it was the genius idea of some editor while doing a revised edition, but it almost completely ruins the book.
What I’m talking about is this – the narrator of the audiobook will be reading along, and get to a reference, and then say “NOTE” and explain it for you, because apparently you’re such a fucking idiot that you’re completely incapable of using either google or wikipedia to look up things you don’t get.
So the audiobook goes like this:
“Spam Gangree, who was presently celebrating his suspended sentence for
the performing of an unnatural act with an underage female dragon of the opposite
sex. NOTE: ‘spam’ is a tinned ham product, and ‘gangree’ is a play on words for ‘gangreene’, a disease spam gives you.”
Oh, ha ha – the explanations are trying to be funny, too. Because spam gives you gangreene, you see.
One thing that really gets me about these explanations is that they’re very inconsistent – for example, I don’t think that “spam” requires an explanation – is there anyone who doesn’t know what it is? But these new added notes strangely omit explanations for the name “Dildo Bugger”. So I guess I’ll never find out what that one means.
The book has many saving graces – it’s still damn funny, even if you don’t understand any of the references – I understood few of them when I first read it. You don’t need these explanations for it to be funny, and in fact having the explanations sucks all the humour out of the joke, and destroys the re-readability of the book – if you already get all the jokes, there’s less in it for you to re-read it.
But at least there’s nobody out there confused about what spam is. That would be terrible.
If you want to read a great parody, go pick up a vopy of Bored Of the Rings. If you like Tolkien and have a sense of humour then you’ll be hooked by the time you get to the prologue. It’s far far better than both “The Soddit” and “The Sillymarillion”, books written decades later to cash-in on Peter Jackson.
For the record, wher I imply that I’m listening to an Audible Audio Book, I’m actually listening to a pirated copy in mp3 format, since Audible refuse to sell me a copy of the audiobook without DRM. I tried to give them money but they weren’t interested. Don’t buy things from Audible.
Excerpt from the prologue:
Don’t fret precious, I’m here
Step away from the window
Go back to sleep
Lay your head down child
I won’t let the boogeyman come
Counting bodies like sheep
To the rhythm of the war drums
Pay no mind to the rabble
Pay no mind to the rabble
Head down, go to sleep
To the rhythm of the war drums
Pay no mind what other voices say
They don’t care about you
Like I do
Safe from pain and truth and choice and other poison devils
See, they don’t give a fuck about you
Like I do
Just stay with me
Safe and ignorant
Go back to sleep
Go back to sleep
Lay your head down child
I won’t let the boogeyman come
Count the bodies like sheep
To the rhythm of the war drums
Pay no mind to the rabble
Pay no mind to the rabble
Head down, go to sleep
To the rhythm of the war drums
I’ll be the one to protect you from
Your enemies and all your demons
I’ll be the one to protect you from
A will to survive and a voice of reason
I’ll be the one to protect you from
Your enemies and your choices son
They’re one and the same I must isolate you
Isolate and save you from yourself
Swinging to the rhythm of the new world order and
Counting bodies like sheep
To the rhythm of the war drums
The boogeymen are coming
The boogeymen are coming
Keep your head down go to sleep
To the rhythm of the war drums
Stay with me
Safe and ignorant
Just stay with me
Hold you and protect you from the other ones
The evil ones
Don’t love you son
Go back to sleep
Sometimes, people do things to restore mine a little bit…
…I really, really like it when that happens.
When it first came out, I wasn’t a big fan of Back To The Future III.
It’s one of – if not the first thing I ever saw at the cinema. I was 9. I had seen the first two on video and loved them.
When I say “at the cinema”, I’m not being precise. “At the theater” might be more appropriate. It was actually a projector set up at the local community centre in the small country town I lived in. Usually, it was for shows or exhibitions – playing movies was a new thing.
As a kid, I was dissapointed that it was set almost entirely in the old west, and that there wasn’t any futuristic stuff or even any time travelling – the only time travel is from 1955 to 1885, and then the rest of the movie is spent trying to get back to 1985. I was also really disappointed at the destruction of the delorean.
But now, I think it’s a marvellous conclusion to the trilogy.
Yes, it’s a change of pace from parts 1 and 2, which are full of adventure and chases while doc and marty labour to fix the timeline and not destroy the universe in the process. Part 3 consists of the effort to get the time machine working in 1885 – it doesn’t have the same sense of adventure.
Instead, it provides a catharsis and it serves to analyse and evolve the two central characters – doc in his meeting clara, and marty in overcoming his problem with being called chicken. I think that as a kid I didn’t appreciate this, but now, I see it’s the perfect direction to take. Part 3 is where all the poingiant character moments take place, and it has some great ones – Marty choosing not to race needles, seeing Doc’s family. It also has lots of clever little jokes and references. Perhaps my favourite piece of dialogue is when marty says “great scott!”, and doc replies “I know, this is heavy” – it always makes me chuckle.
Parts 2 and 3 also serve as an excellent example of turning a story into the first part of a trilogy – the second part expands on the adventure of the first and sets up some plot points for the third, and the third provides character arcs and a satisfying, final conclusion – at much as I’d love to see Doc and Marty have one more adventure, the story is over. It even goes so far as to proclaim “The End”. There should never be a Back to the future 4.
Further, it expands the mythology of the entire series by showing the history of hill valley and its inhabitants – you get to see the first mcfly born in america, where the stricklan family’s love for discipline comes from, and another tannen. There are also more subtle indicators – the manure cart Mad Dog Tannen is punched into is “A Jones” manure, where the manure truck in 1955 is labelled with “D Jones”.
This brings me to another point about the magnificence of the storytelling in the back to the future trilogy as a whole – attention to detail. It seems to me that screenwriters and directors aren’t paying nearly as much attention to detail these days. For instance, the first scene of part 1 – doc’s lab – contains many subtle foreshadowings, such as the plutonium case / news report, and the article talking about the Brown Mansion, which you’ll see later in the film, burning down and Doc having to sell the family estate. These are tiny subtle details which you might not have noticed when you watched. (Mr Plinkett voice) But your brain did. It serves to make the fictional world more realistic and “full”.
Another part of this is consistency. I was watching part 3 and noticed when they start pushing the delorean along the train tracks that they have a wooden brace filled with tyres to dampen the impact. I thought I had spotted a continuity problem, and I said to myself “It’s 1885! where did they get tyres from?!?”. Then I remembered that they had removed the tyres from the delorean so it could run on train tracks. And on inspection, indeed, there were four tyres, and they were 1955-style whitewall tyres – exactly like the delorean had after its 1955 repairs.
Sometimes I wonder if it’s that filmmakers these days are paying less attention, or that I’m more cynical in my old age. I’m sure it’s a bit of both, but I don’t think there’s really very much cynicism there – there have been some truly great movies produced recently. Cloud Atlas springs immediately to mind – this instantly became one of my all-time favourite movies. So I’m not totally cynical.
I could offer many theories to explain why we don’t seem to be getting the same level of attention to detail any more.
Perhaps it’s that more and more things are done digitally, so the director / screenwriter isn’t dealing with real-world objects and locations anymore, so they’re not able to spot these small details early enough – a director on location dealing with props is perhaps more likely to spot these issues, and it’s definitely easier to add that one line of explanatory dialogue when you’re filming the scene, as opposed to fixing it in post with pickups or ADR, both of which require much more in both time and resources.
Maybe it’s the “George Lucas Effect” – it does seem to be that the bigger names are the ones pushing out duds. Given James Cameron’s record, avatar was sub-par. So was Indy 4. And don’t get me started on prometheus. Maybe it’s that these big names are surrounding themselves with “yes men” who are afraid to point out these inconsistensies. Perhaps it’s the hollywood process – appealing to the lowest common denominator – perhaps even these big names are being subjected to executive or studio meddling.
Perhaps the problem is the properties themselves – it’s always the great franchises that are sequeled into horribleness. Perhaps the problem is that Alien got too big. When that happened, the budget increased. But because of the increased budget the studio wants to sell more tickets. So this classic series which everybody knows and loves, which we’re sequelling because we know it has a huge established fanbase, needs more “mainstream appeal”
There are exceptions – great films still get made – look at primer – those guys paid attention. But I wonder if there’s anything that has been made in the last decade which I will look at with the same fondness in 20 years as I now look at something like BTTF, Spaceballs, or Terminator. There surely will be, but i suspect that the 2000s won’t live up to the 80s and 90s. And Back to the Future is surely a pinnacle of 80s filmmaking.
(Reposted on slashdot here)
I’ve had the idea in my head for years, but tonight I finally put together a mashup, called “Epic Session”:
All due credit/copyrights/trademarks belong to Faith No More and Linkin Park, fair use nonprofit whatever blah blah.
I’ve been saying it for a long time now.
Spaceballs is the greatest movie ever made.
Yes, Really.
There are over 50,000 reasons why – there must be at least one reason per frame. One day I think physicists will discover that if one charts every single reference to other works alongside all the little pauses and glances and things that may or may not be mistakes in spaceballs in a particular way in a twenty-six-dimensional space, it spells out the ultimate answer to life, the universe and everything.
Here are just a couple of examples (I’ll edit this list as I think of more):
* When Dark Helmet discovers that the radar has been jammed, and is saying “there’s only one man who would dare give me the raspberry”, keep your eyes on Colonel Sandurz – He’s been involved in the scene until now, interacting with and watching helmet, and as the camera approaches for a close-up on Helmet as he says “LONE STAR!”, Sandurz looks at the camera, raises his eyebrow, and steps back – his body language says “Oh, you’re coming in for a close-up? Let me get out of your way…” Gold.
* “Nice Dissolve”
Hail Skroob!
I recently saw Predestination, a new Australian Sci-fi based on a short story by Heinlein.
It’s awesome – it’s the best time-travel movie in a good while. I watched it, and was then immediately compelled to watch it again – my brain wouldn’t stop, I needed to make sure that everything fit into place and that I hadn’t missed any obvious brokenness in my enthusiasm. And it was just as good on the second viewing – there are no glaring inconsistencies that I can see, and on the second viewing you pick up a lot of subtle stuff.
It started strong, and then got better. I was particularly impressed with the way it kept me thinking and guessing, and then thinking more and second-guessing my guesses – I found it constantly teasing my expectations of a time-travel movie called “predestination”, it’s like the filmmakers are daring you to name the tropes you think they’re going to use, so that they can avoid them or mess with your expectations of them.
In addition to being a fantastic science fiction film (and IMHO good, serious time-travel films are few and far between, so this is worthy of praise in its own right), I also found it to be a really compelling character drama with a lot of heart.
One other thing which I think deserves particular mention: I love that it’s not set in our universe. It’s set in the past on some alternate earth as envisioned by Heinlein in 1959. This is awesome, and really unusual – usually these types of golden-age story are contemporised – a terrible, terrible example of this being I, Robot. Eeew. It feels like they have constructed a world, even though it’s mostly the same as ours, and the differences are taken for granted in-world – e.g no heavy exposition on exactly what “space corp” does – tourism? mining? exploration? who knows, it’s not relevant. Awesome.
I think it’s probably the best time-travel film since 12 Monkeys. It’s not quite as good as 12 Monkeys, but then 12 Monkeys has Terry Gilliam’s style and amazing performances from both Bruce Willis and Brad Pitt – we’re talking big-league stuff here. And I’d put predestionation in the same league.
I’d love to hear suggestions for other great time-travel films for comparison. Here’s my “time travel movie showdown” table:
| Predestination vs: | Winrar |
|---|---|
| 12 Monkeys | 12 Monkeys |
| The Butterfly effect | Predestination (by a slim margin) |
| Primer | Predestination (Again, by a slim margin) |
| Looper | Predestination |
| Donnie Darko | Predestination (darko disqualified for being too ambiguous about whether it’s a time-travel movie or not) |
| The Time Machine (either version) | Predestination |
| Back To The Future | Tie (contenders refused to compete) |
I have fortune integrated into various scripts. Because I can.
Today, logwatch gave me one that made me chuckle:
THE LESSER-KNOWN PROGRAMMING LANGUAGES #12: LITHP
This otherwise unremarkable language is distinguished by the absence of
an “S” in its character set; users must substitute “TH”. LITHP is said
to be useful in protheththing lithtth.
In this latest entry in my series of helpful ‘how to’ articles, I’ll be teaching you how to power on your computer.
If you have a PC, follow these steps:
1. Ensure that the machine is plugged in
2. Ensure that the rear power switch is in the ‘on’ position
3. Press the ‘Power’ button on the front of the device.
If you have a mac, these are the steps you’ll need to follow:
1. Ensure that the machine is plugged in
2. Examine the machine, noting that there’s no power switch anywhere to be seen.
3. Unplug all cables from the machine
4. Pick up the machine and examine it from every angle, looking for the power switch. You’ll note that it’s in a location which is completely nonfunctional and unintuitive. But at least it doesn’t interfere with the nice brushed metal finish.
5. grab a permanent marker and put a mark on the front of the machine (preferably on the lovely brushed metal) where the power switch is, so that it’s possible to turn it on again without repeating this entire process.
6. Put machine back on desk
7. Plug all cables back in
8. Reach around and behind the monitor, through all the cables you just plugged in, and press the power switch
9. Kill yourself.
May all our young Aussie swimmers
Be resigned to failure
May our nation’s state
Be always second rate!
May Timorese fisherman
Evade the Aussie sailor
Do as history teaches
Die on Middle Eastern beaches!
We produce a Norman May
Not a Norman Mailer
May our land’s vast distance
Always treat us with indifference!
Give up for Australia!
Give up for Australia!
Give up for Australia!
Give up for Australia!
-TISM
The problems with Microsoft certification are myriad.
One really big problem is that people with Microsoft certification think that because they know how to use the Wizard provided by Exchange server, they know something about email, the internet, or networking.
Microsoft certification teaches you the practical knowledge you’ll need to run a variety of servers – on Microsoft tech. You’ll be able to do cool things fast – as long as Microsoft anticipated that need. And you’re basically taught a mantra that says that if it doesn’t have a Microsoft logo, it’s “Not Compatible”.
In reality, the opposite is true: Pretty much everything is compatible, except for Microsoft. And usually everything is compatible with Microsoft, despite their best efforts to embrace and extend. The only thing is not compatible is that Microsoft products aren’t compatible with non-microsoft products.
But I think perhaps the biggest problem with Microsoft certification is that when people finish their course, they get a shiny certificate, and it says that they’re Microsoft certified. And Microsoft people spend lots of time impressing how respectable they are on their customers. So people get this impression that their Microsoft certification means that they deserve some kind of respect.
“It’s better to push something when it’s slipping than to risk being dragged down”
- Marilyn Manson, Into The fire
Dear Firefox devs,
I’ve been using your browser for 10 years or so now – ever since I started to learn about open source software. The difference from IE was amazing – tabs!
Later, the difference became even more profound – Adblock! Firebug! and too many other add-ons to mention – eventually it got to the point where I had to limit the addons I use in order to not clutter and slow things down. Firefox really was the browser for power users.
I had my complaints – the CPU usage always seemed too high, and the memory usage was particularly absurd, but it did everything well.
Chrome happened. It closed the gap somewhat with its built-in developer tools and extensions. The one-process-per-tab idea was a good one. It was fast, and it didn’t require a gigabyte of memory to display one tab, but it just didn’t have the flexibility of firefox, so I could never quite make the switch.
There was one other thing about chrome I didn’t like – it had that sleek, minimalistic, “modern” interface. You know the type: they have pretty curved edges and nice animations for everything, but they tend to not be very configurable.
So it was with sadness that I updated my system the other day, only to see a shiny, chrome-lookalike interface on firefox.
I spent ages trying to turn the add-on bar back on and to remove the button which shows the awful new menu, to no avail.
Eventually I found the classic theme restorer add-on, which makes things sane again, but it’s not exactly awesome: Firefox is now using even more memory and I have yet another add-on installed just so that the interface isn’t terrible.
It seems that firefox is going for a new target demographic: they’ve decided to abandon the power users and go after the crowd who like chrome but think that it’s just too fast and doesn’t use enough memory.
Maybe they could use a new slogan: “Firefox: it’s just like chrome, only slower!”.
Personally, I think that this new demographic might be a limited market. If I wanted to use chrome, I’d…uh… use chrome.
Meanwhile, I wonder what the Opera team have been up to gor the last 5 years…
Babe those sexy curves drive me wild
I wanna mount you, ride you, as hard as I can
I’ll ride you like a pony, babe
I love the way you move between my legs
and the way you squirm when I squeeze
and the way you grip when you get warmed up
Babe you sure know how to please
And I wanna take you everywhere I go
and I wanna show you to everyone I know
Show you off like some trophy wife
you and me babe, this is the life
Glide with me, my baby
Fly with me, my baby
Ride with me, my baby
Be one with me, my love.
It seems like this has just begun
but I know I’ve already won
The two of us have endless fun
moving together in unison
And when I’m with you I get nothing but action
One flick of my finger and you’re having contractions
I feel your vibrations all the way to my feet
When we’re together, babe, you make me complete
Babe you know you’re the only one
I wanna mount you, ride you, as fast as I can
I’ll ride you like a pony baby
And the way you purr when your motor’s running
and the way you scream when you get revved up
and the way you react to my every move
and the way you never come unstuck
make me wanna shout your name from the rooftops
make me wanna sing your praises till the message groks
makes me insecure when I’m not with you
makes me care about nothing, except us two
Glide with me, my baby
Fly with me, my baby
Ride with me, my baby
Be one with me, my love.
Since sysadmins in china don’t respond to abuse reports the whole country just got blocked. Good luck in your future hacking attempts.
The surest way to corrupt a youth is to instruct him to hold in higher esteem those who think alike than those who think differently.
- Nietzsche
Sometime in the past 48 hours I hit 5 million SETI credits:
(Link defunct. Stupid allprojectstats, pointed to http://allprojectstats.com/s2652978m15a.png)
That means there’s a 99.59099% chance that I’ve used more CPU time to look for aliens than you.

NEWSFLASH:
Top Gear is not a serious programme, it’s a comedy programme. It’s not real.
When Jeremy Clarkson says “literally” on Top Gear, he doesn’t literally mean “literally”, he means “figuratively”. This is what’s known as a comedic device – those who are in on the joke of Top Gear realise that he knows that when he says “literally” he means “figuratively”, and that he knows that they know. It’s part of the joke.
Asking Jeremy Clarkson “is it real?” is more disingenuous than him responding that it is, in fact, literally 100% real.
Oh, yeah, and the preceding blog post may have contained spoilers, so spoiler alert.
I just emailled this to some guy who was asking about the freerunner on the openmoko lists, where I still lurk. I was proofreading it and thought to myself “hey, this is actually a pretty decent review of the device”. So here it is for all to see:
The freerunner is the worst phone ever made. It might nearly be usable as a phone now thanks to Radek and QTMoko, but you’re much better off buying an old feature phone or rooting an android phone. I think that while it might nearly be acceptable for a linux hacker, the freerunner software will never be a truly good user experience despite radek’s efforts – it’s too big a job for one person. I hope I’m wrong about that, but I don’t think I will be.
I was particularly appalled at the battery life. The battery used to last about 2 hours, but they have nearly solved all the power management bugs so if you’re lucky you might get ~6 hours out of it these days. It might even last all day if you keep it in suspend and don’t use it. In particular, using Wifi, Bluetooth, GPS, or having the screen on will significantly reduce the battery life you should expect to get.
It doesn’t have a camera, though I believe there’s a camera module for the GTA04.
An important thing to note is that due to a design flaw, the device is not capable of fully utilizing it’s accelerated graphics as bandwidth to the screen is limited. therefors it’s not capable of playing fullscreen video at the native resolution of 480×640. It will play fullscreen video if you’re into extremely crap resolution – 240×320. You shouldn’t ever expect to see much more than 10-15fps at full resolution.
The company went out of business because they made a buggy phone and couldn’t figure out what they wanted to do software-wise – they seemed to think that making the UI themeable was more important than being able to recieve phone calls or have working power management. The demise of Openmoko is a good thing.
If you’re looking for a phone, you do not want a freerunner.
If you’re looking for a hackable linux palmtop with a tiny screen, no keyboard, not very much power and a fairly awful battery life when you’re using it as a computer, then the freerunner might be an option for you, although you can probably buy something like a raspberry pi with 3 times the power for half as much money.
Nikolaus’ GTA04 project does seem much more promising and addresses a lot of the shortcomings of the freerunner and may be worth looking into. I have spoken to Nikolaus via email a few times and he seems like a very cool guy – I trust him and I’d buy a GTA04 in a heartbeat if I wasn’t put off by the price – I already spent $400 on a phone that doesn’t work, and I bought a nokia so that I’d have a working phone before Nick brought out the GTA04, so I can’t justify spending that much money to make my freerunner useful.
Aah. how I love my Model M. I’ve written about it before. The click-click every time I press a key. It feels like I’m accomplishing something. I do this wierd hybrid two-finger/semi-touch typing technique from which I can’t seem to break the habit, but touch-typing is easier on the Model M for me – the keys have sharper edges and are therefore more distinct to the touch – my fingers just seem to fall into place. The other thing I love about my particular Model M is that it’s extra-awesome: it has a manufacture date in 1992 stamped on the back, and a real proper motherfucking IBM logo on the front – none of this modern USB stuff. It’s a real proper original IBM Model M, though 1992 is getting kinda late for original – it’s “only” 21 years old.
The Model M really is an example of engineering at it’s best: In this way it has something in common with Commodore hardware – they’re from the same era, and every commodore machine I have which wasn’t spare parts when I got it still works. Some of the ones I got as spare parts aren’t spare parts anymore – they’ve been turned back into working machines. My Amiga 2000 is one of my most treasured posessions. I hardly ever use it. But when I turn it on, it just works… For twenty years! It’ll still be going long after this Dual Core 3ghz lintel box I’m using now is dead. This stuff is designed to last, no planned obsolescence here! Can you imagine the testing these things went through? Automated machines pressing those buckling springs over and over again to find their point of failure. I don’t even know what it is but I’d bet they’re rated for millions of keystrokes. Per key. This is not a flimsy piece of junk which falls off your lap and breaks, though it could maybe break your toe if it lands on it. Old cars are like this too – they’re designed to last a lifetime. Barring violent destruction at the hands of nefarious third parties my Model M is the last keyboard I’ll ever need.
I’ve hardly used it in 2 years. It was plugged into a server went pop a few months ago which I haven’t bothered to resurrect. The server used to be my primary machine before I got my current primary machine. It has it’s own new-fangled USB wireless non-Model-M keyboard with permanent ink blotting out the awful logo on the ‘super’ key. I use this new machine for games since it has a nice nvidia card and I’ve found that the Model M isn’t the ideal gamers keyboard for action games – the only shortcoming I’ve discovered – those ultra-tough keys aren’t designed for being pressed in rapid succession. Or, perhaps more accurately, my fingers lack the dexterity to press the same clicky-style key quickly enough. So I’d never bothered to plug in the good old Model M, even after the old server died.
Enter spilt milk leading to a sticking tab key. Uber annoying im vim. The story should be pretty obvious from here – no more fear of spilt milk, certainly no crying over it…
…except for one detail: now I have a good, PS2, Model-M keyboard with it’s awesome 2-3 metre cable and it’s clicky keys and weight (it really feels like a piece of furniture sitting on your lap!), AND a mere wireless USB keyboard with noobish easy-to-press keys that are nice for gaming. Awesome. ![]()
You don’t need to quote database column and table names in queries unless they contain special characters like spaces.
This applies for every database engine and every dialect of SQL I’ve ever used – quoting column names is always optional.
So why the fuck do you insist on writing this in your php codez?
$query=”SELECT \”some_ordinary_column\” from \”some_table\” where \”some_table\”.\”some_column\” = \”some_value\”"
Are you a masochist who loves escaping things or what?
How much more readable is this:
$query=’SELECT some_ordinary_column from some_table where some_table.some_column = “some_value”‘
The funny thing is that the type of people who write this garbage are the same type of people who tell you that using an if statement without braces is “bad style”. lol.
Natalie Bennett, A victorian police officer, admits (in private, off the record of course) that she routinely speeds because she knows that if pulled over all she has to do is flash her badge and she’ll be let off scott-free.
This makes her a despicable human being and part of the problem.
When I expressed my outrage at this wanton abuse and double-standard, I was told “if you have a problem with it you should become a cop so that you can speed too”.
I was particularly astounded at the complete lack of interest in justice which this view implies – it seems that some people don’t want a better world. It’s not just that they’re apathetic and terrified, they’re actively disinterested in the world being a better place.
It’s times like these when I think that I shouldn’t bother trying – this idiotic species doesn’t deserve my help – let it die. It might not be my ideal “better world”, but it would be an improvement.
Space: the final frontier. These are the voyages of the starship Enterprise. Its five-year mission: to explore strange new worlds where things explode, to seek out new life and new civilizations, and watch while they explode. to boldly go where no man has gone before, and blow shit up.
“If I speak at one constant volume, at one constant pitch, at one constant rhythm, right into your ear, you still won’t hear.”
- Faith No More – A Small Victory
(Dumb bitch parks illegally across my carpark exit)
Me: “You know that’s not a parking spot, right?”
Her: “Huh?”
Me: “That spot you’re parked in – it’s not a parking space, it’s the entrance to my carpark.”
Her: “What?”
Me: “I SAID THAT IS NOT A PARKING SPACE! MOVE YOUR SHITHEAP!”
Her: “There’s no need to scream!”
Unless you’re me, you’re less awesome than you think you are.
(I’m more awesome than I think I am. This is not a paradox)
Therefore, when you write a mission-critical piece of code, you need a logging system
Your logging system needs to have different types or log message: error and debug at the bare minimum.
Your code needs to log every action it takes.
This might be expensive or difficult. Tough shit. If it’s important, it needs to be logged – you must be able to go back over a particular execution and determine what happened. This is not optional.
This is a good rule even for not-important code. It makes debugging SO much easier. There are approximately 100 billion logging systems available, use a library if you must. Or you could write your own in 10 minutes.
Let’s discuss! Give me an example of a situation where logging is undesirable for important code, and I’ll tell you why you’re wrong… ![]()
Don’t forget to breathe:
Following these steps will provide you with a continuous oxygen supply unless you seal yourself away from the atmosphere (i.e: sealed room, underwater) or leave the planet.
Leaving the planet without an adequate oxygen supply is not recommended.
“I don’t want to talk about time travel shit. Because if we talk about time travel shit then we’re gonna be here all day, drawing diagrams with straws.”
- Bruce Willis, Looper
No, things aren’t moving backwards at all!
Let’s look at some of the awesome new features of a couple of current-gen Microsoft products:
Windows 7: One of my FAVOURITE features is the way it assumes that I, as a user, am too stupid to know how to resize a window: apparently, if I want to move a window mostly off the right-hand side of the screen, what I actually want to do is resize that window so that it takes up half the screen! Apparently I’m too fucking retarded to know that I can achieve the same result by simply moving my mouse to the top-left or bottom-left corner of the window and just resizing it. Of course I’m not sure how it thinks I intended to resize the window, given that the resizing corners at the right are off-screen.
Similarly, if I want to move a window to the top of the screen, that means I want to maximize! Apparently, I’m too fucking retarded to know to just press the maximize button like people have been doing for about 20 years. Apparently, after moving my small scite window to the top of the screen, I planned to use the resize corners to resize it so that it filled the whole screen, rather than just pressing maximize. It’s really great that I have this software to do my thinking for me: I’d been struggling with that whole ‘maximize’ notion for years.
So we’ve established that Microsoft thinks my intelligence lies somewhere between that of Mac user and an inanimate carbon rod.
However, when I want to access the New-And-Improved(TM) ribbon interface and add a button to it programatically via VBA – you know, so that my (retarded) users just get a new button they can click to make things happen, I find that:
(from A Blog Post):
You cannot create ribbon elements dynamically in VBA It is not possible to create ribbon elements dynamically via code as with Office 2003, where you could manage your own CommandBars and CommandBarButtons. In Excel 2007 each ribbon element (Tab, Group, Buttons, etc.) needs to be defined statically and embedded in the Excel document using a specially crafted XML file and with quite a few manual steps, including renaming and modifying contents of the Excel document — factually a ZIP with the XLSM or XLAM extension.
And:
(from This Book):
In previous versions of Excel, it was relatively easy for end users to change the user interface. They could create custom toolbars that contained frequently used commands, and they could even remove menu items that they never used. Users could display any number of toolbars and move them wherever they liked. Those days are over. The Quick Access Toolbar (QAT) is the only user-customizable UI element in Excel 2007. It's very easy for a user to add a command to the QAT, so the command is available no matter which ribbon tab is active. The QAT can't be moved, but Microsoft does allow users to determine whether the QAT is displayed above or below the ribbon. The QAT is not part of the object model, so there is nothing you can do with it using VBA.
So, to boil it all down, there’s no way for me to programatically add a new toolbar button using this wonderful new interface, which means that my users (who, as previously established, are assumed to be about as clever as sponges) are expected to add a toolbar button themselves by following a set of instructions which I have to put together for them. Never mind the fact that this will inherently create a bunch of issues just in terms of support (e.g: morons calling me up asking what I mean by ‘right-click’ in step 6; users choosing a different icon, or giving the new button a different caption, ruining the uniformity of the interface), how I’m supposed to convey a concept as complex as ‘add a toolbar’ to a retarded grasshopper is strangely ommitted from the documentation I’ve looked through.
No, things aren’t moving backwards at all…
Watch out for the next installment of this series, where we’ll analyse why it’s a good thing to remove features from your program so that the interface isn’t cluttered anymore, because having a complex interface is a terrible, terrible thing, and menus are so unintuitive.
I hear that next year Microsoft is going to help the people at NASA Mission control replace their hideously complex systems (sometimes people have to TYPE THINGS at mission control!) with a (touchscreen) button (with round corners, of course!) that says “Launch Rocket” (in the tooltip, which you can’t see, because it’s a touchscreen – The icon will simply be a cartoony V2 rocket). It’s expected that this will lead to huge efficiency gains in the rocket launching process, and will probably only cause a 20-30% increase in catastrophes.
I have a VPN.
I have it set up in a pretty standard way: when a machine joins the VPN it effectively becomes part of my LAN. But I don’t route everything via the VPN, that would be inefficient and would waste my bandwidth. I haven’t bothered with doing DNS over VPN, as I usually just use IP addresses anyway (one of the advantages of using a 10.x.x.x network), and when you do that you run into all kinds of complexities and problems (like how to resolve names on the lan you’re connected to)
But sometimes I’m somewhere where I don’t trust the owner of the network that I’m connected to: I don’t want to be spied on.
In these instances, it’s handy to be able to route everything out over the VPN connection.
But if you don’t stop to think for a minute and just try to add a default route which points to the VPN server, you’ll instantly lose your VPN connection and all internet access because there’s no longer any way to reach the VPN you’re trying to route through. Doh.
The solution is simple:
#!/bin/bash #delete existing default route: sudo route del default #traffic to the VPN server goes out via your existing connection: sudo route add <internet-ip.of.vpn.server> gw <your.existing.untrusted.gateway> #...and everything else gets routed out via the VPN (assuming your VPN server is 172.16.0.1) sudo route add default netmask 0.0.0.0 gw 172.16.0.1
OK, that takes care of routing. Next you need to send your DNS requests out via the VPN, or you’ll still be pretty easily monitorable – overlords will still know every domain you visit. To do that, edit /etc/resolv.conf and change the ‘nameserver’ line to point to the nameserver for your VPN and/or LAN:
#/etc/resolv.conf nameserver 172.16.0.1
I recommend running your VPN on port 443. My reason is really simple: in oppressive environments, you can pretty much count on port 443 being open, since it’s used for https, and https is not something that a tyrannical sysadmin/policymaker can get away with blocking: it’s the backbone of e-commerce. In addition, https traffic is encrypted, as is VPN, so it’s less likely to be monitored by things like deep packet inspection, and any not-too-deep packet inspection is likely to come up with an outcome of ‘encrypted traffic, nothing unusual’ when looking at VPN traffic on port 443.
It should be noted that while this is unlikely to set off automated alarm bells, it will look somewhat unusual to any human observer who notices – your overlords will see a bunch of “https” traffic, but nothing else (not even DNS), which may in itself raise suspicions.
It should also be noted that you very likely just added a couple of hundred milliseconds to your latency and have now effectively limited your available bandwidth somewhat, depending on network conditions.
But I know from experience that the victorian government’s IT agency, Cenitex, is incapable of determining any difference between https traffic and VPN traffic going via port 443.
Though, of course, that doesn’t mean it’s impossible…
…In fact, that doesn’t even mean it’s difficult…
…but you should be reasonably safe from the spying eyes of your microsoft cerfitied sysadmin. ![]()
Nice:
Nobody should give valve money until they start complying with the Australian Consumer Protection Laws.
It would appear that Avant Window Navigator is dead:
Stable release 0.4.0 / April 11, 2010; 2 years ago
Which is a pity: I liked AWN. But the fact that its task manager doesn’t work properly has become a deal-breaker: after days of trying, I’ve finally given up at attempting to make AWN’s task manager realise that I have Eclipse running.
I have an eclipse launcher set up in awn. While Eclipse’s splash screen is showing, AWN recognises that eclipse is running, but as soon as the main window opens, awn does it’s “window closed” animation and refuses to acknowledge that the window which currently has focus deserves any kind of icon in the task manager.
If it came up with a duplicate icon – one in the taskbar in addition to the launcher – that’d be acceptable. But it doesn’t do that. Instead, it makes it impossible to switch to a minimised eclipse without using ALT-TAB, or the xfce-panel on my 2nd monitor (which isn’t always on). Clicking on the launcher launches a 2nd copy of eclipse, which then (rightfully) whinges that the eclipse workspace is in use and can’t be opened.
I found a couple of people who had similar issues. I tried a bunch of things to work around it.
On one forum, somebody explained that it’s hard to match windows to running processes…which is fair enough…
…except that the xfce panel seems to manage it just fine.
…and so does gnome panel
…and so does cairo-dock
…and, presumably, whatever KDE uses
…and, I expect, docky
…and, more than likely, dockbarx
And the awn devs would appear to have all been hit by a bus: domains have expired and are redirecting to spam sites; IRC is dead, and I’m yet to find any remnant of the awn community. Which is a real pity.
So I’ve installed cairo-dock. It looks nice, and somehow feels ‘more snappy’ than awn: maybe this is because cairo-dock’s ratio of plugins written in python is low: most of them would seem to be C++, with only a couple of the prepackaged ones being python. My only complaints about cairo-dock are:
This very likely means that in the near future I’ll be extending NodeUtil to have a cairo-dock applet, since this is the only thing I really miss from awn.
Today marks 10 years since I met you.
And on February 14th (Yeah, valentine’s day) – It will be 10 years since we first got together.
I still remember it so vividly.
It was a sunday afternoon. I was running late, as usual, to meet my friends at the St. Kilda festival.
So I got my shit together, and maybe 15 minutes late I turned up at the meeting spot. I was the last to arrive – everybody else was still there.
And somebody new.
I don’t know exactly what it was, but there was something about you that I saw straight away. I knew instantly that no amount of shyness on my part was going to stop me from talking to you. I knew that I wanted to get to know you instantly.
I knew all this so quickly that my mind went racing even before I figured out who you were. In the space of a couple of seconds, a huge number of thoughts flew through my mind. My thought processes went something like this:
1) “Oh. My. God: She’s fucking *gorgeous*!”
2) “Who is she, anyway?”
3) “Oh, I know who she is. This could be trouble.”
The “This could be trouble” was because you were my best friend’s sister, and I knew that I was going to be compelled to chase you. I didn’t want it to cause problems with my friendship. Of course, it did. But that’s another story.
I guess the point of this story is that since then I’ve pretty much believed in love at first sight.
Not literally, that would be stupid – I didn’t fall in love with you then and there. I don’t know exactly when I did fall in love with you – it snuck up on me: one day I realised that I’d do anything for you, and there it was.
But this wasn’t just attraction. I’d been attracted to pretty girls before, and I’ve been attracted since. This was not the same: there was more to it.
I can’t put my finger on it: maybe it was the expression on your face, maybe it was your pose, something in your body language. But it was there. And I saw it and knew straight away.
And I’ve never loved anyone the same way since. I don’t see it happening again.
I miss you.
I thought of one:
“Nova FM: We’ll make you want to strangle kittens much sooner than you thought possible”
In today’s installment of “Awesome Open-Source Software”, I’m going to talk about Teeworlds.
A screenshot:

This game is a brilliantly playable, amazingly addictive, and hugely fun blend of a 2D platformer (a-la Mario) and a multiplayer FPS (a-la Quake3 or Unreal Tournament).
It’s not complicated: It’s multiplayer only, there are only 5 weapons, and the levels aren’t big or expansive – you won’t spend long looking for your enemy, you’ll spend more time lobbing grenades at him, and then running away frantically because you’re out of ammo and/or low on health.
That’s if you’re playing with only a few others. If there are lots of people in the game, it’ll just be frantic carnage, like any good deathmatch.
It takes its cues from “proper” deathmatch games – the old run-and-gun style: cover systems and regenerating health are for sissies; precision aiming is for people who don’t know about splash damage. Standing still is a VERY BAD IDEA. None of this “modern FPS” crap. This is evidenced most starkly in the fact that you can double-jump, and, perhaps coolest of all, you have a grapping hook, which you can use to climb and to swing yourself to/from places very quickly. If you play in a busy CTF server, you’ll see just how effective the grappling hook can be – these guys are SO FAST!
And it’s gorgeous and has a great atmosphere: cartoonish graphics and sounds. The sounds really do it for me: the cutesy scream your tee will make when he’s hit in the face with a grenade makes it fun to die, the maniacal yet cartoonish laugh your character will emit when your opponent cops a grenade to the face. It’s a really really fun atmosphere.
And I mean that: this is one of those games which is so much fun that you rarely feel like ragequitting, even when you’re losing badly: you will get killed mercilessly and repeatedly, but you’ll have a big smile on your face during the shootout, and when you die you’ll laugh.
And it’s quite well-balanced: none of the weapons are over-powerful or ridiculously weak. This is probably helped by the fact that the weapons have (very) limited ammo, even though running out of ammo sometimes annoys me slightly.
Downsides:
TL;DR: Teeworlds is a really really fun and addictive game which cleverly combines cutesy graphics and 2d-platformer gameplay with the frantic action of a golden-age FPS. It’s one of the better open-source games out there. Go and buy it now! ![]()
[EDIT: antisol.org now runs a Teeworlds Deathmatch server! ![]() ]
]
rsync doesn’t work on the freerunner for some reason I can’t even be bothered investigating.
So I came up with this without even really thinking about it, googling, etc:
cd /destination/path;ssh user@host 'tar cv /source/path' | tar x
It’s when I do stuff like that without giving it a second thought that I feel like I’m justified in saying that I’m “familiar” with linux. I’ve achieved something since ~2005!
one could add a ‘z’ or a ‘j’ to the tar parameters for compression, but the freerunner’s CPU speed makes compression take longer than transferring the data uncompressed.
…it’s actually pretty easy: All you have to to is write an open-source emulator (OK, fine, “API Compatibility Layer”) for the worst piece of software in the history of mankind.
In case it’s not completely obvious at this point, I’m talking about WINE.
Wine is a piece of shit. The only reason I don’t rate it as “worse than windows” is that the wine devs don’t expect you to pay for their garbage, whereas Microsoft does.
No, wait, I don’t want you to misunderstand me, so I’ll clarify my statement: wine is a godawful piece of shit.
Legions of freetards will quickly jump to defend wine: They’ll tell me how I have no right to criticise the hard work of all these people who are giving me something for nothing, and they’ll talk about how well the wine team keep abreast of the latest developments and how they’re in an impossible situation because they’re aiming at a moving target and how Microsoft’s documentation leaves alot to be desired in terms of reimplementing the entire Win32 API.
And they do have a point – the wine devs are not trying to do something trivial.
But that doesn’t change the fact that wine is a piece of shit.
I won’t dispute that there are some talented people working on the wine project – I don’t even want to think about how complex such an undertaking is, but if you can’t even make things work consistently when somebody upgrades to a new version of your product, it’s a shit product, and you’re useless, not doing enough testing, and not managing your project properly. Keeping existing features working is more important than adding new features.
Keeping existing features working is more important than adding new features!
KEEPING EXISTING FEATURES WORKING IS MORE IMPORTANT THAN ADDING NEW FEATURES!
Wine suffers from a completely retarded number of regression bugs: something which works just wine in version X of wine may or may not work in version X+1. This is an absolutely ridiculous situation.
Apparently “STABLE” doesn’t mean what I thought it meant: I thought it meant “Working, Usable, and tends to not crash horribly in normal use”. But the wine team seems to think that “STABLE” means “This alpha feature is almost feature-complete and almost works. Mostly. Except when it doesn’t”. I can’t fathom the decision to mark Wine 1.4 as “Stable” with its redesigned audio subsystem which lacks a fucking pulseaudio driver! And the attitude they take is “pulse has ALSA emulation, so we don’t really need to support pulse” – a weak cop-out at best. I mean, it’s not like the majority of distros these days default to using pulse… Oh, wait…
Application-specific tweaking. Oh, the essay I could write on the bullshit required to make any particular application work. Here’s the usual procedure:
I can’t be fucked with any of this anymore, so here’s the process I use:
The most hilarious and entertaining part about all of this is the way that even after all my experiences which indicate the contrary, sometimes I still tend to assume that things will work under wine – after all, the wine mantra is “if it’s old, it’s more likely to work”. Here are some examples:
And now, some questions for the wine developers:
Now, to be fair, this is not all the fault of the wine devs – it’s also the fault of the people who manage repos for the various distros out there: these people should learn, and simply not upgrade the wine version in our repos until they’ve checked whether the fucking thing works or not – it’s a wierd kind of synchronicity that choosing a wine version is kind of like using Microsoft products: You never, ever, ever install the initial release, you wait for R2, when it might actually stand a chance of being something other than utter shit.
Wine sucks. It’s the worst piece of open-source code in the history of mankind. There are two factors why:
There is never a reason or excuse for breaking backwards compatibility other than laziness, and it’s therefore never acceptable to break backwards compatibility.
Wine is a piece of shit.
[EDIT: wine 1.5 is better than 1.4, but still not up to par with 1.2]
[EDIT 2: I'd really really love to hear an explanation of why opening a common dialog crashes metacity]
Derek Zoolander: “it doesn’t mean that we too can’t not die in a freak gasoline fight accident.”
– Zoolander
Randall Flagg: Pleased to meet you, Lloyd. Hope you guess my name.
Lloyd Henreid: Huh?
Randall Flagg: Oh, Nothing, Just a little classical reference.
– Stephen King’s The Stand (Miniseries)

Priceless.
You are such a fucking cunt. I hate you and I want you dead.
Regards,
-AntiSol
I require two things from the end of Breaking Bad:
I also have preferences – things which I’d like to see but don’t require:
Predictions:
In case it’s not really obvious, I’ve been re-watching season 5 of Breaking Bad today. IMHO this is one of the best shows ever made… but that’s a separate post, or a 100,000 word essay.
No, this is not an Ad. Brokenrules are not paying me!
Everybody raves about Braid. It’s clever, with unique game mechanics, and very pretty.
But it’s too short – by the time you wrap your head around a concept, you’re not using that concept any more.
I’ve read reviews praising this, saying that there’s no repetition and not a single “wasted” puzzle.
But you know what? For all my complaints in the past about games being too repetitive, I can handle doing a couple of variations on the same puzzle if it means it’s going to take more than a couple of hours to get through the game.
Don’t get me wrong – Braid is a brilliant game, and the people who came up with those game mechanics are really clever, and the art style is very pretty… but it’s too short – it needs more levels or some different playmodes. It has near-zero replayability.
And Yet It Moves is a much, much better game – easily the most original and fun game I’ve played in years.
This game is fucking awesome in every respect – the game mechanic is deceptively simple – rotating the world, but it gets progressively more challenging and clever about how it uses it.
The game is a good length – it took me longer than Braid did. And it has different playmodes and an “epilogue” set of levels which you can play after you’ve finished the main game which will keep you interested. And achievements are always fun.
And it’s absolutely gorgeous. The “paper” art style is magnificent, and goes through enough variations to always be interesting.
And the music is fantastic – very distinctive and unusual. There’s one particular piece of music which usually plays in-game (usually when you’re jumping onto disappearing platforms) which is especially awesome.
Linux is supported. Steam for Linux is supported. I got it as part of one of the Humble Bundles. It’s going for $10 on Steam right now. You should buy it.
I’m trying to think back to the last time I loved a game this much. It was a long time ago – I’ve been bored with games for a long time. I think that probably the last time I was this impressed with a game was the first time I played Portal.
Here, watch the trailer:
Go and buy this game right now. You want it, you just don’t know it yet (or maybe now you do!). It’s cheap. And it’s a seriously awesome, awesome game.
I wrote this a few days ago in the small hours of the night:
It’s the pub in a tiny town in the middle of nowhere. You and your friends are out-of-place here – there’s a bunch of rednecks fawning over you, none too subtly.
I can see why – you’re young, gorgeous, with long, dark, straight hair – just how I like it, and you’re wearing a tight, short, single-piece red thing that nearly takes me off my feet.
But these guys are cringe-inducing – really lewd and loud, and all stepping over eachother like a bunch of morons. It’s funny and pathetic to watch – the air carries the dual scents of sweaty testosterone and evaporating estrogen. I refuse to be involved – I’m reading a book and drinking a beer.
And then you sit down opposite me and say hi. You tell me that I look familiar. I say that’s unlikely, since I’m 3000kms from home. We introduce ourselves and chat a bit. You have an english accent – Oh my god, could this be love?
We’re chatting about nothing in particular. After a little while I decide to dispense with the pleasantries and ask a loaded question – one which says more than it asks:
“So, how do you like the blokes here? Subtle, huh? Must be interesting coping with that…”
You stare at me blankly.
“Huh? What do you mean?”
I LOL on the inside. Probably not love.
“Never mind”.
I get up from my seat and go talk to the blokes. It’s not hard for me to blend in with them – If I laugh with them they’ll think I’m one of them. And now I can join them in laughing at you.
miles on a motorbike in 22 hours ftw.
Yeah, I said miles.
I’ve just done more than 7000 kilometres in 12 days.
Hands up if you’ve crossed a continent on a motorbike, and then ridden back again.
<hand goes up>
I’ve been playing with the latest QTmoko on my freerunner after a couple of years of not updating my distro.
Some thoughts:
It’s great! Very snappy and responsive – congrats and thank-you to Radek and the other contributors, you’ve done a fantastic job and you’ve made some great strides over the last couple of years.
I haven’t tried using it as a phone yet (I’m still put-off by my previous experiences, and don’t have a second SIM), but it looks like it might be *gasp* almost usable! :O I’m tempted to try it out as a phone…
I particularly like what you’ve done with the keyboard – I think it’s about as good as an on-screen keyboard is going to get on this device. Very nice. though I wish I could have it default to qwerty mode.
But it’s not perfect – everything I want doesn’t “just work” yet (though it is very good – things like wifi and bluetooth seem to just work). But that means I get to have some fun tinkering!
I’ve been messing about with making foxtrotgps work under QX on qtmoko for a little while, and wanted to jot down some notes and tips:
I’m using ‘xrandr -o right’ for my landscape orientation. This means that the USB plug on the freerunner is at the top. If you want to use ‘-o left’ you’ll need to play around with the axis swapping.
I ended up doing the following to make a wrapper script for foxtrot. It’s a bit of a nasty hack, but it works for me. A slightly nicer way would be to use update-alternatives to use an alternate foxtrotgps launcher script, or saving the script as ‘foxtrot_launcher’, building a desktop entry for it, and setting up a QX favourite for it.
the script below could very easily be modified/generalised to run things other than foxtrotgps!
root@neo:~$ mv /usr/bin/foxtrotgps /usr/bin/foxtrotgps.bin
root@neo:~$ vi /usr/bin/foxtrotgps
(insert content, below)
root@neo:~$ chmod a+x /usr/bin/foxtrotgps
/usr/bin/foxtrotgps:
#!/bin/bash #Custom script for starting gpsd and foxtrotGPS in landscape mode: #xinput stuff liberated from: http://lists.openmoko.org/nabble.html#nabble-td7561815 #ensure GPS is powered up: om gps power 1 om gps om gps keep-on-in-suspend 1 #gpsd #service gpsd start gpsd /dev/ttySAC1 #sleep 1 # we might have to wait some time before sending commands (I didnt) #rotate: xrandr -o right #disable screen blanking: xset s off -dpms #swap x axis: xinput set-int-prop "Touchscreen" "Evdev Axis Inversion" 8 1 0 #no axis inversion xinput set-int-prop "Touchscreen" "Evdev Axes Swap" 8 0 xinput set-int-prop "Touchscreen" "Evdev Axis Calibration" 32 98 911 918 107 #run the matchbox keyboard in daemon mode: #with matchbox-keyboard-im this pops up automatically matchbox-keyboard --daemon & #run the real foxtrot: foxtrotgps.bin --fullscreen #foxtrot has closed, cleanup: #kill keyboard: killall matchbox-keyboard #unrotate: xrandr -o normal #stop gpsd: #service gpsd stop killall gpsd
Neil Armstrong has died.
It’s taken me a bit by suprise how emotional I am about it.
There’s so much to say, and yet so little.
The internet has been going crazy honouring him for a day or so now – as it should. Journalists and writers will do a much better job than I ever could at prattling on about what a loss this is and what a great man he was. Go to teh googles and do some searches and read about him, like you should.
I really only have a couple of things to say about it:
“Aw, Shit”.
Buzz Aldrin pointed out that he was looking forward to Neil being there for the 50th anniversay of the moon landing in 2019.
I think for me the biggest dissappointment is that Neil will never meet the next Neil Armstrong – the first man on Mars. That Neil never got to see humans exploring the solar system, he never got to see the real fruits of his accomplishment which I believe will inevitably come. I would have loved to hear what Neil would have had to say about man landing on Mars, or an orbiting hotel, or a moonbase.
“He will be remembered for all time”
He was one of those guys. I read the term “humble hero” somewhere, and it’s apt. He didn’t like publicity, he wanted to live a private, normal life. Kinda difficult when you’re the first man to walk on the moon. He was always deflecting the accolades onto the team, saying (I paraphrase):
“I just flew the thing – there’s half a million people who built the thing – congratulate them”.
I highly recommend “Being Neil Armstrong”, a very good BBC documentary about Neil which talks about how he didn’t like being in the spotlight.
There’s the “Futurama scenario”, where humanity forgets who first landed on the moon, but I think that it’s unlikely. Possible, but unlikely. I think we’ll remember Neil for as long as there is a humanity.
I was sitting at work today and another Armstrong thing came up on my news feeds and I got a bit bummed out. And I looked up and saw my James T Kirk Motivational Poster, and I had an idea – something appropriate and light-hearted. So I put it together tonight, here ’tis. I think it’s the kind of thing Neil would probably say… ![]()

(Note: I don’t know who to attribute this image to. It’s not mine.)

RIP. ![]()
(EDIT: Updated to add black border between images – makes it easier to see the 3d, and makes the 3d image better defined)
I hate those red-blue anaglyphs. The red and blue fucks with my head – my brain refuses to interpret it properly, and the object does this wierd “flashing” between red and blue.
Plus, I’m too cheap to buy (and too reckless to keep) a pair of those red-blue 3D glasses.
So, I installed Imagemagick and wrote myself a bash function:
stereo_convert () {
in="$1"
out="$2"
if [ -z "$in" ] || [ -z "$out" ]; then
echo -e "\nYou need to supply input and output files!\n"
return 42
fi
convert \( $in -gravity east -background Black -splice 10x0 -gamma 1,0,0 -modulate 100,0 \) \( $in -gamma 0,1,1 -modulate 100,0 \) +append $out;
echo -e "\nConverted red-blue stereo image '$in' to side-by-side image '$out'.\n"
}
Here’s a demo image from NASA’s Pathfinder mission.
Input:

Output:

Notes:
Though it would seem he’s vastly more capable at diplomacy-speak than I am:
Me:
“It’s very obvious to me that you don’t understand my question. Can I please talk to someone competent – someone who has some basic knowledge of networking?”
Vodafone Mobile Broadband Technical Support* consultant:
“No, you can’t: We’re an Internet provider, we don’t do networks.”
I was reminded later by a friend that the Internet is in fact a series of tubes. And here I was thinking it was a TCP/IP network. Silly me.
* I use the term “Technical Support” very, very loosely – I do not mean to imply that they provide support or are capable of being technical.
Sometime in the next 24-48 hours:
(defunct image http://allprojectstats.com/s2652978m15a.png removed)
That means there’s a 99.49424% chance that I’ve used more CPU time to look for aliens than you.
Stallman talks about Valve releasing a Steam client for Linux
Go, read. I’ll wait.
Back? Good.
Oh, Look! Valve got a mention by the mighty Stallman!
He asks what good and bad effects can Valve’s release of a Steam client for Linux have? Well, it might boost linux adoption, and that’s good. But…
Nonfree games (like other nonfree programs) are unethical because they deny freedom to their users. If you want freedom, one requisite for it is not having these games on your computer. That much is clear.
Wait, what?
Hang on a minute… If I want freedom, I’m not free to run these games? huh?
IMHO, having freedom means having the freedom to choose to run nonfree software if I want to. I’d rather play Half-Life or Portal than any open source game (It’s not that there are no great open source games, it’s just that Half-Life and Portal are better than all of them).
Stallman goes on to discourage Linux distros from offering the software to users – i.e deb packages for steam, and says:
If you want to promote freedom, please take care not to talk about the availability of these games on GNU/Linux as support for our cause.
Which is totally…fucking…insane.
I’ll be promoting freedom – freedom from Windows: “You don’t need windows anymore – Steam is available for Linux!”. I’ll be promoting the freedom to finally run good games on my chosen OS without any fucking around with wine. I’ll be (gasp) buying a bunch of games. Because a Steam client for Linux would be totally fucking awesome – I think it’d be the biggest event in gaming since Id released the source code for Doom. Just watch the Linux market share grow after the release.
Stallman says that Linux adoption isn’t the primary goal. That the primary goal is to bring freedom to users (But apparently not the freedom to run games they love). But I think that adoption of Linux at this point is more important than sticking to this (silly, BTW: nonfree != evil) principle – The more adoption we see, the more the community will grow, and the better the software will get. While this happens, more people will be exposed to Stallman’s (unrealistic) philosophy.
Stallman does concede that “My guess is that the direct good effect will be bigger than the direct harm”.
Direct harm? Really? I can finally delete that old windows XP partition, and you’re talking about Direct Harm? You think there’s anything at all bad about Valve’s monumental decision to embrace Linux?
You’re fucking crazy. Even distros that your foundation doesn’t endorse (Prepare to be amazed), like Ubuntu, go out of their way to tell the user that they’re about to install nonfree software. It’s always optional. It’s just been made easy because not everybody is as nuts as Stallman – some people, like me, actually want to use nonfree software. I should be free to do that, but apparently that’s not OK with the so-called “Free Software Foundation”. Apparently software should be free, but not people.
(Update: Late 2013: Valve refuse to give me a refund for the nonfunctional game Fez, in violation of Australian Consumer Protection Laws. They try to tell me that the laws don’t apply. I lodge a complaint with the ACCC and stop buying things on Steam. Maybe Stallman isn’t that nuts after all. No company can be trusted.)
(Update 2: 2014: The ACCC Sues Valve for violation of consumer protection laws. I love those guys.)
(Update 3: Jun 2015: Valve announces that they now allow refunds. This is because they’re really good, caring people, and has nothing at all to do with an Australian judge being about to hand out a $10,000/day fine)
(Update 4: comments disabled on this post due to spam bots following the link here from my squee when steam for linux was announced)
“and my baby’s so vane she can indicate the weather”
In mid-late 2011 my “fed-up-ness” with Gnome reached critical levels – it got to the point that Windows has been at for years: me sitting, staring at my screen in disbelief, screaming: “What, exactly, the fuck, are YOU DOING THAT TAKES SO GODDAMN LONG?!?!?!”, or the classic: “aah, good, a minute’s delay while you read something which you ALREADY HAVE CACHED!!!”.
I shit you not, there are tasks which gnome’s bloatware manages to slow down my dual-core >3000Mhz machine with >8000Mb of RAM to a point where performance is comparable to performing the same task on my 7Mhz, 2Mb RAM Amiga 600. This is not an exaggeration – for example, my Amiga will open up a directory containing thousands of files in a comparable time, and it’s reading from an MFM hard disk and has pretty much nothing cached. My Amiga will boot up in less time than it takes gnome to show me my desktop from the gdm login screen.
It’s not that Gnome changed or did anything differently, it’s just that I gradually became less and less tolerant of it’s godawful performance, and the point came where I finally snapped and said “Fuck Gnome”.
No, I haven’t tried Gnome 3. Given an option, I never will – the screenshots are enough to tell me it’s an ungodly abomination. I’m talking about Gnome 2.
The solution I went with was to switch to Xfce.
Since I’m addicted to my pretty wobbly windows, I’ve been running Xfce with compiz as the window manager on my powerful machine. I’m using xfwm on my less-powerful laptop.
I’ve been using it for a few months now, and thought I’d report on the experience.
So, without further ado, here’s an exhaustive list of features I miss from Gnome which are not in Xfce:
—BEGIN—
—END—
This also marks my departure from using the standard Ubuntu distro. I loved it and I wish the Ubuntu team well – 10.04 has been a brilliant OS – it’s served me really well and I’ve been very happy with it in general, but I’m not ever using unity, and next time I need to install an OS I’ll be going with Xubuntu.
Fuck Gnome. Fuck Gnome right in the ear.
Now all I need is for someone to build a web browser that doesn’t completely suck ass. Maybe I’ll give Opera a proper try…
“Having kids is hard”
“Having kids is such a chore”
“I don’t get any sleep anymore”
“I won’t have a life for 18 years. And then I’ll be too old to have a life”
These are just some of the more common of the whingy, bitchy things people who have just had kids say to me.
Here’s a thought: I don’t fucking care! Did I twist your arm and make you have kids? No. Did I tell you beforehand that they’re a fucking nightmare, and that you’re making a big mistake? Yes. Did you listen to me? No.
So why should I listen to you or care in the slightest when you come to me whinging about how your life isn’t your own anymore?
You made the mistake, not me. Deal with it. I don’t want to hear about it. I know that having kids is a hassle and a nightmare which changes everything – that’s why I don’t have any, and why I will never have any. It’s almost certain that I told you that you were making a mistake at a point where it was still a choice. You chose to have kids, So don’t fucking bitch to me about the consequences of your actions.
There’s only one thing worse than “My life is over now that I have kids”, and that’s hiding behind your kids because you’re too fucking gutless to say “No, I don’t want to”.
“Oh, it’s such a hassle to get the kids in the car, it’d be too much to manage – I can’t come to [kid-safe-event-I've-invited-you-to]“.
My ass. How do you manage to go shopping then? Ever been to a family dinner since you had kids? How are these things any different?
I find this whole premise especially amusing in that 99.999% of the time your kids are entertaining themselves with their game boy or TV or DS or whatever-the-current-fad-you-fell-for-is – it seems kinda strange to me that your kids can be completely unsupervised at home and yet require your constant attention the minute you leave the house. If that really is the case, which I really really doubt, then as an independent observer I’d speculate that perhaps they’re not being properly disciplined?
Here’s a simple, easy-to-follow set of instructions on how to get your kids in the car and to come to [kid-safe-event]:
Problem solved.
Secret tip: when your kids get unmanageable / unruly in public, screaming out “STOP THAT SHIT RIGHT NOW OR I’LL SMACK YOU ONE” works wonders. If that makes them cry, you can always use the good old chestnut: “SHUT UP OR I’LL GIVE YOU SOMETHING TO CRY ABOUT!”
Oh, what’s that? you still can’t come? Oh, right, well if you need to…uh… do your washing then that’s fair enough, I understand…
Liar.
Is awesome. This is what Isaac Asimov was talking about… well, not quite, but he’s certainly the best thing we have so far: the form is all there, now we just need a mind.
I’d just assumed he was named for Isaac, but he’s not – ASIMO is an acronym for “Advanced Step in Innovative MObility”. Still, I think Isaac would have shed tears of joy at the sight of him dancing.
I want one.
If I ask you a favour, I’m asking. It’s not mandatory.
If you’re not going to help me out, don’t waste my time with bullshit. Don’t tell me that you’re busy/don’t have time. Don’t tell me “Not right now, but I’ll call you back”.
Here’s a list of answers to “can you do me a favour?” that are perfectly acceptable, but that nobody ever uses because they seem to think that a bullshit answer is more acceptable than the truth:
The worst one is the “Sure, but not right now, I’ll get back to you”, because you have no intention of ever getting back to me, and when I hear “I’ll get back to you”, I stop trying to find someone and sit by the phone waiting for you to call (well, probably not literally, but I’ll put less effort into trying to find someone else).
Another thing: You don’t owe me an explanation. If you’re not going to do it, say “No”, and we’ll move on. Nothing more is required (except in certain circumstances, like if you owe me a favour, but none of this really applies in that situation).
Don’t bullshit me. Tell me the truth. If you ask me a favour and I’m not going to do it, I’ll say so. Probably rather bluntly. I expect you to be big enough to be able to handle the fact that I’d rather watch Terminator 2 for the ten thousandth time than help you with your problem. This is a courtesy. You should return it.
Many many years ago I came up with an idea for an xmas carol.
Years after I came up with the idea, I actually made it into A Song.
Now, for the last month of so, I’ve had an Idea for a second xmas carol.
But I’m too lazy to turn this into a song, especially in time for it to still be relevant.
So, here are the lyrics. It fits to the music of “we wish you a merry xmas”:
There’s still a whole month till xmas,
there’s still a whole month till xmas,
there’s still a whole month till xmas,
Fuck xmas in the ear.I can’t bear to hear
your fake xmas cheer
there’s still a whole month till xmas
So stick it in your ear.get out of your corporate mindset
get out of your corporate mindset
get out of your corporate mindset
I’ve had it up to hereI can’t stand the din
of your fucking caroling
There’s still a whole month till xmas
So stick it in your ear.your greed means you are the devil
your greed means you are the devil
your greed means you are the devil
there’s a paradox hereThe commercial appeal
has you under it’s heel
there’s still a whole month till xmas
Fuck xmas in the ear
I find myself constantly going to the OpenMoko USB Networking page to find the commands to enable iptables masquerading – it’s the only part of the process I can’t remember.
It’s a bit obscure to find on the USB Networking page, so now it’s here, too:
sudo iptables -I INPUT 1 -s 192.168.0.202 -j ACCEPT sudo iptables -I OUTPUT 1 -s 192.168.0.200 -j ACCEPT sudo iptables -A POSTROUTING -t nat -j MASQUERADE -s 192.168.0.0/24 sudo bash -c 'echo 1 > /proc/sys/net/ipv4/ip_forward'
1. Stop being a fucking retard.
…was, of course, in a flame – I’m at my best when I’m trying to insult or provoke someone.
This was years ago when I won an auction for a Commodore SX-64 on EBay. I’d managed to score it for somewhere around $250 (which is a really good price for that machine, it’s super-rare). The guy was really dodgy – he’d said he accepted COD in the ebay listing, but when I said I’d pick it up and pay cash, he said He’d meet me in a carpark rather than at his house, and wanted me to pay by bank deposit in advance.
I told him this was a very unusual way to do things, and that COD meant ‘cash on delivery’, and that I wasn’t paying by bank deposit, and what was the problem?
He replied telling me that he “Never carries around that much cash”…
…wait, what? I paid cash for my motorbike! And this guy never carries around $250?
He went on to explain that he was selling this machine on the sly, it was in storage somewhere and he didn’t want ‘the missus’ to go through his wallet and steal the cash.
Fair enough, I said, thinking to myself how I’m never ever getting married, then we’ll have to meet twice, because I’ll be seeing a demo of this SX-64 in action before I do a bank transfer.
No Reply.
A couple of days later, I get an email from ebay telling me that this guy’s account has been suspended due to fraudulent activity and that if I haven’t paid for my purchase yet, I shouldn’t. The plot thickens.
Not long afterwards, I get an abusive email from a different email address. It doesn’t say who it’s from (it’s a hotmail with a fake name – ‘john hancock’), and it doesn’t mention why I’m a “fucked faced motherfucker”, just that I am. There is no information content, just abuse.
I deduce that it’s this guy from ebay and that he thinks I was the one who reported him to ebay, so I reply, telling him that it wasn’t me who reported him but that I was glad I hadn’t done a bank transfer already.
I get back an abusive reply, and another, new piece of abuse from a new email address. The email headers have the same originating ip.
Here’s a nugget of that response, and my reply… which is just about the most awesome thing I’ve ever written:
>I KNOW MORE ABOUT YOU THAN YOU THINK
you know more than I think, do you? well that wouldn’t be difficult – my
expectations aren’t exactly stellar, but what if I think you know more
than you think I think you know? But then, we both know that you don’t
think much, much less know anything, and it’s much more likely that I’ll
think you know less than you think I think you know, and I’ll probably
be right… And we still haven’t even touched on what I know, or what
you think I know, or what I think you think I think you know. But then
I’m not the one sending abusive emails from two different addresses with
two different names but coming from the same IP. Thanks for the
confirmation on that, BTW.
—EOF—
And now the fun part – naming and shaming:
John Ath – pcgallery@hotmail.com
John Hancock – shimf66@hotmail.com
X-Originating-IP: [120.19.186.49]
When I buy petrol. There are 2 really basic principles why not:
1. Legal.
When I roll up to your petrol pump and lift the handle, if you turn that petrol pump on, you are agreeing to sell me petrol. By pouring petrol into my tank, I’m agreeing to buy it.
Any condition (for example: the condition that I take off my helmet when I enter your store) which is added to a transaction after I agree to make the purchase but before I hand over my money is pretty obviously an unfair condition of sale. Under Australia’s consumer protection laws, unfair conditions are meaningless. Therefore the condition that I take off my helmet before I enter the store is unenforceable.
If you don’t turn on the petrol pump while I have my helmet on, there’s no (legal) problem. Some places do this – you lift the handle, the pump doesn’t turn on. you look inside, and the guy behind the counter makes a motion as if he’s taking off a motorbike helmet. That’s perfectly fine – I’ll just go somewhere else based on principle #2.
If you have locked doors with a button behind the counter, and you won’t let me in the store with my helmet on, then you have a real problem. Because in that event, I will invoke my right under the Australian Consumer protection laws to change my mind about the sale – I’ll suddenly decide that actually I don’t want to buy petrol from you, after all. This presents you with a problem, because now you’ll have to remove the fuel that I pumped in – and *only* the fuel that I pumped in – from my bike. Good luck with that.
2. Moral.
I’ve worked in many client-facing roles. I’ve dealt with all kinds of customers, ranging from people at home calling up because their Internet is broken, right up to corporate executives. In my many customer-facing roles, and in fact one of the first things I was ever taught in my career, is the value of customer service. As someone who has had to provide customer service for a living, I pretty much insist on it when I’m the customer. And the first thing you’ll learn when you learn customer service is not to insult your customers.
By asking me to take my helmet off, you’re accusing me of being a thief. There’s no way to dance around it, it’s a simple fact – when you ask me to take my helmet off, you are very clearly implying that I am a thief.
And guess what? I consider that an insult. And if you insult me before I’ve handed over my money, I’ll go somewhere else, pure and simple.
“Oh, but the companies need to protect themselves! if they let you walk in wearing a motorbike helmet, then they’d get robbed all the time!”
Firstly, that’s not my problem, that’s a problem for the companies. Secondly, isn’t there an entire agency, widely referred to as “the police”, who deal with that kind of thing? Surely when you hand over the CCTV footage showing the thief’s number plate, the police will do their jobs, and no customers need to be insulted?
“Oh, well, these thiefs, they don’t use number plates, or they fake them…”
See the previous question. Now the police have multiple charges they can press.
“Yeah, but, we need to prevent crime!”
Then why do you let me pump the petrol into my bike with my helmet on? Assuming I’m a thief with fake number plates, why would you give me the opportunity to fill my bike up with petrol and simply ride away?
If you’re really interested in preventing crime, then guess what? There’s a whole industry sitting out there just waiting for your call! It’s called “The Security Industry”. There are companies like Chubb who make their entire living out of just that kind of thing! These guys are professionals who take their job seriously – they can advise you on best practices and whatnot, and they’ll provide whatever kind of security you like – The Security Industry can provide all kinds of wonderful services including but not limited to having a car drive past every so often, to make sure you’re OK, or permanently stationing a security guard (or, better, more than one) on site. If you like, the guards you have on site could probably even frisk every customer as they enter and leave the store! After all, I’m sure there are thiefs out there who are slipping through the cracks in your system because they’re not motorcyclists.
What this is really about is externalities – you can’t be bothered paying somebody to help you prevent crime (which indicates to me that it’s not really such a big problem), and you’d rather insult every single motorcyclist who comes to your store. After all, we’re only a minority…
You always see things like vmware and unreal tournament being installed via a self-extracting bash script – It would seem that this is the best way to provide an installer which will work on the widest selection of Linux distributions.
After some googlage, I came up with the following. Given a tarball and an installer script named ‘installer’, it will create a self-extracting bash script:
#!/bin/bash
#############################################################
# Self-extracting bash script creator
# By Dale Maggee
# Public Domain
#############################################################
#
# This script creates a self-extracting bash script
# containing a compressed payload.
# Optionally, it can also have the self-extractor run a
# script after extraction.
#
#############################################################
VERSION='0.1'
output_extract_script() {
#echoes the extraction script which goes at the top of our self-extractor
#arguments:
# $target - suggested destination directory (default: somewhere in /tmp)
# $installer - name of installer script to run after extract
# (if specified, $target is ignored and /tmp is used)
#NOTE: odd things in this function due to heredoc:
# - no indenting
# - things like $ and backticks need to be escaped to get into the destination script
cat <<EndOfHeader
#!/bin/bash
echo "Self-extracting bash script. By Dale Maggee."
target=\`mktemp -d /tmp/XXXXXXXXX\`
echo -n "Extracting to \$target..."
EndOfHeader
#here we put our conditional stuff for the extractor script.
#note: try to keep it minimal (use vars) so as to make it nice and clean.
if [ "$installer" != "" ]; then
#installer specified
echo 'INSTALLER="'$installer'"'
else
if [ "$target" != "" ]; then
echo '(temp dir: '$target')'
fi
fi
cat <<EndOfFooter
#do the extraction...
ARCHIVE=\`awk '/^---BEGIN TGZ DATA---/ {print NR + 1; exit 0; }' \$0\`
tail -n+\$ARCHIVE \$0 | tar xz -C \$target
echo -en ", Done.\nRunning Installer..."
CDIR=\`pwd\`
cd \$target
./installer
echo -en ", Done.\nRemoving temp dir..."
cd \$CDIR
rm -rf \$target
echo -e ", Done!\n\nAll Done!\n"
exit 0
---BEGIN TGZ DATA---
EndOfFooter
}
make_self_extractor() {
echo "Building Self Extractor: $2 from $1."
if [ -f "$3" ]; then
installer="$3"
echo " - Installer script: $installer"
fi
if [ "$4" != "" ]; then
target="$4"
echo " - Default target is: $target"
fi
src="$1"
dest="$2"
#check input...
if [ ! -f "$src" ]; then
echo "source: '$src' does not exist!"
exit 1
fi
if [ -f "$dest" ]; then
echo "'$dest' will be overwritten!"
fi
#ext=`echo $src|awk -F . '{print $NF}'`
#create the extraction script...
output_extract_script > $dest
cat $src >> $dest
chmod a+x $dest
echo "Done! Self-extracting script is: '$dest'"
}
show_usage() {
echo "Usage:"
echo -e "\t$0 src dest installer"
echo -en "\n\n"
}
############
# Main
############
if [ -z "$1" ] || [ -z "$2" ]; then
show_usage
exit 1
else
make_self_extractor $1 $2 $3
fi
…I feel dirty: My website is running somebody else’s code! :’(
but finally having something that actually passes for a real blog Is a good thing, I suppose.
Perhaps I will even write on it occasionally.
(Originally posted on myspace on 16-Sep-2008)
Here’s an example of unbiased and neutral journalism:
http://news.bbc.co.uk/2/hi/technology/7594249.stm
I find the fact that it’s on BBC somewhat strange, as I usually hold BBC to be one of the better commercial news sources.
Granted, their IT section is written by a bunch of clueless morons, but this just takes the cake.
Let’s analyse this article, shall we?
Firstly there’s all the mention of Linus torvalds, and how this guy is cursing his name. No mention of the fact that there’s actually thousands/millions of people developing Linux. the closest he comes is “made the heart of his operating system absolutely free and open source”, which is pretty close to the mark – Linus built the Linux Kernel, and it got plugged into the GNU operating system. Linus is responsible for only a small part of the entire OS, although it’s a major part.
Xandros worked right out of the box. Like most distros it includes Open Office, an open source copycat of Microsoft Office. Word processing, spreadsheets and presentations are no problem.
Xandros connected to the net through my home wireless network at the first time of asking. And surfing was fast and easy.
So, everything worked. Cool.
There were a couple of things about Xandros which I didn’t like.
The music management program – its “iTunes”, if you like – let me listen to music and podcasts on my new laptop but wouldn’t sync anything I loaded on to my iPod. Big problem for a music and podcast junkie.
Plus the desktop – the way the screen looks, the icons it uses to open programs – looks like it’s been designed by a four-year-old with a fat crayon. It’s may be down to personal taste, but I just don’t like the way Xandros looks.
Well, before I’d think about switching away from the preinstalled distro where everything works, by your own admission, I’d consider doing a couple of quick google searches. googling “Xandros Ipod” and “Xandros theme” immediately shows me 3 or 4 interesting links which would seem to warrant reading. and doing two google searches takes much less time than a) procuring and b) installing a new distro.
But linux is all about freedom, so you’re free to install a new distro, I suppose…
I’d also like to point out that if you don’t like the way windows looks, your options are to go and buy a Mac, or install Linux. I guess you could also go out and BUY a different version of windows, perhaps – i.e Upgrade from Home to Professional, although this probably won’t help with the look much.
Except now the internet wireless connection doesn’t work and the music management software still won’t let me sync with my iPod. Mmmmmm……
How is this any different to any other OS? Windows XP doesn’t recognise my wireless card or my UltraATA IDE controller – I Can’t install any version of windows except for a prepackaged XP SP2 on my machine, because without detecting the UltraATA controller, it doesn’t know about my hard drive. I’d call this slightly more serious than having no wireless connection or Ipod connectivity. Granted, in today’s internet-centric world no network connectivity is an issue, but did it not occur to you to try plugging a cable into your ethernet port as an interim measure?
Like most journalists, I’ve the attention span and patience of a gnat. The air turns blue and I inform my wife loudly that Linus Torvalds has much to answer for (I paraphrase slightly).
A gnat has more attention span if you didn’t even try plugging in an ethernet cable… and It’s obviously linus’ fault, and has nothing to do with canononical (who make and distribute ubuntu)…
But I’m completely stumped by the instructions posted on these sites. The level of assumed knowledge is way above my head. I follow a couple of suggestions, try to connect to my router using an ethernet cable, download code that promises to set things right. And fail.
It’s probably worth mentioning one other important point about Linux here. It’s a text-based operating system, which means that a fair few of the things you may want to tell your computer to do – installing certain new software, for example – requires you to open up a “terminal window” and actually type text into the little window.
As someone used solely to double-clicking on pretty pictures to do most anything on a computer this is pretty hairy stuff.
How is this ‘hairy’? somebody tells you to go into a terminal and type ‘X’, so you go into a terminal and type ‘X’. how is this difficult??? are you telling me that you’re unable to copy something that you see written down? you’re unaware of copy and paste? As a Journalist, I suppose, expecting you to type is just a bit too much…
True to form when I’m too stupid to figure out how to do something in five minutes, I phone an expert.
Geek Squad, a tech support service partnered with the Carphone Warehouse, is more used to dealing with problems with broadband and e-mail but later that night, Agent Jamie Pedder walks me through it over the phone.
Download a couple of bits of code from one of the Linux help sites on to a memory stick. Whack the memory stick into the offending laptop.
Bang a couple of lines of code into the terminal window to tell the machine to install what we’ve downloaded. Bingo, we’re cooking on gas.
Ubuntu’s running my wireless network and I’m back on-line. Easy when you know how.
So it works. Cool. So you got it all sorted out reasonably quickly. How is this different to Windows, where you need to install drivers? ever tried downloading windows drivers for your network card? it’s not easy, unless you have a spare working PC and a USB stick…
The fly in the ointment remains the music management software. I still can’t sync an iPod and Agent Pedder reckons that I probably won’t be able to – for now at least.
While Linux is founded on the philosophy of free and easy access to its code for anyone who’s interested, Apple is not. That means no iTunes for Linux, and nor is Apple likely to release such a version.
This, again, is obviously the fault of Linus Torvalds, and has nothing to do with Apple. It’s good to see you’re blaming the right people for your problem at least. Let’s just sum this up, for emphasis:
Yep, this is obviously because Linux sucks – I mean, expecting Apple to provide Ipod management tools for Linux is just asking for too much, isn’t it?
The iPod out of action is a major irritation, but I’ve not given up hope. There’s software out there – free for Linux users as always – that promises to do what I want. I just haven’t got round to downloading and playing with it yet.
So you’re reporting on how irritating it is, and how you’ve had a ‘torrid’ time with Linux, but you haven’t even bothered trying to install the software which will allow you to do what you want? Here’s a parable for you:
This is obviously an entirely fair observation on my part.
For the time being, it’s back to the trusty CD player. All this talk of hippy ideals has put me right in the mood for a bit of Sgt Pepper’s.
So your Ipod doesn’t work. Typing “ubuntu ipod” in google must be too hard, I guess – when I do that I see four links which would probably help, without even scrolling down.
So, to summarise: You bought a PC without windows, and it worked out of the box. You decided to install a different OS, and it broke. This is the fault of the OS, and has nothing to do with you being too lazy to do a couple of google searches to try to solve the things you don’t like about the working distro.
You were able to solve the problems, although you needed to call somebody to help you to do this, because you’re not able to follow instructions. I’m presuming this didn’t involve the 40 minute wait times or hideously excessive charges involved with Microsoft’s support line?
You bought an Ipod, which itself is an idiotic move – there are hundreds of MP3 players out there which present themselves as USB drives and are therefore supported natively by every operating system on earth without the need for any software at all, but you chose the one which requires special software and has ghastly DRM built into it, and this is Linus Torvald’s fault?
I see.
And believing in freedom makes you a Hippie?
I see.
I think you’ve stepped in some FUD, and it’s stuck to your shoe, and you’re now dragging it across my carpet. Take your shoes off, or get out of my living room.
(Originally posted on myspace on 20-Feb-2008)
Update: The only thing worse than a phone running windows? a Neo Freerunner. One day I might post a separate rant about that.
I’ve been using a HP iPAQ 6515 as my phone / mp3 player / GPS navigator / life support system for nearly 2 years now.
It’s a great little unit, in hardware terms – It’s got an SD card slot and a MiniSD slot, meaning you can give it a reasonable amount of storage space for playing MP3s. It’s a Quadband GSM mobile phone, so when I got it my old nokia 6210 got put in the cupboard. It’s got a builtin GPS receiver, and you can run TomTom on it. It’s (barely) powerfull enough to play MP3s and Run TomTom at the same time, which is nice, since I haven’t gotten around to putting a reasonable stereo in my car yet – I haven’t needed to. It’s a PDA, not a SmartPhone, meaning you can run a whole heap of Windows CE applications on it – My favorites are Voice Command, which is brilliant (when you’re in a quiet room, and you don’t have any contacts which sound even remotely similar to each other), and SCUMMVM, a cross-platform SCUMM engine, allowing it to run some of the most classic games ever: I’ve got Maniac Mansion, Indiana Jones and the Fate of Atlantis, and Monkey Island loaded onto mine. Best of all, it has a QWERTY keyboard, which is brilliant for txting – I hate the onscreen keyboards on the majority of PDA-type devices, and I don’t think I could live with a device which can’t atleast have a QWERTY keyboard attached to it.
It doesn’t have too many drawbacks: It lacks builtin Wifi, so I can’t run skype on it – the next model up (the 6965) has Wifi, but I couldn’t really justify spending $800 just for Wifi. You can buy an SD Wifi card for it reasonably cheaply, but the SD slots are in the side of the device, so a Wifi card would stick out the side and present a damage risk when you put it in your pocket (SD wifi cards neccessarily poke out of their slot, as they need space for an antenna, although there are compact ones available which aren’t as bad). It also lacks support for certain bluetooth services, namely high quality Audio – you can’t use stereo bluetooth headphones with it. This is kinda annoying, considering that the bluetooth software which comes with it says it supports high quality Audio. But the wired headset which comes with it is stereo and provides pretty good sound, if not eardrum-burstingly loud. Also the camera on it is not even worth using at 1.3 megapixels, and the HP Photosmart camera software is horrible. It suffices in an emergency, though. Unless the emergency happens at night – the “flash” on the thing is laughable.
Another disadvantage is the godawful Operating system it runs – Windows Mobile 2003SE. It’s slow and horrible – you have to wait a couple of seconds for windows to do it’s thing whenever you take the thing out of standby. And you have to reset it far more often than you’d ever turn a mobile phone off and on. I think that perhaps the slowness it merely related to it not having quite enough memory for my kind of usage – I run alot of programs on it above and beyond the standard Phone and Organiser functionality it provides. Maybe if I was a pleb user and didn’t load software onto it, or if it had more RAM, this wouldn’t be an issue.
I’ve looked into running a real OS on it, but the status of Linux support for this particular devce is not great – I’d probably have to live without access to GPS, the phone functionality may or may not work, the Camera wouldn’t work (pfft), and it could very well take a lot of hacking and mucking about to get linux onto the thing – there doesn’t seem to be any HOWTO for linux on this particular model of Ipaq, and I don’t really have the time and energy to figure it all out, especially considering that this is my phone we’re talking about – a day’s downtime would be unacceptable – I’d need another one to be able to play with to figure out what I’m doing.
but it’s certainly been a good little unit, I’ve thought… so far.
About a month ago, it stopped making noise except through the headset. Obviously what’s happened is that the switch in the headphone jack has become stuck in the ‘headset inserted’ position, which cancels all noise (and microphone input), except for the ringtone, from coming out of the unit’s speaker. I can still use it just fine with the headset plugged in, and I can still use it fine with the headset unplugged, just as long as I don’t want to do anything that requires audio input or output. Like talking on the phone. So at the moment when my phone rings, I have to scramble to find and untangle the headset, plug it in, and press the answer button.
So I contacted HP about this, wanting to know how to go about getting it serviced. I specifically made mention of the fact that this was my primary phone / communication method we’re talking about, so it’s pretty urgent.
I could go through the ensuing catastrophe of customer relations blow-by-blow, but then this would be 800,000 words long, and I would probably end up smashing something. And I’m using a work laptop at the moment, so that’s probably not a great idea. Suffice to say that they take up to a week to even reply to your emails, which you’ve market as urgent, and when they do it’s so unhelpfull that they might have well just kept playing Unreal Tournament, or whatever it is they do most of the time up there, rather than even replying. I just recieved an email yesterday, over a month since our last correspondence, which contained the exact same text as the previous email they sent me. Which I’d already replied to, over a month ago.
HP’s “support” team are without doubt the single most apathetic, indifferent, robotic, unhelpfull bunch of bastards I’ve ever dealt with. and I’ve BEEN an indifferent, unhelpfull tech support bastard before. But I at least used to try to project the appearance of caring about the customer’s problems – after all, it’s the company’s reputation at stake here. But HP’s “support” team doesn’t even seem to care about that.
It seems that HP are trying to sell Nokia products – a brilliant, novel, and innovative marketing strategy if I’ve ever seen one – There’s no amount of money Nokia could spend on advertising (short of having some cute chick giving blowjobs with every Nokia purchased) which would come close to what HP have done in terms of getting me to buy a Nokia handset.
After a couple of weeks of dealing with HP’s completely indifferent “support” team, I decided I’d just find myself an alternative device. It’ll cost me amaybe $1200 extra to do this, but at least I won’t have to deal with these pricks. I wouldn’t know what Nokia’s tech support people are like, because I’ve never had a problem with a Nokia product, ever. And I’ve used a few Nokia devices in my time.
It’s a good thing HP don’t make defibrillators or heart/lung machines.
So, congratulations HP – you’ve managed to ensure that I never buy another HP product as long as I live. You’ve managed to ensure that When I’m reviewing devices at work and making purchasing recommendations (which does happen), I don’t recommend the HP device, regardless of it’s technical specifications. You’ve managed to make the process of finding myself a new device less painfull – anything with a HP logo on it automatically gets excluded from my even looking at it,regardless of it’s capabilities. And most of all, you’ve managed to increase the yearly sales figures of one of your competitors. Whether that’s RIM, Palm, Nokia, Motorola, or somebody else I haven’t yet decided.
Congratulations, HP, and on behalf of Nokia, Motorola, RIM, and Palm: Thanks, HP.
(Originally posted on myspace on 14-Sep-2007)
(Original Article: http://www.abc.net.au/news/stories/2007/09/11/2029365.htm)
—————————————-
An Anti-Darwinian lobby wants new laws to Ban children under 16 from riding motorbikes, or from doing anything else which could possibly be classified as “fun”.
A three year old retard at quantong in Victoria’s west was killed last week when he rode his motorbike into the Wimmera river. This was obviously due to the malicious intentions of the motorbike, and had nothing to do with a) parents allowing a 3 year old to ride a motorbike b) parents not supervising 3yo while riding a motorbike c) parents not instructing their child properly on how to ride a motorbike, and the dangers of riding them into rivers d) parents allowing 3yo to ride a motorbike next to a river, with no intervening fence e) the kid being a moron f) Parents being morons.
Kidsafe victoria says more than five children a week are being admitted to hospital because their parents have not properly supervised them on motorbikes.
Kidsafe’s president Dr Mark Stokes says it is alarming motorbikes do not attract the same regulations as cars, which is somewhat strange, considering that Motorbikes and cars are actually subject to virtually identical laws, the only real difference being that a bike is more easily classified as a ‘recreational vehicle’ than a car, which seems sensible to anyone with a brain, because they ARE more often used as recreational vehicles. However he fails to point out that a car on private property also does not need to be registered, and is legally driveable by a three-year-old. exhibit A: the 10,000 ‘paddock bombs’ in australia, so this issue actually would actually also apply to cars, but the thing is that cars aren’t possessed by evil spirits which like to dump three-year-olds into rivers, and motorbikes obviously are…
He says Australia needs to adopt laws similar to those introduced in the USA, Where they don’t even have a helmet law. He says that if we brought in the Patriot act here, then kids would be too busy being stripsearched on the side of the road to go riding motorbikes around.
“Children just aren’t able to control heavy machinery like a motorcycle,” he said, sending anybody with a bike license and an IQ higher than 0.007 into fits of hysterics.
“When you look at the evidence about developmental skills in children, they’re really not able to ride and control something like that until they’re probably about at least 16 years of age,” Dr Stokes said, sending the Netrider and AMA forums offline for 2 hours due to the an inordinate number of posts containing text like “OMGWTFBBQ?!?” and “LOLLERCOASTER!!! THIS GUY’S FUCKED IN THE HEAD!!!”
“I had a motorbike between the ages of 5-9 years old, and I loved every second of it. I fell off a grand total of once that I can remember, and I think i may have bruised my arm during the fall, which was due to my attempting to do something stupid (jumping a Honda Z50R isn’t a clever move). I was heavily reprimanded by my parents for even trying to do stupid things, they explained that doing that kind of stuff on a motorbike is asking for trouble, and that they can be dangerous if you’re not carefull. and I never did anything stupid again. I hurt myself alot more on my BMX than on my motorbike, so maybe we should Ban BMX’s too. Oh, and don’t forget to ban kites – I heard that some guy once got struck by lightning when he was flying a kite in a thunderstorm, so they’re clearly very dangerous…”, Says AntiSol, someone who actually has half a brain.
“So This guy is saying that my 4+ years of loving my Z50R didn’t actually happen, and that I wasn’t actually riding it, cuz I was a child? or maybe I went through some strange “childhood” which actually ended at age 4, implying that I am a super-genius or something, cuz I’d swear to god I was riding that Z50 around like a champion at age 6… And since when is a 35kg Honda Z50R a piece of ‘Heavy Machinery’? My Lego set was heavier!”
“Look, If they take away my Kid’s right to ride his PeeWee around, then I’ll have no choice but to start teaching him insurgency tactics and bomb making – What else will he be able to do for fun? I mean you can’t even get a semiautomatic air rifle in this country! and now they want to take away junior’s PeeWee?!?”, said a Hells Angel who wished to Remain anonymous.
“I think it makes a farce of the whole notion of licensing for motor vehicles, if we are going to say need a license to drive a motor vehicle on a public road, but in a more dangerous environment you don’t need a license,” he added.
A survey of Australia’s Motorcyclists indicated that arroximately 870% chose “a tree or a river over an idiot commodore driver any day, in terms of safety. Trees and rivers don’t move. Or aim for you. If you ride a bike into a river, it’s because you were a fuckwit, not because the river cut you off. Plus grass is a lot softer to land on than bitumen, especially when the mack truck behind you is taken into account…”
(Originally posted on myspace on 03-Aug-2007)
HANEEF IS BAD!!! BAD HANEEF! HE’S BAD! BAD!!! BAD BAD BAD!!! BAD HANEEF! HANEEF IS BAD!!! HANEEF IS A BAD MAN!!! BAD MAN HANEEF! HE’S A BAD MAN! BAD! BAD! BAD MAN! HANEEF IS A BAD MAN! BAD!!! BAD BAD BAD!!! HE’S BAD!!! HE’S AN EVIL BAD MAN!!! BAD BAD! HE’S BAD! AND EVIL! BAD! BAD! BAD!
How do you know he’s bad? Because I said so! And I’d know these things! Like, I can’t tell you why, and infact I can’t even really tell you why I can’t tell you why, except to say that it’s for your own good. but trust me, He’s bad. You can trust me. I’m trustworthy. You know I’m trustworthy because I said so. I can’t actually prove I’m trustworthy, and I can’t tell you why I can’t prove it, but trust me, it’s all just for your own good. I don’t do anything that isn’t for solely your good and wellbeing, ever. And plus: he’s Bad. Haneef is a bad man. Don’t worry your little head that we dropped the charges and let him go in the end – that just means that we can’t actually PROVE he’s bad… but he is, Trust us, we know: He’s bad. Bad I tells ya. Bad. and evil. he’s a bad, evil person. You know it’s true because I would never lie… this has nothing to do with the election – there really is a threat – FEAR, FEAR!!! OOOH! BAD BAD!!! HANEEF = BAD!!! BAD!!! BAD! HE’S A BAD MAN!!! FEAR!!! FEAR!!! BAD!!! TERRORISTS! HANEEF BAD!! BAD MAN!!!
(vote for little johnny)
(Originally posted on myspace on 10-May-2007)
Looks like I forgot to post this when I wrote it…
(Original Article: http://www.abc.net.au/news/newsitems/200703/s1882231.htm)
I’ve translated this article from propagandese into english. Enjoy…
Rolling back WorkChoices ‘will send terrible signal’
The Prime Minister is celebrating the first anniversary of his Government’s WorkChoices legislation today. These celebrations will involve the usual consumption of ceremonial barrels of muslim blood and crude oil..
John Howard says the evidence is that the new laws have been beneficial with more than 250,000 20-hour-per-week casual jobs created over the past year, meaning a quarter of a million extra people needing a second job rather than being unemployed.
He told Radio National while he is open to finetuning of the workplace laws, they are a vital part of the economic reform process laid out by George Bush’s puppetmasters.
“The score card is very, very strong and if we roll back WorkChoices, which is what Labor will do if it wins at the end of this year, it will be
the first time in a generation that a major step towards the tyrannical, pseudo-democratic police state which I envision has been reversed,” he said.
“That will send a terrible signal to the millionaires in this country, and to millionaires abroad. It would be like saying ‘But you have 20 billion dollars already, that’s all you need’, which is obviously a terrible thing to say to a rich person…”
“The evidence is that WorkChoices has been beneficial. We’ve had what, more than a quarter of a million sub-minimum-wage jobs created, wages have continued to rise strongly for millionaires, and employees are so terrified that strikes are at their lowest level since 1913, so the scorecard is very, very strong… if you’re a millionaire…”
“And Anyway, anybody who doesn’t like the workchoices legislation has already been investigated as a terrorist, so we’re on top of it.”
Federal Workplace Relations Minister Joe Hockey says the WorkChoices legislation is working to add an eighth bathroom and olympic size swimming pool to his house.
He then went on to repeat word-for-word everything the prime minister said:
Mr Hockey says 263,000 new jobs have been created in Australia over the past year, and that of the people filling those roles, at least 3 or 4 hundred are able to survive comfortably, because they have two or more jobs.
He says strike action is at its lowest since records began. He attributes this to “a lengthly campaign of Fear, Uncertainty, and Doubt”
Mr Hockey says WorkChoices is one of the foundations of building a strong bomb-proof bunker in his backyard, so that he’ll be safe when the rampaging hordes come looking for blood.
“It is about a choice on whether people on AWAs or collective agreements, or those on the award system, it is about choice and certainly the evidence points to the fact that people who work in parliament house and are on AWAs earn more than people on collective agreements, on the award system, or the dole” he said.
(Originally posted on myspace on 14 Mar 2007)
I direct you to http://www.abc.net.au/news/newsitems/200703/s1871034.htm.
Sydney planes targeted by laser pointers
OMGWTFBBQ!!!Pilots have told aviation authorities they were targeted over North Ryde on Monday evening.
“It was terrible, I was trying to focus on the altimeter and a little red dot appeared on it! I’ll need at least 4 months of paid stress leave…”
A spokesman for Federal Transport Minister Mark Vaile says about 20 laser attacks on planes have been reported across the country.
Yep, and given that there are hundreds of flights all over the country on any given day, and the staggering number of crashes / injuries / strained eyes reported as a result, it’s obviously a problem of epidemic proportions, and therefore is wholly worthy of it’s very own news article in the national press.
The Federal Government has expressed concern that terrorists could use the technology to endanger passenger planes.
Ok. Seriously, you guys… Terrorists firing laser pointers??? I mean, how desperate do you have to be to try to instill fear into your population? and how GOD DAMN STUPID do you think your population is if you’re going to try feeding them this UTTER CRAP? I mean, what are the terrorists going to do, set up a network of 25 guys strategically located around the city so that they can shine their laser pointers at the pilot, forcing him to turn the plane, thus coming into the firing range of the next guy with a laser pointer, and using this method you ‘remote control’ the plane into a building??? as if! surely rocket launchers aren’t THAT hard to come by…? Surely it’d be easier to BUILD YOUR OWN WMD than to:
a) plan this
b) set up the 25 guys with their laser pointers, deck chairs, tripods, binoculars, synchronised watches, incredibly detailed plans of the plane’s flight path, etc
c) Train and then coordinate all 25 guys
d) find a target in Australia worth your trouble
Reasons why I wouldn’t be overly concerned:
1) I’d imagine it’s somewhat hard to aim a laser pointer at a plane, much less at the pilots eye, while it’s flying through the air at 400kph at 30,000 feet… Even while it’s landing (going slower, flying lower), I’d still say it’s going to be more difficult than…say…aiming a heatseeker…
2) So, on the off-chance that the terrorist does manage to get his pointer(s) – presumably two – most people have two eyes – into the pilots eyes REAL GOOD, so that the pilot can’t land – the pilots abort their landing, and wait a while before making another attempt. Where’s the issue? It’s standard procedure to overfuel planes in case of emergency – isn’t this exactly the kind of reason why they overfuel the planes? It’s not like they’re instantly gong to drop out of the sky if you don’t land at the scheduled time… if this is practicable in anything less than 99% of flights, I’d be seriously worried about getting on a plane without any of these important terrorist concerns…
3) The obvious reason: THERE IS NO TERRORIST THREAT TO AUSTRALIA.
But Civil Aviation Safety Authority spokesman Peter Gibson believes it is more likely that thrill seekers are responsible.
This guy has an exciting life, if shining a laser pointer at a plane is ‘Thrill Seeking’… far more thrilling than building dynamite, putting coins on train lines, planning political assasinations, or even going very very fast down the highway. I’m glad this guy is so hooked into today’s youth culture, saves me from having to keep my finger on the pulse…
“It certainly does seem this is just people who are pretty stupid, who think this is the interesting or fun thing to do,” Mr Gibson said.
“The message is it’s not interesting or fun, it’s damned dangerous and they should simply stop.”
“Damned Dangerous”?
“Damned Dangerous”???
“Damned Dangerous”???
If a professional airline pilot, who neccessarily has a rather extensive set of qualifications, not least including a full-on pilots license which means he has hundreds of flight hours and allows him to fly a many-many-ton commercial passenger aircraft, isn’t able to fly his plane with one eye closed, or isn’t able to move his head two centimeters to the left to avoid a laser pointer, and can’t ask his copilot for help, and can’t say “oh there’s a red dot in my eye, I’d better abort the landing and let the flight controller or copilot help me”, I’d be even more worried about flying, even without the nonexistant terrorist threat.
Oh no… I just realised that Now I’ve written this, I’ve at least doubled the amount of mental effort spent on this subject… eeeeeeeeeeeeeeeeeeeeeeeew, I feel so tainted…
(Originally posted on myspace on 17 Nov 2006)
So, This has been in my head for a long time, but this is the first time I’ve actually written it down. I’ve discovered a way to logically show that the beliefs of christians are wrong. These thoughts are probably not original and infact are probably thousands of years old, because to my mind they’re obvious, but I’ve never seen them written down anywhere, so here goes…
My line of thoughts are based on the following premises:
1. Christians claim their god to be omnipotent: “all knowing, all powerfull”.
2. Christians claim that sin exists in the world.
Now, laying out the premises like that, the incongruency jumps straight off the page and right into my face, but it might not for everybody, so lets go through some thought excercises in order to make our point:
* Just to be clear, “all knowing, all powerfull” means that god knows everything, and can do anything he wants (i.e affect physical reality in any way he desires) merely by wishing it.
* Let’s be more clear on the “all knowing” bit, because this is where the issue lies: Any entity which is “all knowing” neccessarily knows EVERYTHING. Including, by definition, everything that’s going to happen in the future.
* This immediately creates issues for anyone who believes in free will, because if god knows what’s going to happen in the future then man can have no free will, but if god doesn’t know what’s going to happen he’s not All knowing and the christians are wrong, which would bring out thought excercise crashing to an end. But let’s continue anyway…
* The Free Will issue opens up a whole seperate line of discussion, and it’s messy. A form of free will might be able to exist and still allow an omnipotent god, but only if the many worlds interpretation is correct, and in this case an omnipotent god would still be able to forsee the future of our reality by simply navigating probability streams to find the most probable future (which would presumably be that of our reality). so in this case, god wouldn’t know the future, because it would be impossible to know for sure, but he would know each possible future and it’s relative probability of occuring. For our purposes – because this thought introduces mind-bending paradoxes, and because we want to be generous and give christians the benefit of the doubt, we’re going to assume as far as we can that the christians are right, that god is infact all knowing, and that therefore man has no free will.
* Now, assuming that god is all-knowing and can see the future, and that genesis is to be taken literally, god created man, put him in the garden of eden, and said “don’t eat that fruit of knowledge”. However any omnipotent god would have known before giving the instruction that he would be disobeyed. Therefore the only logical conclusion I can see is that any omnipotent god intended for his instruction to be disobeyed, otherwise he would have either created a creature which would have listened, or not created the tree of knowledge, or not allowed the snake into eden to tempt man, etc etc etc… basically if the christians are to be taken seriously then it was god’s will for man to disobey him, so it’s not sin as it’s not against god’s will. Either that or he’s not all-knowing.
* So at this point we are left with two mutually exclusive possibilities: 1: That god can’t see into the future and therefore is not all-knowing and therefore christianity is wrong, or 2: That god intended for man to do everything he has done (and will do), in which case nothing you could ever do would be a sin, as it’s not against god’s will, and christianity is wrong.
so, as you can see: Christianity is wrong. Thanks for stopping by.
Now, the only remaining question is whether we call the unified, non-christian humanity which must now inevitably be created the “Allied Atheist Alliance”, “United Atheist Alliance”, or “Unified Atheist League”…
Sometimes
is never quite enough:
If you’re flawless,
then you’ll win my love…
Don’t forget to win first place,
Don’t forget to keep that
smile on your face.
Be a good boy,
Try a little harder:
You’ve got to measure up,
make me prouder.
How long
before you screw it up?
How many times do I have to tell you
to hurry up?
With everything I do
for you,
The least you can do
is keep quiet.
Be a good girl
You’ve gotta try a little harder,
That simply wasn’t good enough
To make us proud.
I’ll live for you,
I’ll make you what I never was,
If you’re the best,
then maybe so am I,
Compared to him
compared to her,
I’m doing this for your own damn good,
You’ll make up for what I blew,
What’s the problem?
why are you crying?
Be a good boy,
Push a little farther now:
That wasn’t fast enough
To make us happy.
We’ll love you
just the way you are…
…if you’re perfect.
-Alanis Morrisette
I fucking love this song. It’s so subtle and beautiful. I wonder what percentage of the millions who bought this album knows what it’s about? and what percentage skips it because it’s soft and slow?
They’re missing out, bigtime…
(originally posted on myspace on 19 Oct 2006)




{kind=link}